業界の最新動向をチェック
エリアマーケティングラボ
ノウハウ
クラスター分析とは?商圏分析・店舗開発での活用方法を解説
2026/06/29
「この立地は感覚的に既存のヒット店に似ている」「自社の主要ターゲットは30代のファミリー層だ」――こうした経験則や、年齢・性別といった画一的な属性による分類は、これまで多くのビジネスを支えてきました。しかし、消費者のライフスタイルや価値観が極限まで多様化した現代において、単一の属性や担当者の“土地勘”だけに頼った意思決定は、思わぬ見落としや出店リスクを招く原因になりかねません。
膨大なデータの中に埋もれた「真の顧客像」や「エリアの本質的なポテンシャル」を客観的に見極めるにはどうすればよいのか。その強力な解決策となるのが、大量のデータを特徴の類似性によってグループ化する多変量解析の手法「クラスター分析」です。
本コラムでは、クラスター分析の基礎知識から、商圏分析・店舗開発における具体的な活用メリット(顧客分類・商圏分類・出店候補地評価など)を分かりやすく解説します。さらに、GIS(地理情報システム)ツールを活用したデータドリブンで高い再現性を持つ実践的なアプローチについてもご紹介します。
目次
- 1. クラスター分析とは
- 2. クラスター分析の種類
- 階層型クラスター分析
- 非階層型クラスター分析
- k-means法とは
- 3. クラスター分析でわかること
- 顧客分類
- 商圏分類
- 店舗分類
- 地域特性分析
- c-japan® Homeの活用
- c-japan® Daytimeの活用
- 4. 商圏分析でのクラスター分析活用例
- 類似商圏の抽出
- 売上上位店舗群の分析
- 人流データを活用したエリア分類
- 出店候補地評価
- 5. クラスター分析に必要なデータ
- 人口統計
- 人流データ
- POSデータ
- 競合データ
- GISデータ
- 6. クラスター分析を行う際の注意点
- 変数選定
- 標準化
- クラスター数の決定
- 解釈性の確保
- 7. GISを活用したクラスター分析
- MarketAnalyzer® 5のクラスター分析機能
- 8. まとめ

1. クラスター分析とは

現代のマーケティング環境において、消費者のライフスタイルや価値観はかつてないほど多様化しています。小売業や飲食業における多店舗展開、あるいは消費財メーカーによる緻密な営業企画において、従来の画一的なアプローチは通用しなくなっています。このような複雑な市場環境の中で、意思決定の強力な羅針盤となるのが「クラスター分析」です。
クラスター分析とは、多変量解析(複数の変数を同時に扱う統計的アプローチの総称)の一手法です。大量かつ多様なデータ群の中から、互いに似た特徴を持つもの同士を集め、「クラスター(集落・グループ)」を形成して分類します。年齢や性別といった単一の属性に依存した従来のセグメンテーション(顧客分類)とは異なり、複数の変数を総合的に評価し、データ間の相互関連性を数学的な「距離」として算出して客観的にグループ化する点が最大の特徴です。
店舗開発の現場では「どのような立地条件の店舗が同一の傾向を示すのか」、消費財メーカーの営業企画では「どのような居住特性を持つエリアで特定の商品が動くのか」といった問いに対し、担当者の経験や勘に依存することなく、一定のアルゴリズムに基づいた高い再現性を持つ客観的な分類を提供します。分類に用いるデータは目的に合わせて自由に選択できるため、自社のビジネス課題に直結したオーダーメイドの分析環境を構築することが可能です。
2. クラスター分析の種類
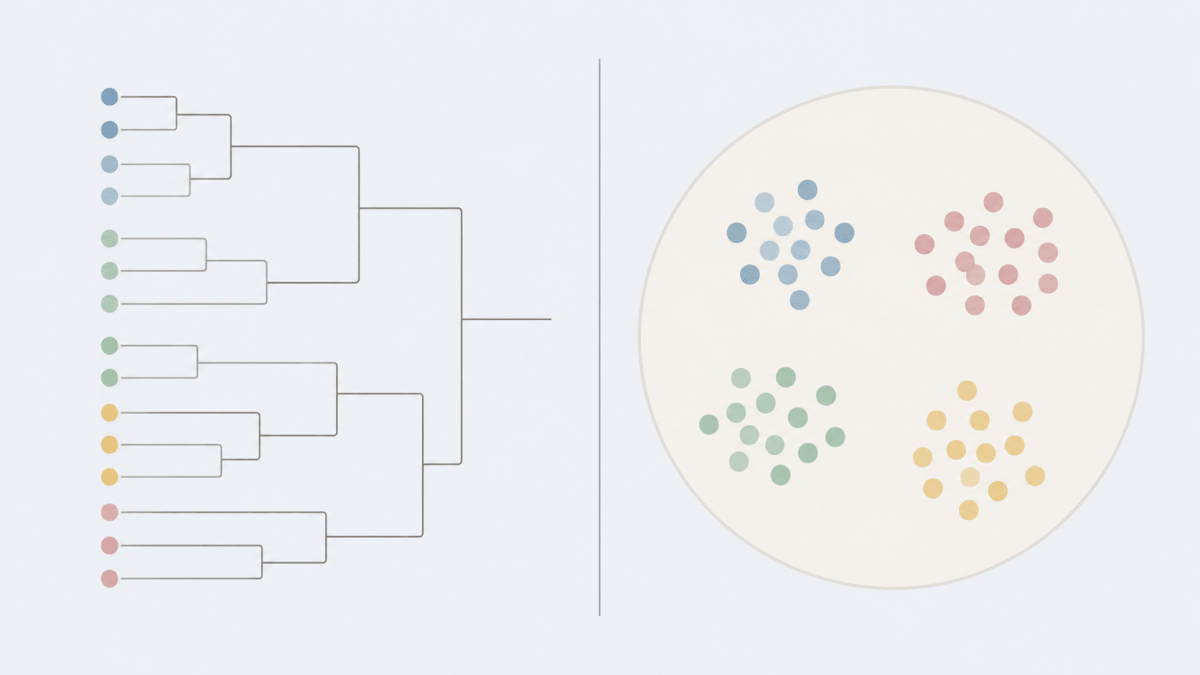
クラスター分析は、計算アルゴリズムと分類プロセスのアプローチによって、大きく「階層型クラスター分析」と「非階層型クラスター分析」の2種類に大別されます。分析の目的や対象データの規模(サンプルサイズ)に応じて使い分けることが、精緻なマーケティング戦略立案の第一歩となります。
階層型クラスター分析
階層型クラスター分析は、対象データの中から最も類似度の高いデータ同士を順番に結合していき、最終的にすべてのデータがひとつの大きなまとまりになるまで階層的な構造を構築していく手法です。この過程は「樹形図(デンドログラム)」と呼ばれるトーナメント表のようなグラフとして視覚化されるため、どのデータがどの段階で同じクラスターに結合されたのかを直感的に把握しやすい利点があります。
数十店舗規模の地域ブロックの店舗特性を詳細に把握したい場合や、少数の顧客ペルソナ間の関係性を視覚的に整理したい場合に有効です。一方、すべてのデータ間の距離を総当たりで計算し続ける性質上、データ量が増えるにつれて計算負荷が急増するため、全国規模のID-POSデータや大量のエリアメッシュデータを処理するビッグデータ分析には不向きという特性もあります。
- 補足:ID-POSデータとは
- 顧客ID(ポイントカードなど)と購買履歴を紐付けた販売データのことです。「誰が・いつ・何を・いくらで買ったか」を個人レベルで追跡できます。
非階層型クラスター分析
階層型の計算負荷の課題を克服し、現代のマーケティングで主流となっている大規模データの分類に特化した手法です。分析者が「あらかじめいくつのグループに分類するか(クラスター数)」を決定したうえで、膨大なデータを一気にフラットに分類します。
処理が比較的高速なため、数百万人の会員購買履歴のクラスタリングや、全国の町丁目単位のGIS(地理情報システム)データの分類といったビッグデータ処理に強みを発揮します。一方で、「最適なクラスター数を事前に決めなければならない」という制約があるため、事前の仮説構築やビジネス上の運用要件(例:全国の店舗を管理しやすい5つのフォーマットに分類したい等)と照らし合わせた設定が求められます。
k-means法とは
非階層型クラスター分析の中で最も代表的かつビジネス現場で広く活用されているアルゴリズムが「k-means法(k平均法)」です。プロセスは以下のとおりです。
- 指定された「k個」のクラスターの中心点(重心)を空間上にランダムに配置する
- すべてのデータを最も距離が近い中心点に割り当て、仮のグループを形成する
- 各グループ内のデータの平均値を計算し、その平均値へ中心点を移動させる
- 「中心点への割り当て」と「中心点の再計算」を繰り返し、中心点が移動しなくなった時点で分類を確定する
アルゴリズムがシンプルながら強力な分類能力を持つ反面、平均値を用いて重心を計算するため、極端な異常値(アウトライア)が存在するとそちらへ重心が引っ張られ、全体の分類精度が低下するという弱点があります。店舗データや商圏データへk-means法を適用する際は、極端に売上が高い旗艦店や人口密度が突出した特異なエリアを事前に除外するデータクレンジング(前処理)が不可欠です。
3. クラスター分析でわかること
クラスター分析を実際のビジネスデータに適用することで、単なる集計表の羅列からは見出せない、立体的で示唆に富んだインサイトを獲得できます。
顧客分類
顧客の属性データや購買履歴(POSデータ)をクラスター分析にかけることで、実態に即した動的な顧客分類が実現します。現代の消費者は単一の属性にとどまらず、シチュエーションに応じて購買行動を柔軟に変化させています。このような複雑な行動パターンも、クラスター分析を用いることで精緻に類型化することが可能です。
単に「30代女性」という括りではなく、「来店頻度」「平均購買単価」「購入カテゴリの多様性」「来店時間帯」などの変数を組み合わせることで、「週末にまとめ買いをする価格敏感なファミリー層」や「平日夜間にトレンド商材を単価を気にせず購入する単身層」といった、具体的で実体感のあるペルソナを描き出せます。これにより、各クラスターに対して最も効果的なプロモーション施策や商品開発の方向性を明確に定めることができます。
商圏分類
商圏分類とは、各店舗の足元に広がる市場(商圏)を、地理的な近さではなく、統計的な特性の類似性に基づいてグループ化することです。人口密度、年齢構成、世帯年収、競合環境といった多数の変数を投入してクラスタリングを行うと、例えば「東京都内の特定の住宅街」と「福岡県内の特定の住宅街」が、物理的には離れていても商圏としての性質は極めて似ている(同一クラスターに属する)ことが判明するケースがあります。
このインサイトは、成功事例の横展開において絶大な力を発揮します。あるクラスターで大ヒットした販促施策や新業態が存在した場合、全国に散らばる同一クラスターの商圏に対して同様の施策を水平展開することで、高い確率で成功を再現できます。商圏分類は、限られたリソースをどこに集中投下すべきかを示す戦略的なマップとなります。
店舗分類
全国に多店舗展開を行うチェーン企業において、全店舗を一律の基準で管理することは、現場の特性を見落とす原因となります。売上実績、客単価、店舗面積、立地属性などのデータをもとに店舗をクラスタリングすることで、自社の店舗網を客観的に類型化し、それぞれのグループに最適なマネジメントを適用できます。
クラスターごとに個別売上予測モデルを構築することで、予測精度は飛躍的に向上します。駅前立地の店舗群とロードサイドの郊外型店舗群では、売上を牽引する要因(説明変数)が根本的に異なるためです。また、消費財メーカーのリテールサポート業務においても、取引先である小売企業の店舗をクラスタリングし、店舗周辺の居住特性や客層に応じた最適な商品訴求や棚割り(プラノグラム)をデータに基づいて提案することで、商談の説得力を大幅に高めることができます。
- 補足:プラノグラムとは
- 店頭の棚における商品の陳列計画のことです。どの商品をどの位置に・どの向きで・何フェース(列)並べるかを定めたものです。
地域特性分析
地域特性の深い理解において欠かせないのが、精緻に設計されたエリアセグメンテーションデータの活用です。ここでは、居住者のライフスタイルを可視化する「c-japan® Home」と、昼間の活動人口の実態を捉える「c-japan® Daytime」という2つのデータ製品についてご紹介します。これらをクラスター分析の変数として組み込むことで、地域の解像度が大幅に高まります。
- 補足:c-japan®とは
- 技研商事インターナショナルが提供するエリアセグメンテーションデータです。国勢調査データなどをもとに、日本全国の町丁目・メッシュ単位で居住者や昼間人口の特性を分類しています。
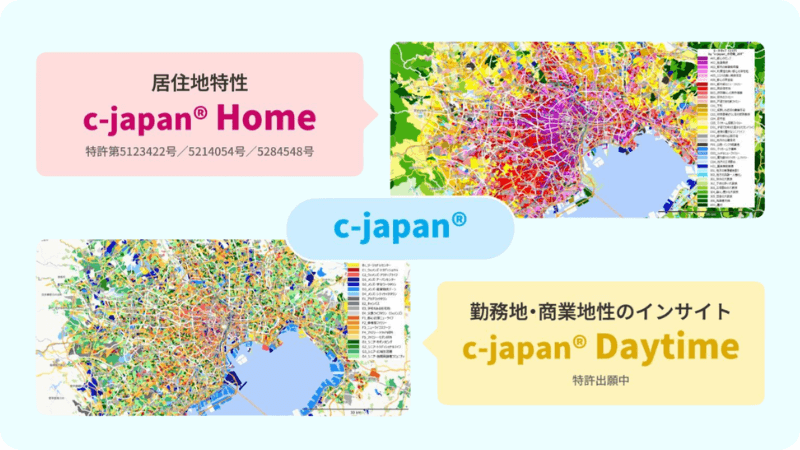
c-japan® Homeの活用
「c-japan® Home」は、夜間人口(居住者)ベースのジオデモグラフィックデータです。
- 補足:ジオデモグラフィックとは
- 地理(Geo)と人口統計(Demography)を組み合わせた概念で、「どこに住む・どんな人か」を地域単位でプロファイリングする手法です。
年齢や家族構成といった一般的な国勢調査の項目に加え、独自の「年収」や「地価」を加味した特許取得済みのプロファイリング技術を用いており、日本全国の町丁目やメッシュを11の大分類居住特性(さらに細分化された35の小分類)にクラスタリングしています。
| 大分類クラスター名 | クラスターの主な特徴と居住者のプロファイル |
|---|---|
| A. 都市部の単身層 | 人口密度が非常に高く、20〜40代のマンション住まいの単身層が中心。ITや金融などの就業者が多く、平均年収層と富裕層が混在するエリア |
| B. 都市部のファミリー | 都市部の40〜50代現役層を中心とした核家族。地価が高く、世帯年収700万円前後の層から高級住宅街までが混在するエリア |
| C. 近郊の成熟した住宅街 | 都市近郊に位置し、居住期間が長い成熟した住宅街。核家族が多く、自家用車を複数台所有する世帯も見られる安定したエリア |
| D. 豊かなセカンドライフ | 子育てを終えた世代やリタイア後の世帯が多く、年収・貯蓄ともに豊か。戸建て持ち家率が高く、輸入車の保有比率が高いエリア |
| E. 公団住まい | 公営住宅の割合が非常に高く、周辺にはディスカウントストアやホームセンターが多く立地する生活防衛意識の高いエリア |
| F. 公務・インフラ | 公務員やインフラ事業従事者の社宅住まい単身層が中心。失業率が低く、安定した雇用環境にあるエリア |
| G. ニューファミリー | 10歳未満の子どもと30〜40代の親世代の比率が高い子育て世代。借家とマイホーム購入層が混在し、軽自動車や国産車の保有率が高いエリア |
| H. 製造業就業者 | 20〜30代の単身製造業従事者が多く、外国人比率が高い。周辺に定食屋・ラーメン・パチンコ店などが集積するエリア |
| I. 地方の単身層 | 20〜30代および50歳以上の地方単身世帯が中心。借家や社宅が多く、軽自動車の所有比率が極めて高いエリア |
| J. 地方の大家族・シニア | 郊外や地方に見られる大家族やシニア世帯。3世代家族と老夫婦が混在し、一部では過疎化が進むエリア |
| K. 農村 | 農業などの一次産業従事者が大半を占め、55歳以降の2人暮らしや親子世帯が多い。人口密度が最も低い過疎化エリア |
ECの顧客住所や実店舗のID-POS購買データをこの「c-japan® Home」と重ね合わせることで、「自社商品がどのクラスターの生活スタイルや年収層に最も売れているか」を鮮明にプロファイル化できます。例えば「G. ニューファミリー」層への売上が高いことが判明すれば、その層の価値観に合わせた商品パッケージの開発や、そのクラスターが多く分布する町丁目へのピンポイントなチラシのポスティング、Web広告のジオターゲティング配信など、営業・販促活動を大幅に最適化することが可能になります。
c-japan® Daytimeの活用
居住特性を捉えるHome版に対し、ビジネス街や繁華街の特性に特化して昼間人口を可視化したのが「c-japan® Daytime」です。従来の夜間人口データだけでは見落とされてきた、日中にそのエリアに集まる「働く人」や「遊ぶ人」のニーズを町丁目単位で捉え、日本全国を7つの中分類と22の小分類にクラスタリングしています。
| 中分類クラスター | 含まれる小分類(サブセグメント)の例と昼間エリアの特性 |
|---|---|
| A:都心 | 【A1中枢ビジネス街】【A2広域ハブ】 経済活動が極度に集中し、30〜50代のビジネスワーカーが大部分を占める。BtoBサービスや高所得者向けサービスのポテンシャルが最大となる「働くための街」 |
| B:リージョナルセンター | 【B1リージョナルセンター】 地方中核都市の中心部や副都心。百貨店や行政機関が集積し、広域からの来街者と生活者のバランスが取れた地域活動の中心地 |
| C:ウィメンズエリア | 【C1ウィメンズ・トラディショナル】【C2ウィメンズ・アクティブライフ】 女性向けの商業・サービス業が発展し、昼間人口における女性比率が突出して高いエリア |
| D:メンズエリア | 【D1メンズ・アーバンセンター】【D3メンズ・産業物流ゾーン】など 工場・物流センター・大規模オフィスなど、男性就業者が大半を占めるエリア。ボリューム重視の飲食需要や特定産業向けニーズが高い |
| E:学生エリア | 【E1アカデミックタウン】【E2キャンパス】など 大学や高校が集積し、10代後半から20代の若者が昼間人口の主体を占める。学生生活に密着した安価なサービスが求められる |
| F:ファミリー郊外 | 【F1都心近郊ニューライフ】【F4ファミリー・トラッド郊外】など 日中は子どもや主婦(主夫)が多く滞在し、ファミリー向けの日常消費や教育・レジャー需要が高いベッドタウン |
| G:シニア郊外 | 【G1シニア・モダンリビング】【G4後期高齢者コミュニティ】など 日中の在宅率が高く、健康・趣味・生活支援に関心の高い中高年〜高齢者が活動の中心となるエリア |
店舗開発において、このデータを活用することで立地に合わせた業態選択の精度が飛躍します。例えば、昼間の顔が「D3:メンズ・産業物流ゾーン」であるエリアへの出店であれば、提供スピードとボリュームを重視したランチ業態が適していることをデータから論理的に導き出せます。また、「c-japan® Home」と「c-japan® Daytime」の2つのデータを複眼的に組み合わせることで、昼と夜で全く異なる顔を持つエリアの真のポテンシャルを見極め、時間帯別マーチャンダイジング(MD)を高度化することも可能です。

4. 商圏分析でのクラスター分析活用例
類似商圏の抽出
多店舗展開における新規出店の成功確率を最大化するアプローチとして、「既存の高収益店舗と類似した環境を持つ未出店エリア」を発見する手法があります。
数十から数百に及ぶエリア変数(人口動態、富裕度、世帯構成、競合店密度など)を投入して全国の町丁目をクラスタリングし、ターゲットとなる成功店舗が属する商圏クラスターを特定します。その後、まだ自社が進出していない地域から同一クラスターのエリアを抽出することで、担当者の土地勘や主観に依存しない、全国規模でのポテンシャルエリアの発掘が実現します。
売上上位店舗群の分析
既存店舗全体の底上げを図るためには、「なぜ特定の店舗が売上上位に位置しているのか」を科学的に解明する必要があります。売上上位店舗群にクラスター分析を適用することで、成功の要因が単一ではないことが可視化されます。
例えば、あるクラスターは「競合がほぼなく、車で広域から来店するシニア層のまとめ買い需要を独占している」ことが要因であり、別のクラスターは「激戦区だが、圧倒的な昼間ビジネス人口(c-japan® DaytimeのA分類)を背景に、平日ランチタイムの回転率が極端に高い」ことが要因、といった具合に成功の類型化が行われます。成功要因の異なるクラスターごとに適切なKPIを設定し、重回帰分析による予測モデルを構築することで、既存店舗の改装判断やスクラップ&ビルド(既存店を閉鎖して新業態に建て替える戦略)の判断を精緻化することが可能になります。
人流データを活用したエリア分類
スマートフォンのGPSや基地局データをもとにした人流データとクラスター分析を組み合わせることで、静的な統計データ(国勢調査など)だけでは捉えきれない「街の動態」に基づくエリア分類が可能となります。c-japan® Daytimeのような昼間人口セグメンテーションは、人々の移動目的や性年代の偏りを精緻に捉えるため、実態に即したインサイトを提供します。
例えば、あるエリアが「C2:ウィメンズ・アクティブライフ(新しい消費に積極的な女性が集まるエリア)」に分類された場合、消費財メーカーの営業企画担当者はそのエリア内のドラッグストアやGMS(総合スーパー)に対し、トレンドの美容商材や高単価なコスメティック製品の棚割りを提案するロジカルな根拠を得ることができます。人流データをもとにした動的なクラスター分類は、出店計画にとどまらず、日々の店舗運営やMD戦略を根本から変革する力を持っています。
出店候補地評価
店舗開発部門における物件の一次審査プロセスにクラスター分析を組み込むことで、属人的な評価への依存を脱却し、判断基準の標準化と迅速化を図ることができます。新たな出店候補地の情報が持ち込まれた際、その指定地点を中心とする商圏データを即座に集計し、自社の既存店舗のどのクラスターに合致するかを判定します。
所属するクラスターが特定されれば、そのクラスター専用に構築された売上予測モデル(重回帰分析など)にデータを代入することで、客観的な「予測売上高(店舗のポテンシャル)」を算出できます。この予測値と自社の投資回収基準を照らし合わせることで、出店の可否を論理的に判断できるようになり、開発担当者の負担軽減と組織としての意思決定スピードの向上に貢献します。
5. クラスター分析に必要なデータ
クラスター分析の精度と、そこから導き出されるインサイトの質は、投入するデータの量と多様性に依存しています。商圏や店舗を正確に分類するためには、以下のような多角的なデータを収集・整備することが不可欠です。
人口統計
あらゆるエリアマーケティングの基礎となるのが、国勢調査をはじめとする公的な人口統計データです。年齢・性別、世帯人員、住宅の所有形態(持ち家か賃貸か)など、約350項目に及ぶデータが地域の潜在需要を測る土台となります。さらに、2015年から2045年までの性・年代別将来人口推計データや、家計調査年報に基づく約600品目の年間消費支出額、年収階級別の世帯数データを組み合わせることで、現在の規模だけでなく、将来の市場の持続可能性やエリアの富裕度を含めた動的なクラスタリングが可能になります。
人流データ
昼夜の人口変動や特定時間帯における滞留を捉えるためには、人流データが必要です。通勤・通学による流動人口や、特定の商業施設への来訪者の居住地を推定するデータは、商圏の「実際の広がり(実勢商圏)」を定義するうえで重要です。国勢調査が示す「そこに住んでいる人」という静的な潜在需要に対し、人流データは「今、そこにいる人」という動的な実需要を可視化し、クラスター分析の解像度を引き上げます。
POSデータ
企業が独自に保有するID-POSデータなどの購買履歴は、消費者の実際の行動結果を示す信頼性の高いデータです。どの商品が、いつ、誰に、どれだけ売れたかという詳細なデータと、前述の人口統計や人流データから導かれたエリアセグメント(c-japan®等)を結合することで、「特定の居住特性を持つクラスターにおいては、特定商品の購買確率が有意に高まる」という実用的なマーケティングルールを発見することができます。これはメーカーから小売業へのデータドリブンな販促提案の源泉となります。
競合データ
商圏の質や店舗のポテンシャルは、競合の存在によって相対的に変化します。そのため、競合店舗の位置、数、業態、売り場面積といったデータを変数としてクラスター分析に組み込む必要があります。商圏分析ツールに搭載されている「グラビティモデル(ハフモデルの発展版)」などを活用し、店舗間の顧客吸引力や競合の距離的影響度を加味することで、「自社が勝てる余地のある集積地」を見極めるための精緻な分類が可能になります。
- 補足:ハフモデルとは
- 商圏内の顧客が各店舗に来店する確率を、店舗規模(魅力度)と距離をもとに算出する確率論的な商圏モデルです。グラビティモデルはその発展版です。
GISデータ
多種多様なデータを「空間」という共通プラットフォーム上で統合・処理するための基盤となるのが、GIS(地理情報システム)データです。町丁目やメッシュといったポリゴンデータ(地図上の面的な区域データ)、道路網・鉄道網などの空間情報があって初めて、住所情報を持つ顧客POSデータや店舗データを地図上に正確にプロットし、任意の商圏範囲(円商圏や自動車での到達圏など)を設定してデータを高速に集計・抽出することが可能になります。GISデータは、無味乾燥な数値の羅列を視覚的で意味のある地理的インサイトへと変換する役割を担っています。
6. クラスター分析を行う際の注意点

クラスター分析は強力なツールですが、データを投入すれば自動的に完璧な答えが出力される魔法の箱ではありません。分析の前後における「人間の判断と前処理」が成否を決定づけます。
変数選定
分析に投入する変数(データ項目)を無計画に増やすことは、かえって分類の精度を低下させる原因となります。特に注意すべきは「多重共線性」という統計的な問題です。
- 補足:多重共線性とは
- 投入した複数の変数が互いに強く相関している状態のことです。例えば「世帯総数」と「単身世帯数」のように関連性の高い変数を同時に投入すると、その特徴が二重に評価されてしまい、特定の要素に過度に偏ったクラスターが形成されてしまいます。
この問題を回避するためには、事前に「主成分分析(多数の変数を少数の無相関な合成変数に要約する手法)」などを用いて変数を縮約するプロセスを挟むことが推奨されます。情報の損失を最小限に抑えつつノイズや相関の強い変数の影響を排除することで、精度の高いクリーンなクラスタリングを実行できます。
標準化
異なる単位や尺度のデータを同時に扱う場合、データの「標準化(正規化)」は必須の処理です。k-means法などのアルゴリズムはデータ間の距離をもとに類似度を計算するため、例えば「人口(数万人単位)」「世帯年収(数百万円単位)」「競合店舗数(数件単位)」をそのまま投入すると、数値のスケールが大きい人口や年収だけで分類が決まってしまい、競合店舗数の違いという重要な要素が無視される事態になります。
各変数の平均を0・分散を1に変換する「Zスコア変換」などの標準化処理を行うことで、単位の異なるすべての変数が平等な影響力を持つように調整し、多角的な視点が正しく反映された分類結果を得ることができます。
クラスター数の決定
k-means法などの非階層型クラスター分析において、「クラスター数(k)をいくつに設定するのが最適か」という問いに絶対的な数学的正解はありません。エルボー法やシルエット分析といった統計的な指標は参考にはなりますが、それに盲従することはビジネス上危険です。
- 補足:エルボー法・シルエット分析とは
- エルボー法とは、クラスター数を増やしていったときのデータのばらつき(誤差)の変化をグラフ化し、減少幅が急に小さくなる「肘(エルボー)」の点を最適なクラスター数と判断する方法です。シルエット分析は、各データがどれだけそのクラスターにふさわしいかをスコア化したものです。
最も重要な判断基準は「導き出された分類が、ビジネス上の具体的なアクション(施策)に落とし込める数かどうか(運用性の確保)」です。全国の店舗を100クラスターに分類すれば精緻さは増しますが、現場の営業部門が100種類のMD戦略を同時に実行・管理することは現実的に不可能です。逆に2クラスターでは大雑把すぎて分析の意義が失われます。自社の組織体制、MDのパターン数、予算の制約などを考慮したうえで、戦略的に運用可能かつ差異が明確になる数(例えば5〜10程度)に設定することが実務において最も効果的なアプローチです。
解釈性の確保
アルゴリズムが出力する結果は、単に「グループ1」「グループ2」という無機質なラベルと平均値の集合体に過ぎません。その数値の偏りを読み解き、生きた顧客ペルソナや地域特性を見出し、人間が理解できる「名前(ネーミング)」を与えるプロセス(解釈)こそが、分析担当者の最大の腕の見せ所です。
例えば、「未成年人口比率が高く、世帯年収が平均的で、新設住宅着工数が多いグループ」という無機質な結果に対し、「マイホーム予備軍・ニューファミリー層」という直感的なネーミングを与えることで、初めてマーケティング部門や開発部門の共通言語として機能するようになります。クラスターの背後にある「Why(なぜこのデータが集まっているのか)」の文脈を言語化できなければ、どれほど高度な分析も組織を動かす推進力にはなり得ません。
7. GISを活用したクラスター分析
ここまで述べてきた複雑なデータ処理、変数の集計・標準化、高度な多変量解析を、専門のデータサイエンティストが不在の環境であっても直感的かつ高精度に実行可能にするのが、GISと統合された専用のエリアマーケティングツールです。
MarketAnalyzer® 5のクラスター分析機能
技研商事インターナショナルが提供する「MarketAnalyzer® 5」は、国内2,000社以上への導入実績を通じて培われたノウハウに基づき開発された、商圏分析・エリアマーケティングGISのソフトウェアです。属人的な経験や勘に依存した店舗開発から脱却し、再現性の高い立地戦略を実現するための高度な機能群を搭載しています。
本システムには「店舗クラスター分析機能」が標準で組み込まれており、自社の店舗を売上などの「実績データ」や国勢調査などの「商圏データ」、あるいはその両方の組み合わせを用いて柔軟にクラスタリングできます。これにより、膨大なチェーン店舗網を立地環境や売れ筋傾向に基づいて迅速に分類し、グループごとの特性を俯瞰的に把握することができます。
さらに、多重共線性を回避してデータを要約する「主成分分析」や、複数の変数から最適な組み合わせを自動的に選択して精緻な予測式を構築する「重回帰分析(ステップワイズ法推奨)」など、高度な多変量解析のフルセットがシームレスに連携して機能します。構築された予測売上高と実際の売上高を比較することで、既存店舗のポテンシャル評価や業態転換の判断もデータに基づいて行えます。
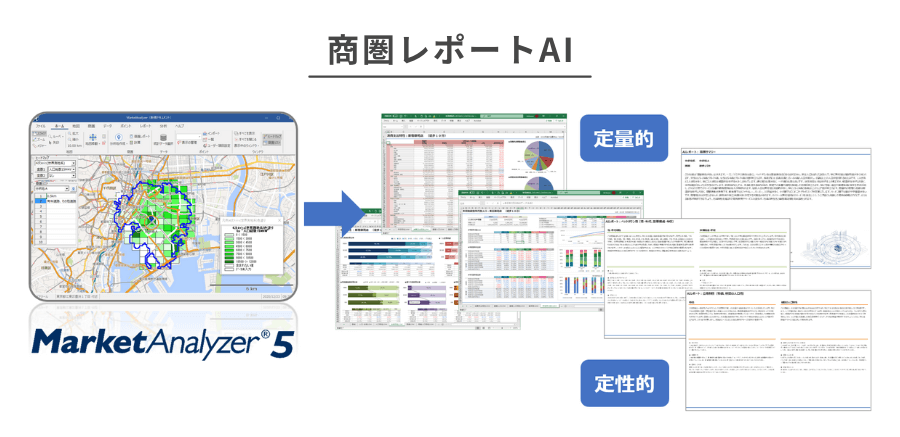
また、最新のAI技術を活用した「商圏レポートAI」機能を搭載しており、指定エリアの居住者の特徴・富裕度・消費傾向といったクラスターの特徴を生成AIが自動で要約・テキスト化し、Excel形式のレポートとして出力することが可能です。これにより、分析結果の解釈や社内向け報告資料の作成にかかる工数を大幅に削減し、組織全体のDX化とデータドリブンな意思決定を後押しします。競合店への来訪者を可視化する特許技術「仮想ペルソナ分析」や「c-japan®」シリーズのデータ連携と組み合わせることで、クラスター分析の真価を最大限に引き出す分析環境を提供します。
8. まとめ

消費者の行動様式が多様化・複雑化し、店舗立地や商圏の概念が絶えず変容を続ける現代において、単一のデータポイントや属人的な直感に依存した意思決定は企業にとって大きなリスクを伴います。クラスター分析は、膨大なデータの中に潜む「目に見えない法則性」を紐解き、複雑な市場を戦略的にコントロール可能な単位に整理するための強力な羅針盤となります。
店舗開発においては、類似商圏の網羅的な抽出や精緻な売上予測モデルの構築を通じて、「出店リスクの最小化」と「成功の再現性の担保」を実現します。消費財メーカーの営業企画においては、昼夜の人口動態やエリアの居住特性に合致した「客観的根拠のある棚割り提案」や「プロモーションの最適化」を可能にし、リテールパートナーとの信頼関係と売上最大化に貢献します。
最も重要なことは、分析手法そのものを目的化するのではなく、高度な統計アルゴリズムと「MarketAnalyzer® 5」のような実践的なGISツールを掛け合わせ、そこから導き出された客観的なインサイトを日々のマーチャンダイジングや販促企画・出店判断という具体的なアクションへと迅速に接続することです。データという共通言語を基盤とした透明性の高い意思決定プロセスを構築することが、激化する競争環境において持続的な成長を描くための確固たる道筋となります。
監修者プロフィール
市川 史祥
技研商事インターナショナル株式会社
取締役CMO シニアコンサルタント 市川 史祥
一般社団法人LBMA Japan 理事
ロケーションプライバシーコンサルタント
流通経済大学客員講師/共栄大学客員講師
統計士/医療経営士/介護福祉経営士
Google AI Essentials/Google Prompt Essentials

1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



