業界の最新動向をチェック
エリアマーケティングラボ
トレンド
売上予測とは?|予測モデルより重要な『データ処理』の話
2026/01/21
2026年1月23日号(Vol.212)

近年、AIや機械学習を活用した売上予測への期待が高まる一方、「予測精度が上がらない」「根拠を説明できない」「現場感覚と乖離する」といった失敗例も少なくありません。こうした問題は、アルゴリズムの選択以前の工程に原因があります。
当社は長年の商圏分析・GIS活用支援を通じて、売上予測の精度を決める最大要因はモデルの高度さではなく、投入前のデータ処理の質であると確信 しています。
適切な前処理や特徴量エンジニアリングを行わなければ、最新の機械学習モデルでも有効な予測は得られません。一方でビジネス文脈を反映したデータ加工ができれば、従来の統計手法でも高精度な予測が可能です。
本コラムでは、数式やモデル調整ではなく、予測精度の大半を左右する「データ前処理」に焦点を当てます。小売・飲食業の実データをいかに整理・加工し、分析可能な情報へと昇華させるか。当社の新サービス「THE NOVEL」の思想的基盤となるデータ処理の考え方を、具体例とともに解説します。
売上予測 とは:定義と昨今の課題
予測の難しさと「商圏」の複雑性
小売・飲食における売上は、極めて多面的な要因の相互作用によって決まります。
需要サイド(商圏):居住者の人口、年齢構成、世帯年収、ライフスタイル、昼間人口、交通量。
供給サイド(競合・自社):競合店の数と質、自社店舗の面積、視認性、駐車場の入りやすさ、ブランド力。
環境要因:天候、季節性、経済状況、地域イベント。
これら無数の変数が絡み合う中で、「売上予測」を行うことは、カオスの中から秩序を見つけ出す作業に他なりません。例えば、「駅前」という立地一つとっても、都心のターミナル駅と地方の駅では、そこを行き交う人々の購買意欲や目的は全く異なります。また、同じ「30代男性」でも、オフィス街のランチ需要と、住宅街の休日需要では行動パターンが逆転することさえあります。

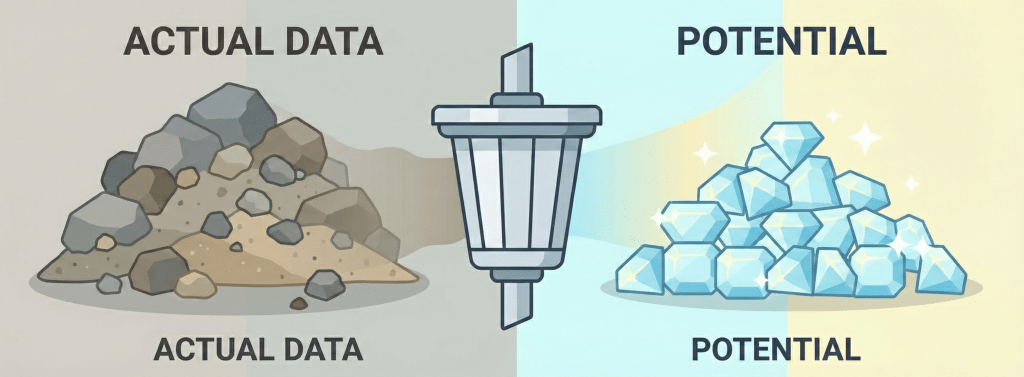
実績予測とポテンシャル評価の違い
ここで重要な概念的区別があります。それは「実績予測」と「ポテンシャル評価」の違いです。
実績予測:過去のデータに基づき「実際にいくら売れるか」を予測する。オペレーションや店長の能力によるバラつきも含まれる。
ポテンシャル評価:その立地が本来持っている「理論上の最大売上」を推計する。
優れたデータ処理は、ノイズである「店長の能力」や「一時的なキャンペーン効果」と、シグナルである「立地の力」を分離することを可能にします。これにより、売上予測は本来の出店戦略、出店判断に生かすことができるようになるのです。
予測方法のトレンド:統計学と機械学習
具体的なデータ処理の話に入る前に、現在主流となっている2つの予測エンジン(モデル)について整理します。どちらのエンジンを採用するかによって、必要となる「燃料(データ)」の精製方法(前処理)が異なるからです。
① 統計解析:重回帰分析
古くからマーケティングのリサーチ現場で標準的に用いられてきた手法です。
売上(目的変数)を、複数の要因(説明変数 X_1, X_2,...)の足し算と掛け算で説明しようとします。
特徴:「線形性」を仮定します。つまり、「人口が増えれば売上も比例して増える」という直線的な関係を前提とします。
メリット:「説明可能性」が極めて高いこと。「駅徒歩分数が1分縮まると、売上が50万円上がる」といった係数の解釈が容易で、社内稟議やFCオーナーへの説明に適しています。
デメリット:現実は直線ではありません。「徒歩5分までは売上が高いが、10分を超えると急激に下がる」といった非線形な関係や、変数同士の複雑な絡み合いを捉えるのが苦手です。また、データの分布に対する前提条件(正規性など)が厳しく、前処理の不備が致命的な精度低下を招きます。
② 機械学習:勾配ブースティング決定木
XGBoost、LightGBM、CatBoostなどに代表される、現在のデータサイエンス実務における「最強の解」の一つです。多数の「決定木(Decision Tree)」を逐次的に生成し、前の木が間違えた誤差(残差)を次の木が修正していくことで、驚異的な予測精度を実現します。
特徴:「非線形性」や「交互作用」を自動的に学習します。「もし駅近なら、駐車場がなくても売れる」「もし郊外なら、駐車場が必須」といった条件分岐を何層にも重ねて判断します。
メリット:圧倒的な予測精度。外れ値や欠損値にも比較的強く、生のデータをそのまま放り込んでもある程度機能します。
デメリット:「ブラックボックス化」しやすいこと。なぜその予測値になったのかを人間が直感的に理解するのが難しく(SHAP値などの解釈手法はありますが)、モデルの中身が複雑怪奇になりがちです。

どちらを選ぶべきか?
実務においては、「精度」と「説明責任」のトレードオフで選択されます。しかし、どちらの手法を選ぶにせよ、「データ処理」が不要になるわけではありません。
重回帰分析においては、データ処理は「必須要件(これがないと動かない)」であり、機械学習においては「差別化要因(これがあると精度が跳ね上がる)」となります。特に、競合他社も同じようなAIツールを使っている現在、差がつくのは「いかに自社ビジネス特有の知見をデータとして表現できるか(特徴量エンジニアリング)」にかかっているのです。
売上予測モデル構築フロー:データ処理の全体像
精度の高い予測モデルを構築するための「前捌き」のプロセスは、以下のフローで行われます。本レポートでは、特に「Step 3」と「Step 4」に重点を置きます。
1.データ収集
社内実績データと、「MarketAnalyzer®5」などの外部商圏データの結合。
2.データクレンジング
欠損値の補完、異常値の除去、名寄せ。
3.特徴量エンジニアリング
カテゴリ変数の数値化
交互作用項の作成
スコア化・合成
4.変数変換
スケーリング(標準化・正規化)
分布の補正(対数化)
構成比化

カテゴリ変数の処理:定性情報を「計算可能」にする
小売データには「数値ではない情報」が溢れています。「店舗タイプ(ロードサイド/インショップ)」「エリア(関東/関西)」「曜日」などです。これらはそのままでは数式に入らないため、数値への変換(エンコーディング)が必要です。
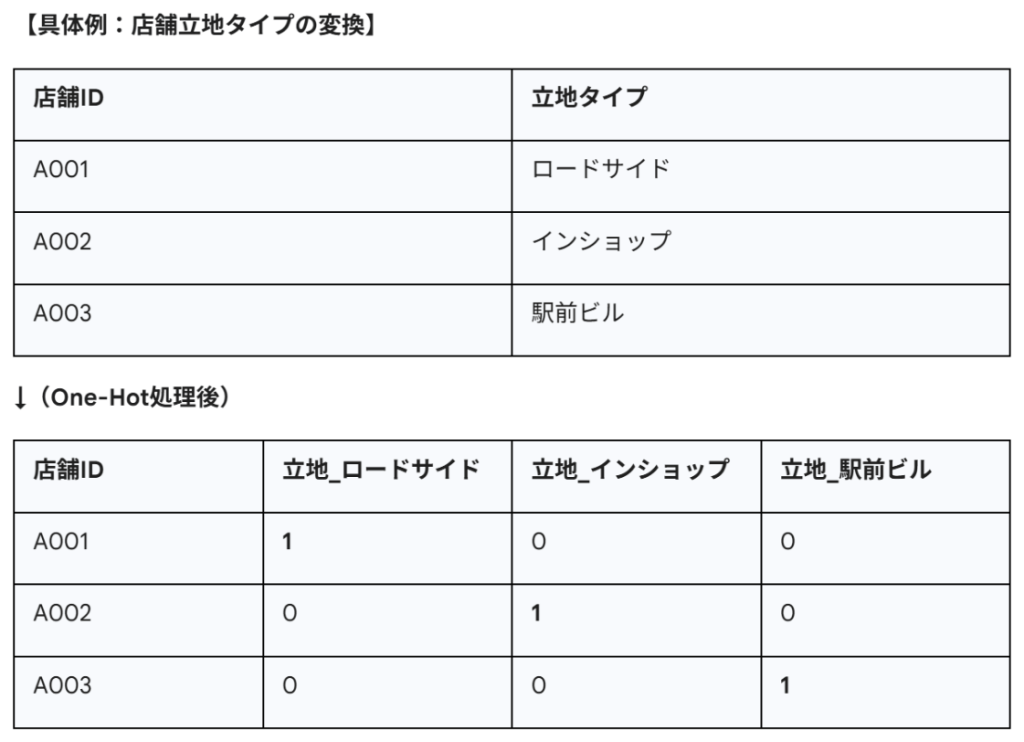
① One-Hot Encoding(ワンホットエンコーディング)
各カテゴリを独立した列(ダミー変数)に分解し、該当箇所にフラグ「1」を立てる手法です。
適用モデル:重回帰分析、ニューラルネットワーク、距離ベースのモデル。
処理の意図:カテゴリ間に順序関係(ランク)がないことをモデルに伝えます。「東京」と「大阪」は対等であり、どちらかが偉いわけではありません。
■ 重要ポイント
重回帰分析を行う際は「多重共線性(マルチコ)」を避けるため、N個のカテゴリがある場合、N-1個の列を作成し、1つをベースラインとして削除するのが定石です(ダミートラップ回避)。例えば、「駅前ビル」列を削除し、すべてのフラグが0なら「駅前ビル」であると解釈させます。
② Label Encoding(ラベルエンコーディング)
カテゴリ文字列を単純に整数値に置き換える手法です。
適用モデル:決定木ベースのモデル(XGBoost, LightGBM, Random Forest)。
処理の意図:データ容量を節約しつつ、決定木が「分岐条件」として使えるようにします。

■ 注意点
「北海道=1, 東京=13, 沖縄=47」のような都道府県コードをLabel Encodingして重回帰分析に入れてはいけません。「沖縄は北海道の47倍の影響力がある」という誤った数学的解釈が行われ、予測が崩壊します。しかし、決定木モデルであれば「IDが20以上か未満か?」という閾値で切るため、この手法でも有効に機能することが多いです。
スケーリングと分布補正:データの「縮尺」を整える
売上予測に使う変数は、単位がバラバラです。「商圏人口(数万人)」「店舗面積(数十坪)」「競合距離(数千メートル)」。これらをそのまま扱うと、数値の絶対量が大きい変数がモデルを支配してしまったり、学習が収束しなかったりします。
① 標準化
平均を0、標準偏差(分散)を1に揃える変換です。
適用モデル:重回帰分析、SVM、K-Means法、ニューラルネットワーク。
処理の意図:全ての変数を「平均からどれくらい離れているか(偏差値のようなもの)」という共通の物差しで比較可能にします。重回帰分析では、これを適用することで「標準偏回帰係数」が得られ、どの変数が売上に最も寄与しているか(感度)を直接比較できるようになります。
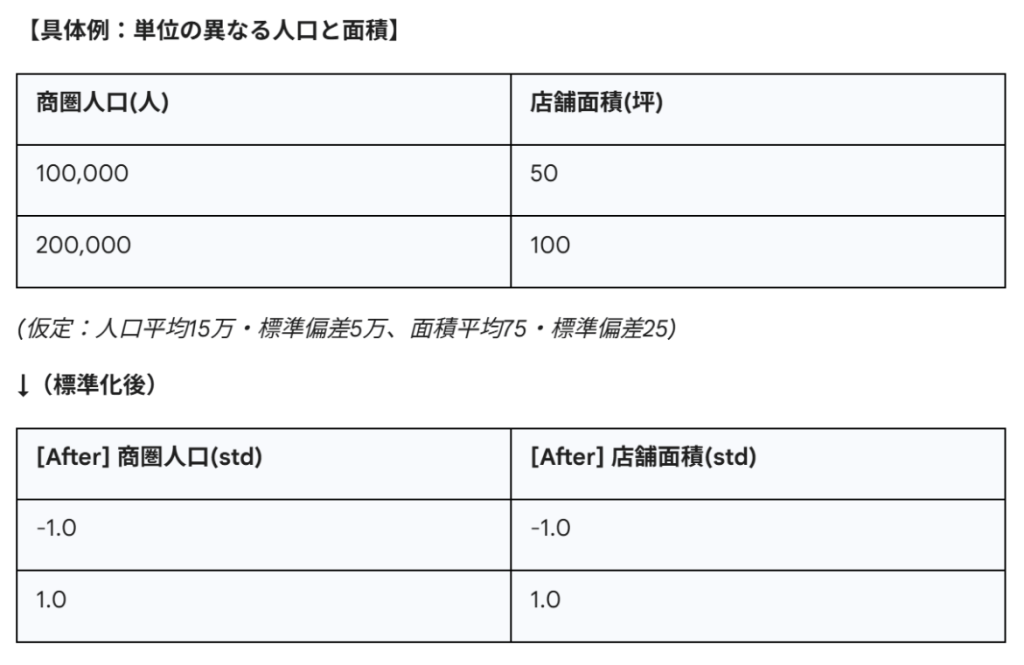
これにより、モデルは「人口」と「面積」を対等な重要度で評価し始めます。
② 正規化
データの範囲に圧縮します。
適用モデル:画像処理、距離計算に厳密性が求められるアルゴリズム。
注意点:外れ値(異常に巨大な売上を叩き出す旗艦店など)が含まれていると、その値が「1」になり、他の大多数の店舗が「0.001」付近に押し潰されてしまい、差が消滅します。小売データには外れ値がつきものなので、標準化の方が安全なケースが多いです。
③ 対数化(Log)
データの対数をとり、分布の歪みを矯正します。
小売・飲食データ(年収、人口密度、売上)は、正規分布(左右対称)ではなく、「対数正規分布(左に山があり、右に長い裾野がある)」をしていることがほとんどです。
適用モデル:重回帰分析(特に目的変数である売上に対して)。
処理の意図:
1.正規性の確保: 線形回帰モデルの前提条件である「誤差の正規性」を満たしやすくする。
2.非線形の線形化: 「売上は人口に対して指数関数的に増える(乗法モデル)」という関係を、線形モデル(加法モデル)で扱えるようにする。
3.スケールダウン: 100万円と1000万円の差(900万)と、1億と1億900万の差(900万)は、ビジネス的な意味合いが異なります。対数をとることで、比率的な差(何倍か)に着目させます。

生データでは30倍以上の開きがありましたが、対数化後は適切なレンジに収まり、モデルが富裕層エリアのデータだけに引きずられるのを防ぎます。
④ 構成比化
絶対数(Volume)ではなく、割合(Quality)に変換します。
処理の意図:「商圏の規模」と「商圏の質」を分離します。
「高齢者が1万人いる」という事実は、総人口10万人の都市(高齢化率10%)と、総人口2万人の過疎地(高齢化率50%)では全く意味が異なります。
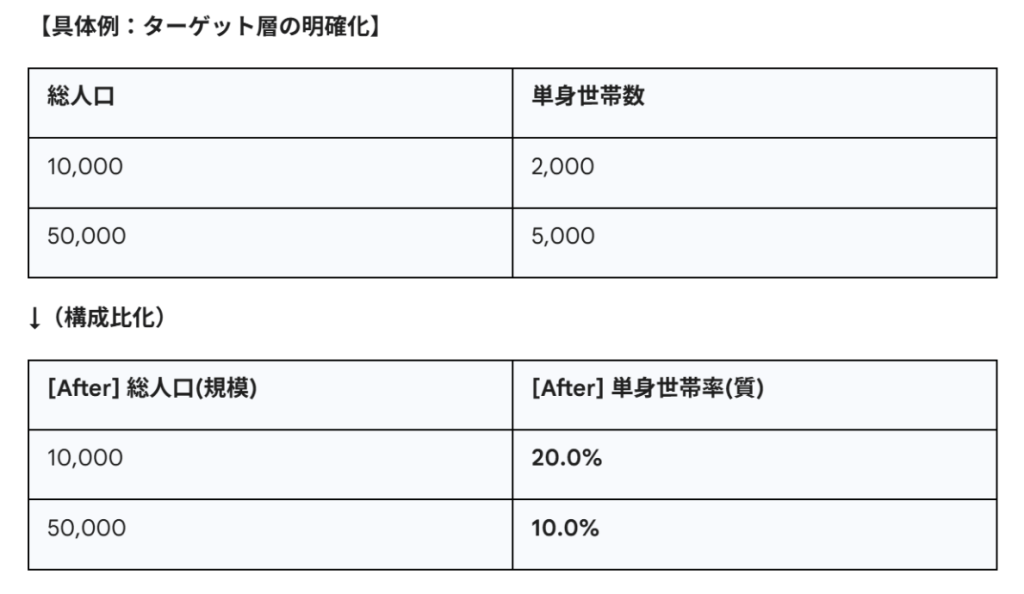
このように加工することで、モデルは「規模の大きさで売れるのか」「単身者が多いから売れるのか」を区別して学習できるようになります。
⑤ スコア化
ビジネスロジックに基づき、複数の変数を一つの指標に集約します。これは「特徴量」としてモデルに入れるだけでなく、KPIとして現場運用に乗せる際にも有効です。
商圏ポテンシャル指数:GIS(地図情報システム)上で計算される複雑な数値を、一つのスコアにまとめます。

生のデータでは「人口は同じ」に見える2つの商圏が、スコア化することで「天国と地獄」ほど違うことが明確になります。これをモデルに投入することで、予測精度は劇的に向上します。
高度な処理:ビジネスの「文脈」を埋め込む
ここからは、単なる整形を超えて、データに「意味」を与える高度な処理について解説します。ここがデータサイエンティストの腕の見せ所であり、競合他社との差がつくポイントです。
① 交互作用項
■ ビジネス背景
「全体の効果は部分の総和以上である(アリストテレス)」。
例1(シナジー): 「店舗面積」×「駐車場台数」
大型店(面積大)であればあるほど、駐車場の価値は高まる。
逆に、コンビニサイズの店に巨大な駐車場があっても、売上への寄与は限定的。
例2(価格弾力性): 「価格」×「競合店距離」
近くに競合がいる場合(距離小)価格を上げると客離れが激しくなるが、独占状態(距離大)なら価格が高くても売れる。
例3(天候影響): 「雨天」×「駅徒歩分数」
雨の日、駅直結店は売上が落ちませんが、徒歩10分の路面店は激減する。
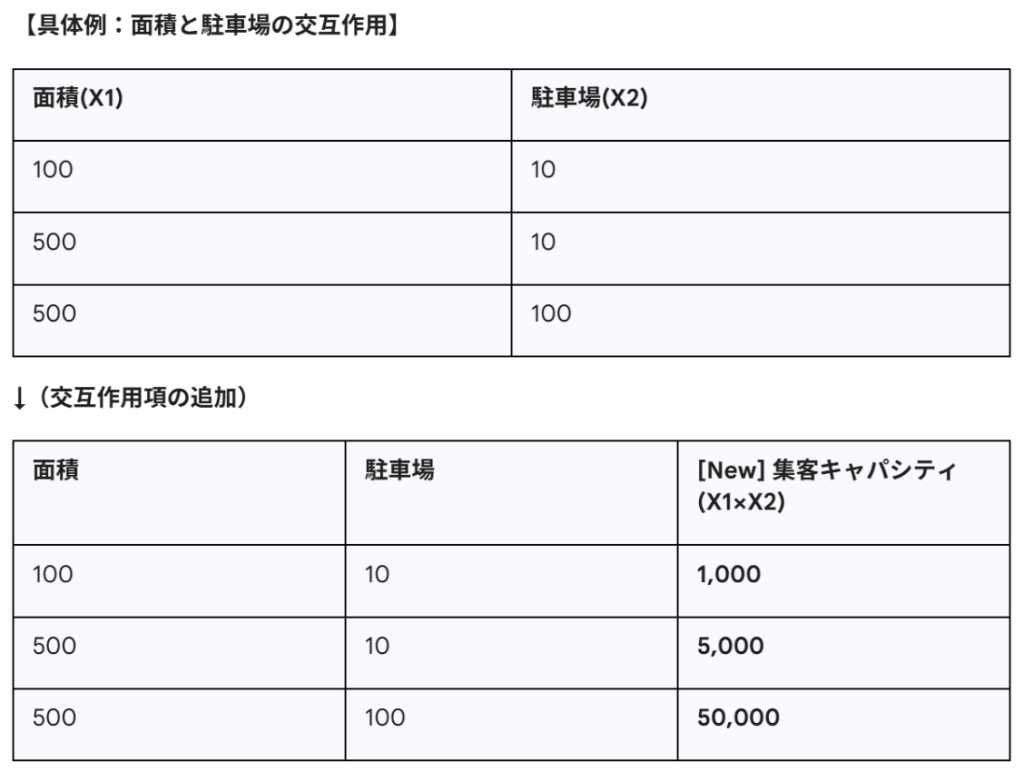
重回帰分析などの線形モデルは、デフォルトでは「X_1の効果」と「X_2の効果」を別々にしか評価できません。この「掛け算の項」を明示的に作って渡すことで、モデルに「駐車場付きの大型店こそが最強である」というインサイトを教えることができます。
② 合成(主成分分析 / 因子分析)
商圏データは、「20代男性」「30代男性」...「持ち家」「借家」...「製造業従事者」「サービス業従事者」といった具合に、数百種類もの変数が存在します。これらは互いに強い相関(似た動きをする)を持っており、そのまま全て重回帰分析に入れると「多重共線性」の問題でモデルが破綻します。
そこで、次元削減の技術を用いて、データの背後にある「隠れた構造」を取り出します。
数百の変数を、「主成分」や「因子」と呼ばれる少数の合成変数に要約します。
■ 目的
1.ノイズの除去:変数間の重複情報を削ぎ落す。
2.解釈性の向上: 人間が理解しやすい「意味の塊」を作る。
3.多重共線性の回避:無相関な変数を生成し、回帰分析を安定させる。
■ 小売における因子の例
因子1「都市化度」:地価が高い、人口密度が高い、借家率が高い、単身者が多い。
因子2「ファミリー度」:持ち家率が高い、子供人口が多い、車保有率が高い。
因子3「富裕度」:高額所得者が多い、大卒者が多い、管理職が多い。
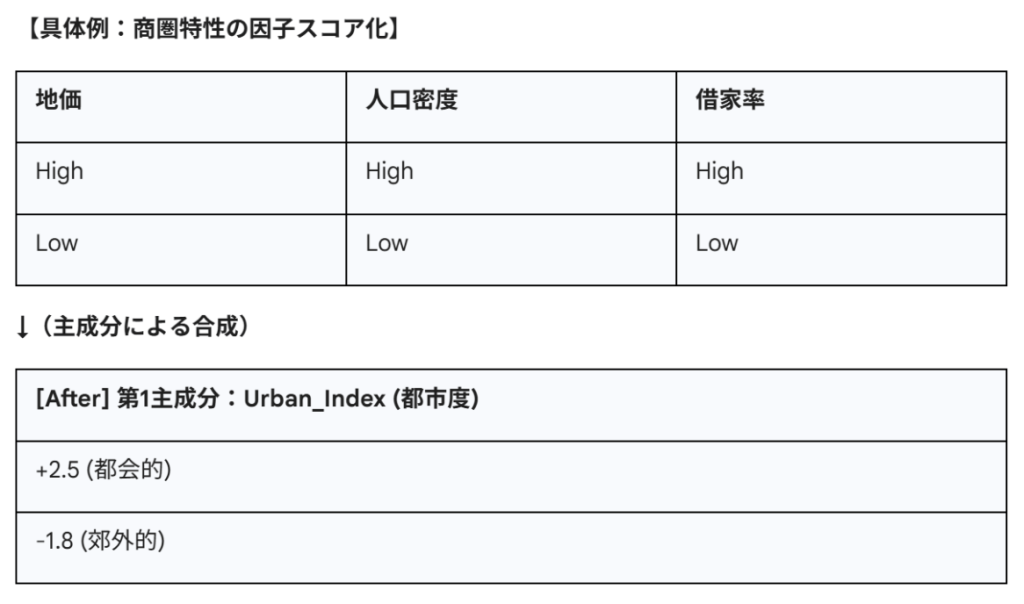
このように前処理しておけばモデルは個々の細かい人口統計変数に惑わされることなく、「この店は都市度が高いエリアほど売れる」という本質的なパターンを学習できます。これは機械学習よりも、特に解釈性を重視する統計解析において威力を発揮します。

2026年春、新サービス「THE NOVEL」始動
ここまで解説してきたデータ処理の工程——クレンジング、カテゴリ化、対数変換、交互作用の検討、そしてPCAによる因子抽出。これらは理論的には正しくとも、実務の現場で実行するには膨大な時間と、高度な専門知識(統計学、プログラミング、GIS操作スキル)を要求します。
「理論はわかったが、エクセルでは限界だ」
「データサイエンティストを雇う予算はない」
「商圏データを揃えるだけで数百万かかる」
こうした現場の切実な声に応えるべく、私たち技研商事インターナショナルは、創業以来蓄積してきた商圏分析のナレッジと、最新のAI技術を融合させた次世代サービスを開発しています。
それが、2026年春リリース予定の「THE NOVEL」です。
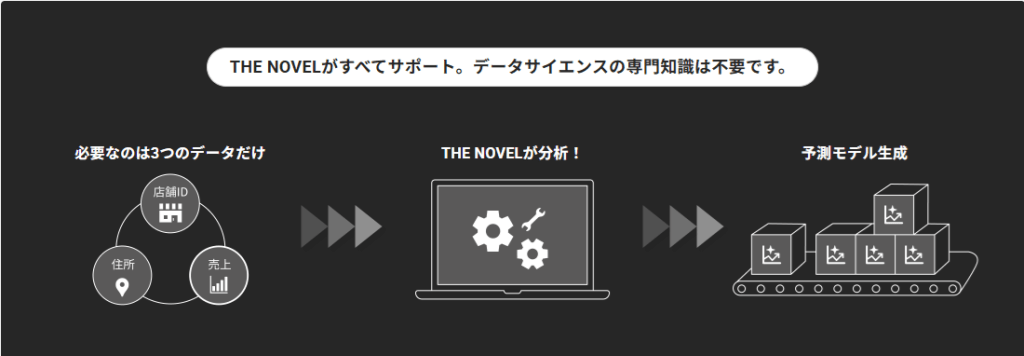
「THE NOVEL」が実現する世界観
「THE NOVEL」は、単なる自動予測ツールではありません。本レポートで詳述したような「熟練分析官の思考プロセス(データ前処理の暗黙知)」をAIが再現・代行するプラットフォームです。
1.自動特徴量エンジニアリング
ユーザーが
店舗の住所と売上実績を入れるだけで、背後にある膨大なGISデータベースから「商圏データ」を自動付与
。さらに、「都市化度」「競合プレッシャー」といった高度な合成変数をAIが自動生成
し、モデルに最適化された形で投入します。人間が交互作用項の組み合わせに悩む必要はありません。
2.ポテンシャルベースの店舗評価
「THE NOVEL」は、過去の実績をなぞるだけではありません。「その立地なら、本来これくらい売れるはずだ」という商圏ポテンシャルを算出します。これにより、売上が低い店舗が「立地が悪い(不可抗力)」のか「運営が悪い(改善余地あり)」のかを瞬時に判別できます。
3.ホワイトボックスAI
予測結果に対して、「なぜこの予測値なのか」を、因子や構成比といった人間が理解できる言葉で説明します。経営層へのプレゼンテーション資料作成を、AIが強力にサポートします。
私たちは、データ処理という「科学」の部分を「THE NOVEL」というツールに任せることで、皆様が「どのような店舗体験を顧客に提供するか」「どの街にブランドの旗を立てるか」という、人間にしかできない「芸術」と「戦略」に集中できる未来を創りたいと考えています。

まとめ:モデルよりデータを、データより前処理を
本コラムを通じて、「売上予測」という営みが、単なる計算ではなく、データの泥臭い加工の積み重ねであることをお伝えしてきました。
カテゴリ変数は、モデルの性質に合わせてOne-HotかLabelかを選択する。
単位の異なる変数は、標準化・正規化で共通言語にする。
歪んだ現実は、対数化でモデルが理解できる形に整える。
単独では見えない文脈は、交互作用やスコア化で明示的に教え込む。
複雑すぎる変数は、PCAで「意味の因子」に圧縮する。
これらの「前捌き」こそが、予測精度の8割を決定づけます。そして、来るべき2026年、「THE NOVEL」はこのプロセスを民主化し、すべてのマーケターと開発担当者に貢献します。
監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員 マーケティング部 部長 シニアコンサルタント |
|
|
一般社団法人LBMA Japan 理事 ロケーションプライバシーコンサルタント 流通経済大学客員講師/共栄大学客員講師 医療経営士/介護福祉経営士 Google AI Essentials/Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



