業界の最新動向をチェック
エリアマーケティングラボ
ノウハウ
重回帰分析による売上予測の精度向上について
2019/04/02
月刊GSI 2018年8月号(Vol.86)
はじめに
昨今、売上予測や客数予測のモデル構築を外部の専門家に任せず、自社で内製化しようとしている企業が増えていると感じます。ひとえに、マーケティングやデータサイエンスの重要性がビジネスの世界でも認知されるようになったことが要因だと考えられるでしょう。
ただ、「試しに売上予測を始めてみたけれども、一向に良い予測モデルが作れない」、「予測精度を向上させたいが、どこに手を付ければいいのかわからない」という声を聞くのも現状です。
このような状況を受けて、聞き馴染みの良い「AI売上予測」等をキーワードに、予測ロジックを抽象化し、ブラックボックス化するような企業とそのコンサルタントも増えているような気がします。売上予測はそれを運用する企業が自らそのロジックや要素を説明できるものでなくてはなりません。流行に惑わされず、自社の分析レベルに合った手法を選択するべきでしょう。今回のマンスリーレポートでは、売上予測に採用されるロジックの中で、従来から用いられることが多い「重回帰分析」を取り上げ、売上予測を始めたばかりの企業様向けに、さらに予測精度を向上させるためのヒントを紹介します。
▶ エクセルを使った分析手法やマーケティングにおける活用事例は こちら
重回帰分析とは
ひとくちに売上予測といっても、様々なロジックや手法が存在します。「どんなデータを使いどんなロジックを用いるのが最適か」という問いに正解はなく、自社の状況を理解した上でトライアンドエラーを行わない限り、それを見つけ出すことはできません。
まずは実行のしやすさから、多変量解析の中でもメジャーな「重回帰分析」から始めてはいかがでしょうか。
重回帰分析は多変量解析の一つで、複数の要素とその組み合わせを使って売上や客数などの成果を予測する式を作成します。
重回帰分析の用語として、「予測したい成果」を「目的変数」、「成果に関係する複数の要素」を「説明変数」、「成果に関係する要素を組み合わせた予測式」を「予測モデル」と呼びます。
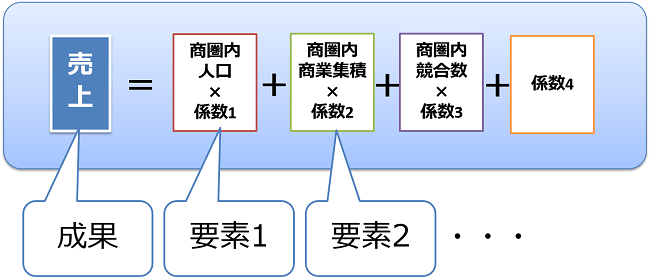
【重回帰モデルのイメージ】
売上予測モデルの構築
重回帰分析による売上予測モデルの構築は、目的変数として店舗ごとの売上データ等を、説明変数として店舗の属性項目や商圏データを用意してしまえば簡単です。チェーン店舗が売上予測モデルを構築する場合、以下のようなデータレイアウトとなります。
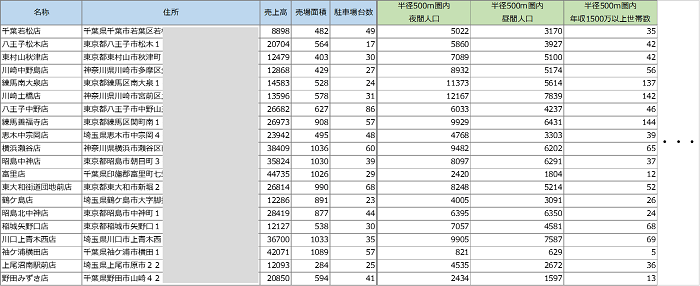
【重回帰モデルを構築するためのデータレイアウトイメージ】
モデルの作成自体は統計解析ソフトを用いることが一般的ですが、初めての場合はExcelを利用することをお勧めします。Excelにはもともと分析メニューの中に(重)回帰式を作成する機能が用意されています。モデルはExcelが自動的に計算して作成してくれるので、10分足らずで完成します。
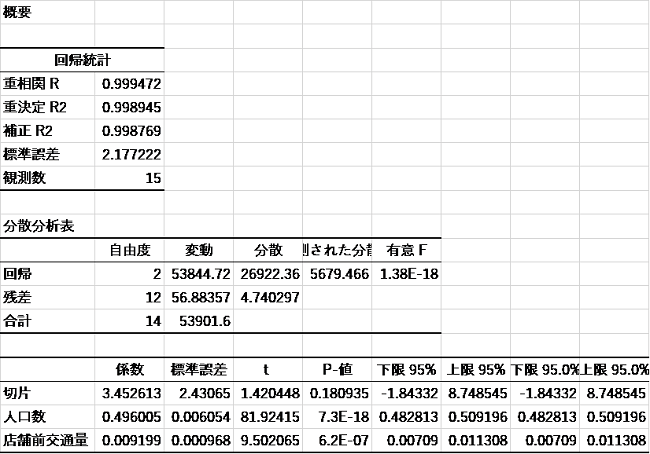
【Excelを用いた重回帰モデル構築結果の例】
ただ、単純に予測モデルを組み上げただけでは、予測モデルの精度はあまり高くないケースがほとんどです。店舗の売上を予測するためには説明変数として用いる各店舗それぞれのデータを用意することになりますが、膨大なデータの中からどの項目を用いて予測モデルを組み立てればよいのか、その組み合わせを考える必要があるからです。
説明変数の候補として用意される項目としては、「店舗面積」や「営業時間」、「店舗の視認性」、「店舗前の交通量」など店舗に関する立地情報から「商圏内居住人口数」や「商圏内昼間人口数」など商圏データも含めて、50項目~200項目程度が考えられます。
先のExcelを利用したモデル作成では、この組み合わせを逐一試さなければなりません。労力がかかり過ぎて現実的ではないため、重回帰モデルの構築を主眼とした専用システムを利用するのが理想的です。その場合、説明変数の組み合わせをアルゴリズムで探しますので、格段に効率的に運用できます。有名なアルゴリズムとしては、「ステップワイズ法」と呼ばれる説明変数の選択アルゴリズムがあります。これは、候補となる説明変数のうち、統計的な評価指標が高い組み合わせを自動で探し出してくれるものです。
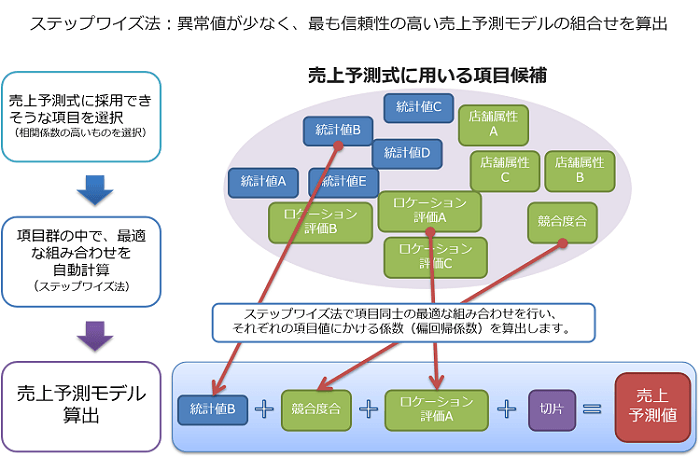
【ステップワイズ法のイメージ】
ただ、実際に運用に足る売上予測モデルとするためには式を作成しただけでは不十分です。予測モデルに組み込まれた説明変数に違和感はないか、統計学的な指標と照らして妥当性はあるか等、きちんと評価した上で、納得のいく内容であった場合に予測モデルが完成します。

精度向上のヒント① (売上予測モデルの評価指標)
構築された予測モデルの精度が良いのか悪いのか、その妥当性は統計学的に導き出される様々な指標を使って確認できます。既に運用している予測モデルの精度向上を図る場合にも、評価指標という数値で改善余地を把握することが重要です。
ご存知の方も多いとは思いますが、評価指標として最も代表的なものとして「決定係数(R2乗)」が挙げられます。決定係数とは、予測モデルの精度を表す指標であり、目的変数の動きが説明変数によってどの程度説明できているのかを表す数値です。実際の売上と予測した売上の相関係数の2乗で、0~1の値を取り、基本的には1に近いほど精度が良いことを意味します。ただし、説明変数の数やデータのサンプル数や分布など様々な要因に影響を受けるため、一概にどの程度であれば大丈夫だとは言えません。一般的な実感値としては0.6を越えていると一定の精度があると判断している企業が多いようです。
予測モデルに組み込まれた説明変数の数に応じて、評価を最適化させた「調整済み決定係数(R2乗)」という指標もあります。可能であれば、調整済み決定係数を確認することをお勧めします。

【決定係数の算出イメージ】
決定係数は最初に重視すべき指標ではありますが、それ一つでモデルの妥当性や正確性を完全に評価できるわけではありません。決定係数は予測モデル全体に対する評価ですが、予測モデルに使用した各説明変数を個別に評価する指標も確認してみましょう。それによって予測モデル内の不要な説明変数を探し出し、より精度の高い数式に近づけることができます。以下が各説明変数に対する代表的な評価指標です。
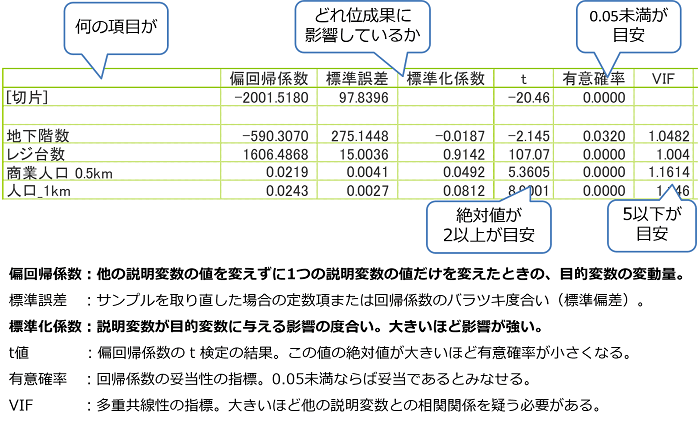
【説明変数に対する評価指標】
各評価指標を確認したら、新たな指標を追加したり、トライアンドエラーを行うなどして予測モデルの精度を向上させます。
具体的には、モデル構築 → 評価指標の確認 → 結果解釈 → 投入変数(要素)変更 → モデル構築 → 評価指標の確認 → 結果解釈 → 投入変数(要素)変更・・・という手順を繰り返します。
評価指標を確認して納得のいく数値になったら、やっと予測モデルが完成します。
しかし、その際には、経験から売上に関係していると考えられる「周辺の居住人口」などの商圏データが予測モデルに組み込まれていないこともあります。その場合は商圏データの数値をそのまま予測モデルに組み込むのではなく、項目を加工して分析に用いることが有効な場合が多くあります。
精度向上のヒント② (競合店舗を加味する)
項目を加工する際に最も一般的な方法として、競合店舗という要素を考慮した加工があります。例えば、郊外型スーパーなど明らかに周辺の居住人口が売上に直結している小売チェーン店舗の場合、単純な「商圏内の居住人口」だけではなく、競合を加味した「店舗吸引人口」を割り出し、重回帰分析に用いることが多くあります。自社店舗の商圏内に競合店舗が10店舗存在する場合と、1店舗も存在しない場合では、商圏内の状況は大きく変わります。各店舗の売上は競合の影響を受けるため、説明変数についても競合の影響を加味して分析する方が予測の精度が高まります。正確な売上予測には、単純な商圏データではなく実質的な商圏データを用い、競合店舗も加味する必要があります。
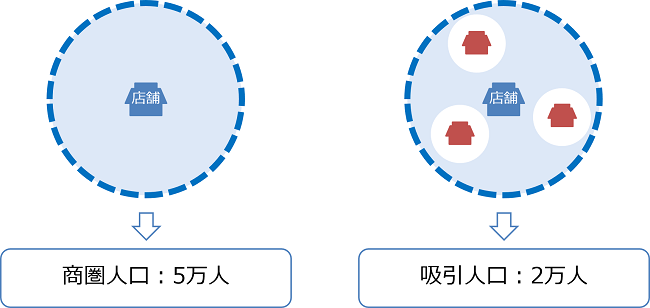
【競合を加味しない商圏人口と加味した吸引人口】
競合を加味する方法はいくつかありますが、一番簡単なのは、競合店舗数で平均を算出する方法です。例として、商圏内の居住人口数が5万人で、自社を含めた商圏内店舗数が5店舗なら、1店舗あたりの居住人口数は1万人です。簡単な算出方法ですが、何も加工していない項目よりも良い指標が見られる場合が多くあります。
さらに正確に各店舗と競合店舗の関係性を割り出すには、グラビティ分析(ハフモデル分析)を利用する方法があります。
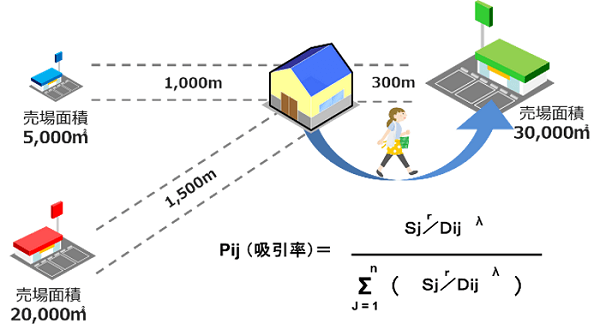
【グラビティモデル(ハフモデル)分析ロジック】
グラビティモデルとは、商圏内の各地域と各店舗の距離と各店舗が持つ魅力値を用いて、地域ごとの吸引率を算出するもので、実質的な値に近づけた商圏データを割り出すことが可能です。
これにより、ステップワイズ法で予測モデルに組み込まれなかった指標も、売上との関係性が見直され、採用されることがあり、予測モデルを向上させることができるようになります。下のイメージは、売上と商圏内世帯数の相関係数を、競合店舗を加味した場合としない場合とで比較したものです。
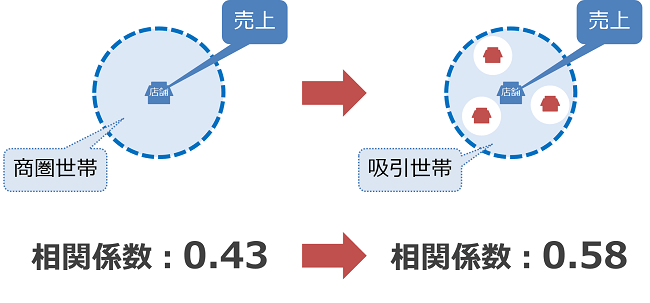
【競合を加味した場合の売上との相関係数の向上】
最後に
今回は売上予測モデルの精度向上についてポイントをご紹介しました。予測モデルは時間がたてば陳腐化するため、少なくとも年に1回程度、モデルを再構築することをお勧めします。売上予測を始められたばかりの企業も、過去の売上予測を使い続けている企業も、予測モデルをぜひ再構築してみてください。
予測モデルの再構築と改善にはどうしても時間と労力がかかりますが、システムをうまく用いることでそれを軽減して運用することができます。技研商事インターナショナルのGIS(地図情報システム)には重回帰モデル作成機能が搭載され、トライアンドエラーが行いやすい設計になっています。当社ウェブサイトにてご紹介していますのでご参照ください。

監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員 マーケティング部 部長 シニアコンサルタント |
|
| 医療経営士/介護福祉経営士 流通経済大学客員講師/共栄大学客員講師 一般社団法人LBMA Japan 理事 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



