業界の最新動向をチェック
エリアマーケティングラボ
ノウハウ
GIS×予測モデルで出店判断の精度が変わる エリアデータ・人口データを「説明変数」に使う実践ガイド
2026/06/03
「予測モデルを試しに作ってみたが、精度がいまひとつだった」
こうした声を聞くとき、原因のほとんどは同じところにあります。売上実績・曜日・天候といった「手元にあるデータ」だけで予測モデルを組んだ結果、最も重要な変数が抜け落ちているのです。
多店舗チェーンの売上は、立地の「場所の力」に大きく左右されます。同じチェーン・同じ業態であっても、商圏内の人口規模、昼夜間の人の動き、競合の位置、周辺施設の構成—こうした「エリアの特性」が売上に与える影響は、曜日や天候の比ではありません。
この「場所の力」をデータとして捉え、予測モデルの説明変数に組み込む手段がGIS(地理情報システム)です。本記事では、GISとエリアデータを活用することで予測モデルの精度がどう変わるのか、その実践的な方法と考え方を解説します。
目次
- なぜエリアデータが予測精度を高めるのか
- 売上の「場所による差」をデータで説明する
- 「業態と商圏の相性」を定量化する
- 予測モデルに組み込むべき「エリア系説明変数」の全体像
- 人口系データ—最も基礎的で影響度の高い変数群
- 競合・施設系データ—「周辺環境の構成」を数値化する
- 地理・空間系データ—「物件そのもの」の特性を数値化する
- GISデータを予測モデルに組み込む実践的な4ステップ
- ステップ1:商圏を定義する—「どの範囲のデータを使うか」を決める
- ステップ2:商圏内のエリアデータを取得・集計する
- ステップ3:既存店データ×エリアデータでモデルを学習させる
- ステップ4:新規候補地のエリアデータを当てはめて売上を推定する
- GIS×予測モデルで解決できる5つの経営課題
- 課題➀:出店判断の根拠を「感覚」から「データ」に変えたい
- 課題➁:担当者が変わるたびに「出店の勝ちパターン」がリセットされる
- 課題➂:全国に散らばる候補地を効率的にスクリーニングしたい
- 課題➃:消費財メーカーとして「どのエリアの得意先に注力すべきか」判断したい
- 課題➄:人口減少エリアの既存店を今後どうするか判断したい
- エリアデータ活用における2つの重要な注意点
- 注意点➀:データの更新頻度と「鮮度」を確認する
- 注意点➁:モデルの「学習データ」の質と量を確保する
- まとめ—「場所の力」をデータにすることが、予測精度を変える
- 技研商事インターナショナルのGIS×データソリューション

なぜエリアデータが予測精度を高めるのか
売上の「場所による差」をデータで説明する
まず、次のような状況を想像してください。同じ飲食チェーンの2店舗—A店は月次売上1,200万円、B店は月次売上600万円。この2倍の差はなぜ生まれているのでしょうか。
店長の能力の違い、オペレーションの差、メニューへの工夫—もちろんこうした要因も関係しています。しかし多くの場合、最大の要因は「立地の違い」、つまり商圏の特性の差です。A店の周辺にはオフィスが集積しており昼間人口が多い、B店は住宅街で居住者向けの業態とはニーズが合っていなかった—こうしたエリア起因の差を説明変数として取り込まなければ、予測モデルは本質的な精度に達しません。
GISを使ってエリアデータを取得・整備し、予測モデルの説明変数として組み込むことで、この「場所による売上の差」をモデルが学習できるようになります。結果として、新規候補地に対する売上推定の精度が大幅に向上します。
「業態と商圏の相性」を定量化する
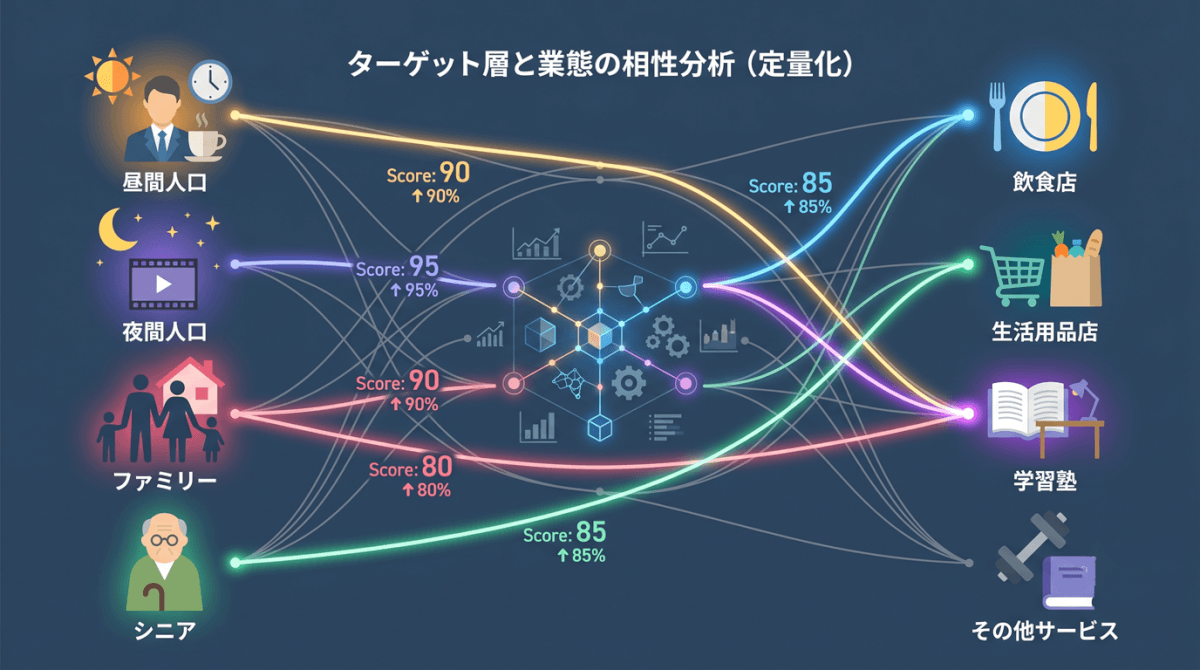
予測モデルにエリアデータを加えることのもう一つの重要な効果が、「業態と商圏の相性」の定量化です。
- 昼間人口が多いエリアで売上が高いチェーン → 就業者・通勤者向け業態
- 居住人口(夜間人口)が多いエリアで売上が高いチェーン → 生活密着型業態
- 子育て世代(30〜40代・子ども人口)が多いエリアで強いチェーン → ファミリー向け業態
- 高齢者比率が高いエリアでも健闘するチェーン → シニア向け業態
モデルが「変数重要度」を出力することで、自社チェーンの売上を決定づけている商圏特性が明確になります。これは新規出店の候補地スクリーニングだけでなく、「どんなエリアに強いチェーンか」という戦略的な自己理解にもつながります。
予測モデルに組み込むべき「エリア系説明変数」の全体像
エリアデータと一口に言っても、その種類は多岐にわたります。予測モデルの目的(出店判断・需要予測・配荷優先度 等)に応じて、どのデータを優先的に取得・活用するかを選ぶことが重要です。
人口系データ ー 最も基礎的で影響度の高い変数群
| データ種別 | 内容 | 活用が有効な業態・場面 |
|---|---|---|
| 居住人口 (夜間人口) |
商圏内に居住する人口 | 食品スーパー・ドラッグストア・クリーニング・塾など生活密着型業態全般 |
| 昼間人口 | 就業・通学などで昼間に滞在する人口 | 飲食チェーン(ランチ)・コンビニ・カフェ・オフィス立地型店舗 |
| 年齢別人口構成 | 商圏内の年代分布(10歳刻み等) | ターゲット年齢層の濃淡によって需要ポテンシャルが変わるすべての業態 |
| 世帯数・世帯構成 | 単身世帯・ファミリー世帯の比率 | 冷凍食品・単身者向け商品・ファミリー向け商品の需要予測 |
| 将来推計人口 | 5年後・10年後・20年後の予測人口 | 長期出店戦略・商圏の将来収益性評価 |
| 子ども人口 (15歳未満) |
学齢期の子どもの数 | 学習塾・スポーツスクール・子ども向け業態 |
| 高齢者人口 (65歳以上) |
シニア層の集積度 | 介護・医療・シニア向け商品・バリアフリー配慮業態 |
昼間人口と夜間人口、なぜ「両方」が必要か
業態によって、「誰が買うか」が大きく異なります。そのため、昼間人口だけ、あるいは夜間人口だけを変数に使うのでは不十分なことが多く、両方を取得したうえで業態特性に合わせて重み付けすることが精度向上の鍵です。
たとえば24時間営業のコンビニエンスストアであれば、昼間人口と夜間人口の両方が売上に関係します。一方、夕方から夜のピークが中心の居酒屋チェーンであれば、夜間(居住)人口に加えて、夕方の帰宅動線上の通過人口が重要な変数になります。
競合・施設系データ—「周辺環境の構成」を数値化する
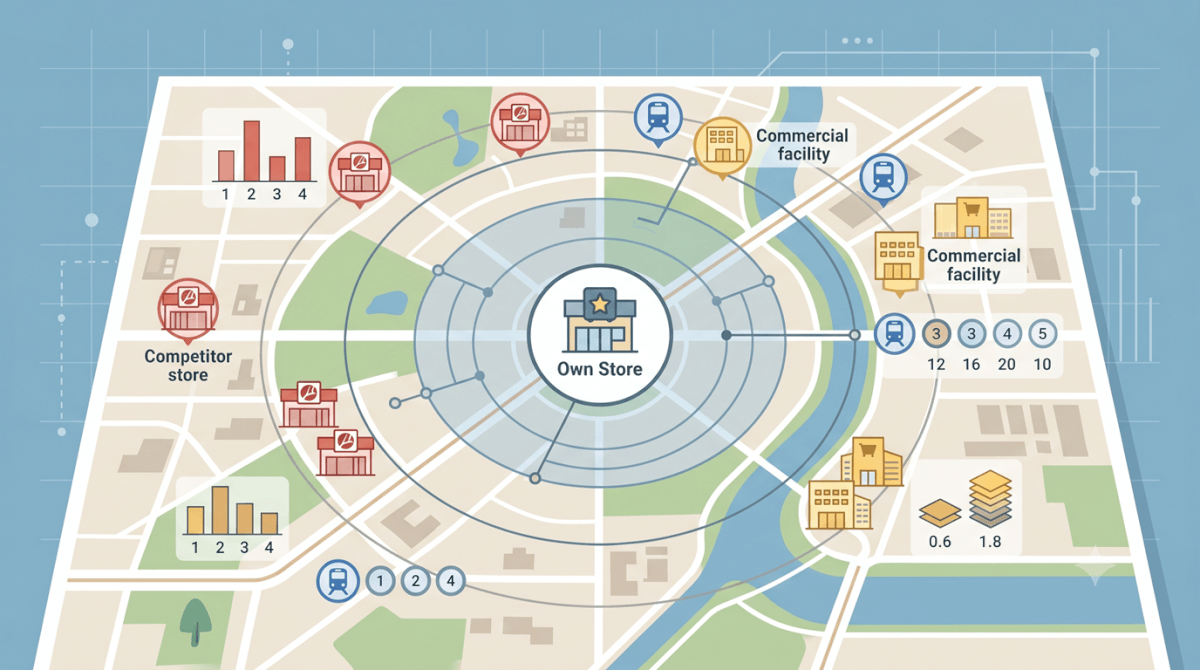
| データ | 内容 | 活用場面 |
|---|---|---|
| 競合店舗数・位置情報 | 同業態・類似業態の店舗数と位置 | カニバリゼーション予測・競合環境の厳しさの評価 |
| 競合最近接距離 | 最も近い競合店までの直線・道路距離 | 競合の影響度の変数として。近すぎると売上が抑制される傾向 |
| 商業施設・集客施設 | 周辺のショッピングモール・スーパー・ホームセンター等の位置と規模 | アンカーテナント効果・集客の相乗り効果の評価 |
| 医療施設・教育施設 | 医療施設・教育施設 病院・学校・保育園・大学等の位置と規模 | 特定ターゲット層の集積度。塾・薬局・子育て関連業態に特に有効 |
| 駅・バス停 | 最寄り駅の乗降者数・バス停の系統数 | 交通アクセスの利便性の定量化 |
| 道路・交通量 | 前面道路の車線数・AADT(年平均日交通量) | ドライブスルー・ロードサイド型店舗の評価に必須 |
地理・空間系データ—「物件そのもの」の特性を数値化する
| データ種別 | 内容 | 活用場面 |
|---|---|---|
| 物件面積・形状 | 店舗の延床面積・間口・奥行き | 規模に応じた売上ポテンシャルの正規化 |
| 駐車場台数 | 自走式・機械式の台数 | ロードサイド型業態の集客力評価 |
| 視認性・角地フラグ | 道路からの見えやすさ・角地かどうか | 通過客への訴求力の評価 |
| 標高・地形 | 丘の上・低地・商業地域等 | 洪水リスクや地形的な集客制約の評価 |
GISデータを予測モデルに組み込む実践的な4ステップ
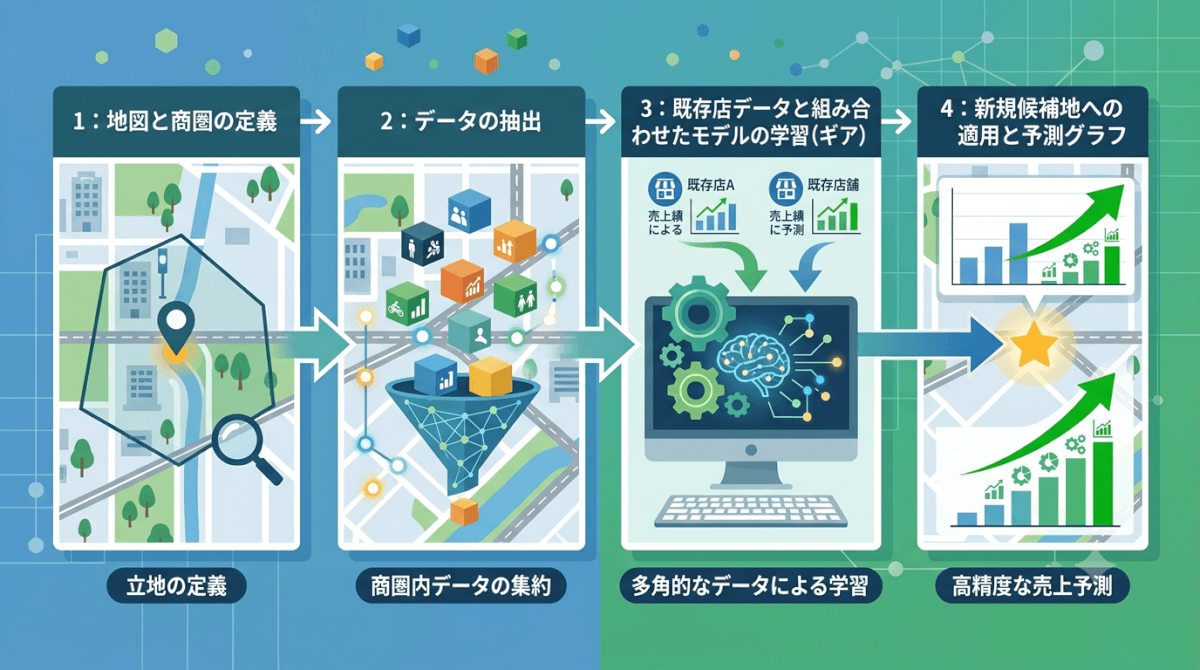
エリアデータをどれだけ豊富に集めても、それを予測モデルに正しく組み込まなければ精度は上がりません。ここでは、実務でGISデータを予測モデルに活用するための具体的な手順を解説します。
ステップ1:商圏を定義する—「どの範囲のデータを使うか」を決める
最初に決めるべきことは、予測に使う「商圏の範囲」です。同じ候補地でも、商圏をどの範囲に設定するかによって、集計される人口・施設数が大きく変わります。
代表的な商圏設定の方法
- 直線距離圏(円形)
店舗を中心に500m・1km・2kmの円を描く。シンプルだが、道路状況や地形を考慮しない
・徒歩・車の移動時間圏
徒歩5分・10分、車5分・10分の等時間圏(アイソクロン)。実際の顧客の移動実態に近い
・行政区単位
市区町村・町丁目単位で集計。既存の統計データとの接続がしやすい
・メッシュ単位
500mメッシュ・1kmメッシュ単位で集計。GISデータの基本単位として広く使われる
業態によって適切な商圏設定は異なります。徒歩来店が主体のコンビニは500m〜1km圏、車来店が多いロードサイド型は5〜10分車圏が一般的な設定です。
【重要な注意点】
商圏設定は予測モデルの精度に直接影響します。既存店舗の実際の顧客来店データ(顧客住所・購買データ)があれば、実態に基づいた商圏設定が可能です。データがない場合は業態の一般的な設定から始め、モデルの精度検証を通じて最適な範囲を探っていきます。
ステップ2:商圏内のエリアデータを取得・集計する
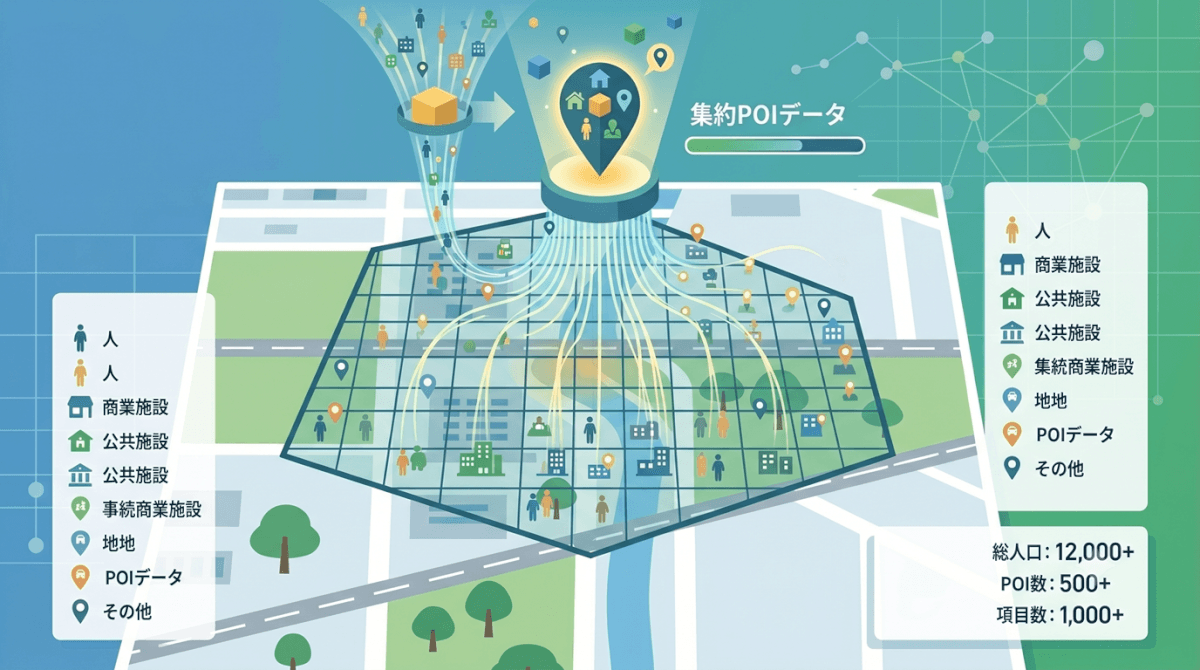
商圏が決まったら、その範囲内のエリアデータを取得・集計します。
人口データの取得と集計
国勢調査の基本集計データ(500mメッシュ・1kmメッシュ単位)を使うことが多いですが、更新頻度が5年ごとのため、最新の人口動態を反映したい場合は民間の推計人口データや人流データ(滞在人口データ)の活用が有効です。
特に「昼間人口」は国勢調査での取得が難しく、モバイル端末の位置情報を集計したビッグデータが精度の高いデータソースとして活用されています。KDDI Location Analyzerはこうした実態に近い昼夜間人口データを提供しており、予測モデルの説明変数として直接活用できます。
施設・競合データの取得
POI(Point of Interest)データ(施設の位置情報データベース)を活用して、商圏内の競合店舗数・距離、医療・教育施設の数を集計します。GISソフト上で「商圏内のポイントカウント」「最近接施設までの距離計算」を行うことで、数値として取り出せます。
ステップ3:既存店データ×エリアデータでモデルを学習させる
取得したエリアデータを既存店舗の売上実績データと組み合わせ、予測モデルを学習させます。この作業が、GISデータ活用の核心です。
学習データの構造(イメージ)
| 店舗ID | 月次売上 | 商圏内居住人口 | 商圏内昼間人口 | 競合店舗数 | 最寄駅乗降客数 | 物件面積 | 30-40代 |
|---|---|---|---|---|---|---|---|
| A店 | 1,200万円 | 32,000人 | 18,500人 | 2店 | 45,000人/日 | 85㎡ | 28% |
| B店 | 600万円 | 15,000人 | 4,200人」 | 0店 | 8,000人/日 | 72㎡ | 22% |
| C店 | 950万円 | 24,000人 | 21,000人 | 1店 | 62,000人/日 | 95㎡ | 31% |
このような形式の学習データを既存店舗の数だけ用意し、ランダムフォレストやXGBoostなどのモデルに学習させます。モデルは「どの変数が、どの程度売上と相関しているか」を自動的に学習します。
変数重要度の確認
学習後、モデルが出力する「変数重要度(Feature Importance)」を確認します。ここに御社チェーンの「売上を決める立地要因のランキング」が現れます。「商圏内昼間人口が最も重要」「次いで最寄駅乗降者数」「競合店舗数の影響は予想より小さかった」—こうした知見は、今後の候補地スクリーニング基準の見直しにも役立ちます。
ステップ4:新規候補地のエリアデータを当てはめて売上を推定する
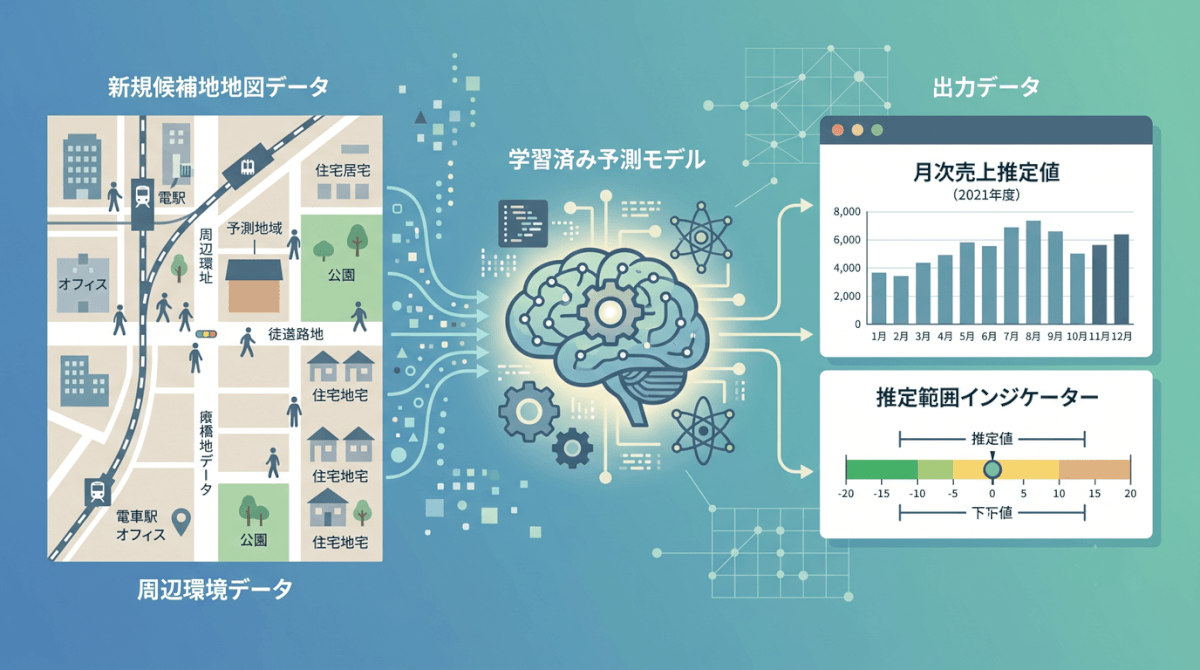
学習済みのモデルに、新規候補地のエリアデータを投入することで、売上の推定値を算出します。
候補地の売上推定フロー
① 新規候補地の住所・座標を確定
↓
② GISで商圏を設定・可視化
↓
③ 商圏内の人口・施設データを集計(エリアデータの取得)
↓
④ 学習済み予測モデルにデータを投入
↓
⑤ 月次売上の推定値(例:推定800万〜1,050万円)を出力
↓
⑥ 複数候補地の推定値を比較・優先順位付け
複数の候補地に対してこのフローを実行することで、「候補地Aの推定売上:950万円、候補地Bの推定売上:720万円、候補地Cの推定売上:1,100万円」という形で、同一基準での客観的な比較が可能になります。
GIS×予測モデルで解決できる5つの経営課題
実践的な手順を踏まえたうえで、GISと予測モデルの組み合わせが特に効果を発揮する経営課題を整理します
課題①:出店判断の根拠を「感覚」から「データ」に変えたい
課題の実態
出店可否の判断会議で「数字の根拠」を求められるが、担当者の定性評価しか示せない。社内承認のたびに根拠の薄さを指摘される。
GIS×予測モデルによる解決
エリアデータに基づく売上推定値を根拠として提示できるようになります。「この候補地の商圏特性は、当社の既存成功店舗群と類似しており、推定月次売上はXX〜XX万円の範囲に収まります」という、データに裏打ちされた提案が可能です。
課題②:担当者が変わるたびに「出店の勝ちパターン」がリセットされる
課題の実態
ベテランの店舗開発担当者が退職・異動するたびに、長年培った立地評価のノウハウが失われる。後任者が一から経験を積むサイクルが繰り返されている。
GIS×予測モデルによる解決
既存店舗の実績データとエリアデータから学習した予測モデルは、いわば「組織の立地評価ノウハウのデジタル化」です。担当者が変わっても、モデルは同じ基準で候補地を評価し続けます。
課題③:全国に散らばる候補地を効率的にスクリーニングしたい
課題の実態
商業施設のデベロッパー・不動産会社から月に数十件の物件情報が届くが、すべてを精査する工数がない。重要な候補地を見落とすリスクもある。
GIS×予測モデルによる解決
物件情報(住所・面積等)が入手できた時点で、エリアデータを自動取得してモデルに投入し、売上推定スコアを自動算出するフローを構築できます。スコアの高い上位候補地だけを詳細精査することで、スクリーニングの効率が大幅に向上します。
課題➃:消費財メーカーとして「どのエリアの得意先に注力すべきか」判断したい
課題の実態
全国の得意先チェーンは数百社・数千店舗に上る。すべてに均等に営業リソースを投下するのは非効率だが、優先順位の付け方に客観的な基準がない。
GIS×予測モデルによる解決
得意先店舗の商圏特性(人口・年齢構成・ライフスタイル指標)と自社商品の需要ポテンシャルを掛け合わせたスコアリングモデルを構築することで、「注力すべき得意先・エリアのランキング」を定量的に算出できます。
課題⑤:人口減少エリアの既存店を今後どうするか判断したい
課題の実態
地方の既存店舗の売上が少しずつ低下している。閉店すべきか、業態転換すべきか、維持すべきかの判断基準がない。
GIS×予測モデルによる解決
将来推計人口データを組み込んだ予測モデルにより、「5年後・10年後の商圏人口変化が売上に与える影響」を推定できます。「このままでは10年後に現在比60%の売上になる可能性がある」という将来シナリオをデータで示し、早期の戦略転換判断を促すことができます。
エリアデータ活用における2つの重要な注意点
注意点①:データの更新頻度と「鮮度」を確認する
人口データは時間とともに変化します。国勢調査データは5年ごとの更新であるため、直近の人口動態(急速な開発・人口流入・人口流出)を反映できないことがあります。
特に開発が進むエリア(大規模マンション建設・新駅開業 等)や、人口流出が急速なエリアでは、数年前のデータに基づいた予測は大きく外れるリスクがあります。こうした場合、人流データを活用した最新の人口動態データを補完的に使用することが有効です。
注意点②:モデルの「学習データ」の質と量を確保する
GISデータをどれだけ丁寧に整備しても、予測モデルを学習させる既存店舗のデータ(学習データ)の質と量が不十分では、精度の高いモデルは作れません。
一般的に、予測モデルの学習には最低でも30〜50店舗以上の実績データが必要とされます(業態・モデルの複雑さによって異なります)。店舗数が少ない段階では、シンプルな回帰分析から始め、店舗数の増加とともにモデルを高度化していくアプローチが現実的です。
まとめ—「場所の力」をデータにすることが、予測精度を変える
本コラムのポイントを振り返ります。
・多店舗チェーンの売上予測・出店判断において、エリアの特性(立地の力)が予測精度を最も大きく左右する変数である
・GISを活用することで、昼夜間人口・年齢別人口・競合距離・施設数といったエリアデータを説明変数として定量的に取り込めるようになる
・商圏の定義→エリアデータの取得・集計→既存店データとの組み合わせによるモデル学習→新規候補地への適用、という4ステップで予測モデルとGISを統合できる
・昼間人口と居住人口(夜間人口)は業態によって重要度が異なり、両方を取得したうえで業態特性に合わせた使い方をすることが精度向上の鍵
・エリアデータの「鮮度」と予測モデルの「学習データのN数確保」が、実務上の2大注意点
GISと予測モデルを掛け合わせた出店判断・需要予測の精度向上は、まだ多くの企業が手をつけられていない領域です。だからこそ、先に取り組んだ企業が大きな競争優位を築けます。
技研商事インターナショナルのGIS×データソリューション
「GISと予測モデルを統合したい」「エリアデータを精度高く取得したい」—こうしたニーズに応えるソリューションを、技研商事インターナショナルは一体で提供しています。
- MarketAnalyzer® 5出店判断・商圏分析に特化したGISパッケージです。候補地の商圏設定から、エリアデータの可視化・集計、複数候補地の比較評価まで、店舗開発に必要な機能を一つの画面で完結できます。予測モデルへのデータ出力機能との組み合わせで、「GISで見る×モデルで予測する」の統合ワークフローを実現します。
- KDDI Location Analyzer:KDDIのGPS位置情報を活用して、実態に近い昼夜間の人口動態を提供します。国勢調査では捉えにくい「リアルタイムに近い人の流れ」を商圏分析・予測モデルの説明変数として活用できます。
- c-japan® Home(居住人口データ):全国の居住人口(夜間人口)データを高精度・高粒度(500mメッシュ等)で提供します。食品スーパー・ドラッグストア・クリーニング・塾・住宅地型飲食チェーンなど、生活密着型業態の需要予測に不可欠な説明変数です。年齢別・世帯構成別のデータも取得可能で、ターゲット層の濃淡を数値で把握できます。
- c-japan® Daytime(昼間人口データ)全国の昼間人口データを高精度・高粒度で提供します。就業者・通学者・観光客など、昼間の「そのエリアにいる人」の実態をデータ化しています。飲食チェーン・コンビニ・カフェ・駅前立地型業態の来客数・売上予測において、夜間人口との組み合わせで真の商圏ポテンシャルを把握できます。
- THE NOVEL:AIを活用した次世代商圏分析ツールです。GISと機械学習を組み合わせた高度な立地評価・予測を、専門知識なしで扱える直感的なUIで提供します。GIS×予測モデルの統合環境をすぐに使い始めたい企業に最適なソリューションです。
まずはお気軽にご相談・資料請求ください。
御社の業態・課題に合った最適なソリューションをご提案します。
お問い合わせ・無料相談はこちら ▶ https://www.giken.co.jp/contact/
監修者プロフィール
市川 史祥
技研商事インターナショナル株式会社
取締役CMO シニアコンサルタント 市川 史祥
一般社団法人LBMA Japan 理事
ロケーションプライバシーコンサルタント
流通経済大学客員講師/共栄大学客員講師
統計士/医療経営士/介護福祉経営士
Google AI Essentials/Google Prompt Essentials

1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



