業界の最新動向をチェック
エリアマーケティングラボ
ノウハウ
予測モデルの種類と選び方
回帰・決定木・時系列、ビジネス課題別の使い分けガイド
2026/06/02

予測モデルを導入しようとしたとき、多くの担当者が最初に直面する壁があります。「回帰・決定木・ランダムフォレスト・ニューラルネットワーク……いったいどれを選べばいいのか?」という問いです。
インターネットで調べると、数十種類のアルゴリズム名が並び、それぞれの優劣を比較した技術コラムが無数に出てきます。しかしその多くは「データサイエンティストが読むコラム」であり、店舗開発や営業企画を担う実務者が求める「自分の業務にはどれが合うのか」という問いには、なかなか答えてくれません。
本コラムでは、アルゴリズムの数式や実装コードは一切出てきません。「どんな課題に、どの種類のモデルが向いているか」という実務的な視点から、予測モデルの種類と選び方を整理します。
目次
- 予測モデルの選び方の大原則——「何を予測するか」でタイプが決まる
- 数値を予測する「回帰モデル」
- 回帰モデルとは
- 代表的な手法
- 多店舗チェーン・消費財メーカーでの活用シーン
- 回帰モデルの強みと弱み
- 「Yes/No」を判断する「分類モデル」
- 分類モデルとは
- 代表的な手法
- 多店舗チェーン・消費財メーカーでの活用シーン
- 分類モデルの強みと弱み
- 時間の流れを読む「時系列モデル」
- 時系列モデルとは
- 代表的な手法
- 多店舗チェーン・消費財メーカーでの活用シーン
- 時系列モデルの強みと弱み
- 精度をさらに高める「アンサンブル学習」
- ランダムフォレスト——「多数決」で精度を安定させる
- XGBoost・LightGBM——実務で最も選ばれる高精度モデル
- ニューラルネットワーク・ディープラーニングについて
- 定性的予測との組み合わせ——データがない場面への対処
- ビジネス課題別・予測モデル種類の選び方 早見表
- 精度向上のカギ——アルゴリズムよりも「説明変数の質」
- まとめ
- 各モデルの活用に必要なデータについて

予測モデルの選び方の大原則——「何を予測するか」でタイプが決まる

予測モデルの種類を選ぶとき、最初に考えるべきことはアルゴリズムの優劣ではありません。「自分が解きたい問いの性質」です。
ビジネスにおける予測の問いは、大きく3つのタイプに分類できます。
| 問いのタイプ | 問いの例 | 向いているモデル |
|---|---|---|
| 数値を当てる | 来月の売上はいくらか?仕入れは何個必要か? | 回帰モデル |
| どちらかに分ける | この出店候補は成功するか否か?この顧客は離脱するか否か? | 分類モデル |
| 時間の流れを読む | 季節変動を踏まえた来年の需要はどう推移するか? | 時系列モデル |
この3分類を頭に入れておくだけで、「どのモデルが自分の課題に合うか」を考える土台ができます。以下では、それぞれのタイプと代表的な手法を詳しく見ていきます。
数値を予測する「回帰モデル」

回帰モデルとは
回帰モデルとは、売上金額・出荷数・来客数といった連続した数値を予測するためのモデルです。予測モデルの中でも最も基本的な種類であり、ビジネスの現場で最も広く使われています。
仕組みを直感的に理解するには、グラフを思い浮かべてください。横軸に「商圏内の昼間人口」、縦軸に「店舗の月次売上」をプロットすると、多くの場合、人口が多いほど売上も高いという右肩上がりの傾向が見えます。回帰モデルとは、このデータの傾向に最もよくフィットする「線(または曲線)」を引き、その線をもとに未知の状況での数値を推定する手法です。
代表的な手法
線形回帰・重回帰分析
1つまたは複数の説明変数から目的変数を予測します。最もシンプルで、「どの変数がどれくらい売上に効いているか」が数値として出るため、現場への説明がしやすいのが特徴です。たとえば「昼間人口が1,000人増えると月次売上が約50万円上がる」という形で結果を提示できます。
リッジ回帰・ラッソ回帰
説明変数の数が多いとき(立地データ・競合データ・天候データなどを大量に入れた場合)に、精度を保ちながら過学習(モデルが学習データに過度に最適化され、実際の予測精度が落ちる現象)を防ぐための「正則化」という技術を加えた手法です。変数が多い場合に選ばれることが多いです。
多店舗チェーン・消費財メーカーでの活用シーン
- 新規出店候補地の初年度売上推定
- 月次・週次・日次の店舗売上予測
- 商品の翌月出荷数・販売数の予測
- 広告費や値引き率の変化が売上に与える影響の定量化
- キャンペーン実施による売上増加額の事前シミュレーション
回帰モデルの強みと弱み
| 強み | 弱み |
|---|---|
| ・結果の解釈がしやすい(現場説明に向く) ・データ量が少なくても一定 of 精度が出やすい ・変数の重要度を係数として確認できる |
・説明変数と目的変数の関係が非線形な場合は精度が落ちる ・複雑な交互作用(A×Bが同時に起きたとき)の捕捉が苦手 ・外れ値(異常値)の影響を受けやすい |
「Yes/No」を判断する「分類モデル」

分類モデルとは
分類モデルとは、対象がどのカテゴリに属するかを予測するモデルです。「数値がいくらか」ではなく、「AかBか」「成功か失敗か」「リスクが高いか低いか」といった二択または複数の選択肢への振り分けを行います。
ビジネス上の意思決定は「出店する/しない」「配荷する/しない」「プロモーションを打つ対象にする/しない」という形の二択が非常に多く、こうした場面では回帰モデルよりも分類モデルが適しています。
代表的な手法
ロジスティック回帰
「出店成功の確率が何%か」というように、結果を確率として出力します。たとえば「この候補地の出店成功確率は78%」という形で表示されるため、経営層へのレポーティングにも使いやすい手法です。名前に「回帰」とありますが、分類問題を解くために使われます。
サポートベクターマシン(SVM)
データを「成功グループ」と「失敗グループ」に最もきれいに分ける境界線を引くことで分類します。データの次元が高い(説明変数が多い)場合にも安定した精度を発揮します。
k近傍法(k-NN)
新しいデータを、過去のデータの中で「最も特性が似ている事例」に近づけて分類します。「類似商圏の既存店が成功しているなら、この候補地も成功しやすい」という考え方に近く、直感的に理解しやすい手法です。
多店舗チェーン・消費財メーカーでの活用シーン
- 新規出店候補地の「成功・不振」分類(二値分類)
- 既存店の「改善要観察・早期閉店検討」フラグ立て
- 得意先・顧客の「離退リスクあり・なし」分類
- キャンペーン対象顧客の「反応する・しない」予測
- 新商品を「先行配荷すべきエリア・見送りエリア」に分類
分類モデルの強みと弱み
| 強み | 弱み |
|---|---|
| ・「Go/No Go」の判断そのものを出力できる ・確率値で「信頼度」を表現できる ・基準が明確なため現場に定着しやすい |
・「どれだけ成功するか」の規模感(金額等)は出せない ・正解ラベル(過去の成功・失敗の記録)が必要 ・判断基準の定義(何をもって「成功」とするか)が事前に必要 |
時間の流れを読む「時系列モデル」
時系列モデルとは
時系列モデルとは、時間の経過とともに変化するデータのパターンを学習し、将来の値を予測するモデルです。売上・来客数・出荷量といった日次・週次・月次で蓄積されていく指標の「次の値」を推定することに特化しています。
時系列データには、一般的に次の3つの要素が混在しています。
- トレンド:長期的な増加・減少の傾向(例:年々売上が少しずつ伸びている)
- 季節性:特定の周期で繰り返されるパターン(例:夏に売上が上がり、冬に下がる)
- ノイズ:トレンドにも季節性にも当てはまらないランダムな変動(例:台風による一時的な来客減)
時系列モデルは、このトレンドと季節性を学習し、次の時点の値を推定します。
代表的な手法
ARIMA(自己回帰和分移動平均モデル)
過去の値と予測誤差のパターンから次の値を推定する、統計的な時系列予測の定番手法です。比較的シンプルなデータ構造に向いており、計算コストが低いのが特徴です。
Prophet(Facebookが開発)
季節性・祝日・特別イベントなどを考慮した予測が得意で、チェーン店舗の売上予測(年末年始・GW・お盆などの特需を含む)に特に相性が良い手法です。専門知識がなくても扱いやすく、実務への導入が進んでいます。
LSTM(長短期記憶ネットワーク)
ディープラーニングの一種で、長い期間にわたる複雑なパターンの学習が得意です。ただし、大量のデータと計算リソースが必要で、構築・運用のハードルが高いため、まずはARIMAやProphetで試してみることを推奨します。
多店舗チェーン・消費財メーカーでの活用シーン
- 月次・週次の店舗売上予測(トレンド+季節性の考慮)
- 季節商品(夏物・冬物・おせち等)の需要量予測と仕入れ計画
- 年末年始・GWなど特需期の来客数・売上スパイク予測
- 中長期的な市場需要のトレンド予測
- プロモーション終了後の需要の落ち込み予測(反動減の見込み)
時系列モデルの強みと弱み
| 強み | 弱み |
|---|---|
| ・季節変動・トレンドを自動で考慮できる ・需要の波動を可視化できる ・発注・仕入れ計画との連動がしやすい |
・時系列データ(一定期間の蓄積)が必要 ・急激な構造変化(新型感染症・自然災害等)には弱い ・説明変数を多数追加するのが難しい場合がある |
精度をさらに高める「アンサンブル学習」
単一のモデルではなく、複数のモデルの結果を組み合わせて最終予測を出す手法を「アンサンブル学習」と呼びます。野球で言えば「1人のエースより、複数の投手のリレーで勝ちにいく」戦略に近いイメージです。ここでは、現場で特によく使われる2つを紹介します。
ランダムフォレスト——「多数決」で精度を安定させる
決定木とは、データを条件で繰り返し分岐させ、木のような構造でYes/Noの判断や数値予測を行う手法です。「商圏内の昼間人口が1万人以上 かつ 競合店が500m以内にない場合、売上は月1,000万円以上になる確率が高い」というような分岐のルールが、データから自動的に生成されます。
決定木の特徴は、分析のロジックが木構造として「見える」点です。「なぜその予測になったか」を現場の担当者や経営層に説明するとき、グラフとして示せる直感的なわかりやすさがあります。
ただし、1本の決定木は「過学習」を起こしやすいという弱点があります。そこで登場するのがランダムフォレストです。多数の決定木をランダムに構築し、それぞれの予測結果の多数決(回帰の場合は平均値)を最終予測とします。
1本の木より大幅に安定した精度を発揮し、どの説明変数が予測に効いているかの「変数重要度」も出力できます。「昼間人口・競合距離・最寄り駅乗降者数のうち、売上に最も影響しているのはどれか」を確認する際にも有効です。
| 強み | 弱み |
|---|---|
| ・過学習しにくく安定した精度 ・変数重要度を確認できる ・欠損値や異なるスケールの変数に比較的強い |
・1本の決定木より解釈しづらい(ブラックボックス感が増す) ・データ量が少ない場合は効果が出にくい ・学習に時間がかかる場合がある |
XGBoost・LightGBM——実務で最も選ばれる高精度モデル
XGBoost(エックスジーブースト)とLightGBM(ライトジービーエム)は、決定木を応用した「勾配ブースティング」という技術を使ったモデルです。
ランダムフォレストが「複数の木を並列に作って多数決する」のに対し、勾配ブースティングは「前の木が間違えた部分を次の木が補正する」という形で、順番に精度を改善し続けます。
Kaggle(データサイエンスの国際コンペ)での優勝モデルに頻繁に採用されていることで知られており、特に表形式のデータ(POSデータ・販売実績・立地データ等)との相性が非常に良いのが特徴です。多店舗チェーンや消費財メーカーが保有するデータの多くは表形式であるため、実務での採用率が高い手法です。
| 強み | 弱み |
|---|---|
| ・表形式データで高い予測精度 ・学習速度が速い(LightGBMは特に) ・変数重要度を確認できる |
・ハイパーパラメータの調整が必要で専門知識がいる ・ランダムフォレストより過学習しやすい場合がある ・データ前処理の丁寧さが精度に直結する |
ニューラルネットワーク・ディープラーニングについて
ニューラルネットワークは人間の脳の神経回路を模した構造を持ち、膨大なデータから複雑なパターンを自動で学習できる手法です。「AI・機械学習」というとこのイメージを思い浮かべる方も多いでしょう。
画像認識や自然言語処理(テキスト解析)などの分野では圧倒的な性能を発揮しますが、多店舗チェーンの売上予測や消費財メーカーの需要予測といった表形式データを扱う場面では、必ずしもニューラルネットワークが最善とは限りません。
理由は3つあります。第1に大量のデータが必要(データが少ないとランダムフォレストやLightGBMに負けることが多い)、第2に「なぜその予測になったか」の説明が難しい(ブラックボックス問題)、第3に構築・運用のコストが高い——という点です。
【ニューラルネットワークが向いている場面】
- 店舗内カメラ映像からの来客数・行動分析(画像データ)
- SNS・レビューテキストからの顧客感情分析(テキストデータ)
- IoTセンサーデータを活用した設備異常予知
実務での予測モデル導入においては、まずはランダムフォレストやLightGBMで始め、精度が不十分な場合の選択肢としてニューラルネットワークを検討するアプローチが現実的です。
定性的予測との組み合わせ——データがない場面への対処

予測モデルはすべてデータを必要とします。しかし実務では「このエリアには過去の出店データがない」「このカテゴリは新規参入で実績が全くない」という場面が必ず出てきます。
そうした場面では、定性的な予測手法との組み合わせが有効です。
■ デルファイ法(専門家の意見集約)
特定の分野の専門家に個別にアンケートを取り、意見を集約・フィードバックし、合意形成を図る手法です。新規カテゴリへの参入可否判断や、前例のないエリアへの出店検討などで活用されます。
■ 市場調査・消費者アンケート
定量データが不十分な場合、対象エリアの消費者に直接調査を行い、購買意向・来店意向を把握します。
そして、定量(予測モデル)と定性(専門家知見・フィールド調査)を組み合わせるハイブリッドアプローチが、実務では最も精度と信頼性を高めます。たとえば「GISデータ・人口データに基づいた売上予測モデル(定量)」に、「現地視察・競合ヒアリング(定性)」を組み合わせて最終的な出店判断を下す、というプロセスが代表例です。
ビジネス課題別・予測モデル種類の選び方 早見表
ここまでの内容を整理します。「自分の業務に当てはめたときに、どのモデルが候補になるか」を確認してください。
| ビジネス課題 | 問いのタイプ | 推奨モデル | 代表アルゴリズム |
|---|---|---|---|
| 新規出店候補地の売上ポテンシャル推定 | 数値を当てる | 回帰モデル | 重回帰分析、ランダムフォレスト、LightGBM |
| 出店候補地の「成功・不振」判定 | どちらかに分ける | 分類モデル | ロジスティック回帰、ランダムフォレスト |
| 月次・週次の店舗売上予測(季節考慮) | 時間の流れを読む | 時系列モデル | Prophet、ARIMA |
| 季節商品・需要の年間波動予測 | 時間の流れを読む | 時系列モデル | Prophet、SARIMA |
| 既存店の不振リスク早期発見 | どちらかに分ける | 分類モデル | ランダムフォレスト、LightGBM |
| 商品の翌月出荷・在庫数の予測 | 数値を当てる | 回帰モデル+時系列 | LightGBM、Prophet |
| エリア別・商品別の需要ポテンシャル推定 | 数値を当てる | 回帰モデル | 重回帰分析、ランダムフォレスト |
| キャンペーン対象顧客の反応予測 | どちらかに分ける | 分類モデル | ロジスティック回帰、LightGBM |
| 複数候補地の優先順位スコアリング | 数値を当てる | 回帰モデル | ランダムフォレスト、LightGBM |
【選定の基本ルール】
- まず「何を予測したいか(回帰・分類・時系列)」でカテゴリを決める
- データ量が少なければシンプルなモデルから始める(重回帰分析・ロジスティック回帰)
- 「なぜその予測か」の説明が重要なら解釈しやすいモデルを選ぶ(決定木・回帰系)
- データが充実していて精度を追求するなら、ランダムフォレスト・LightGBMへ
- 季節変動や時系列パターンが重要ならProphetやARIMAを加える
精度向上のカギ——アルゴリズムよりも「説明変数の質」
ここまでアルゴリズムの種類を解説してきましたが、実はビジネスにおける予測モデルの精度を最も大きく左右するのは、アルゴリズムの選択よりも「どんな説明変数(データ)を入れるか」です。
どんなに高性能なエンジンでも、入れる燃料(データ)が粗悪なら走りません。逆に、シンプルな重回帰分析でも、質の高い説明変数を適切に設計すれば、実用に十分な予測精度を出せることも少なくありません。
特に多店舗チェーンの売上予測・出店判断において精度向上に貢献する説明変数の筆頭が、エリア系データです。商圏内の居住人口(夜間人口)・昼間人口・年齢別人口構成・将来推計人口・競合店舗情報——こうしたデータは、立地の「売上ポテンシャル」を数値として捉えるうえで不可欠です。

まとめ

本コラムでは、予測モデルの主な種類と、ビジネス課題別の選び方を整理しました。要点を振り返ります。
- 予測モデルは「回帰モデル(数値を当てる)」「分類モデル(どちらかに分ける)」「時系列モデル(時間の流れを読む)」の3タイプに大別できる
- アンサンブル学習の代表である「ランダムフォレスト」「XGBoost・LightGBM」は、表形式データとの相性が良く、多店舗チェーン・消費財メーカーの実務で特に選ばれやすい
- ニューラルネットワーク・ディープラーニングは万能ではなく、データが少ない・説明が必要な場面では逆効果になることもある
- モデルの精度を最終的に決めるのはアルゴリズムの選択よりも「どんな説明変数を使うか」
- 定量(予測モデル)と定性(現地調査・専門家知見)を組み合わせるハイブリッドアプローチが実務では最も効果的
各モデルの活用に必要なデータについて
どのモデルを選んでも、予測の精度は「どんな質のデータを投入できるか」に大きく依存します。
技研商事インターナショナルでは、予測モデルの精度向上に欠かせないエリアデータを提供しています。
- c-japan® Home:居住系人口統計データから居住者特性を小地域単位で分類したエリアセグメンテーションデータ。食品スーパー・ドラッグストア・住宅地型チェーンの需要予測説明変数として活用できます。
- c-japan® Daytime:昼間人口データを用いて小地域を分類したエリアセグメンテーションデータ。飲食チェーン・コンビニ・駅前立地型店舗の来客数・売上予測に有効な説明変数です。
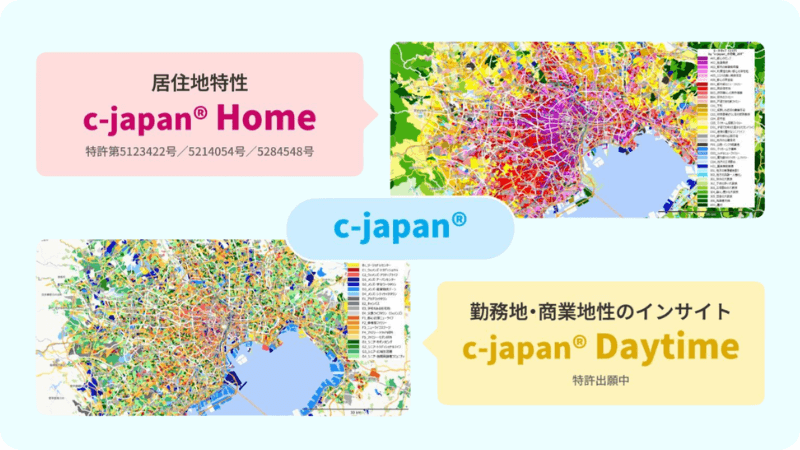
これらのデータをGISパッケージ「MarketAnalyzer® 5」で地図上に可視化・集計し、予測モデルに投入することで、精度の高い出店判断・需要予測を実現できます。

技研商事インターナショナルは、THE NOVELに搭載された「売上予測AI」機能などを通じて、この「人×AI」の高度な協調を実現し、皆様のデータドリブン(データ駆動型)な意思決定を強力に支援し続けてまいります。
■ 次に読むべき記事
予測モデルの種類やビジネス課題に応じた具体的な選び方を体系的に理解しましょう。
→「予測モデルの種類と選び方」を読む
■ 関連記事
・エリアデータを予測モデルにどう組み込むか、具体的な方法は以下のコラムでご紹介しています!
「GIS×予測モデルで出店判断の精度が変わる」
・多店舗チェーン・消費財メーカーへの具体的な活用事例は以下をご参照ください!
「小売・飲食チェーンと消費財メーカーの予測モデル活用事例」
監修者プロフィール
市川 史祥
技研商事インターナショナル株式会社
取締役CMO シニアコンサルタント 市川 史祥
一般社団法人LBMA Japan 理事
ロケーションプライバシーコンサルタント
流通経済大学客員講師/共栄大学客員講師
統計士/医療経営士/介護福祉経営士
Google AI Essentials/Google Prompt Essentials

1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



