業界の最新動向をチェック
エリアマーケティングラボ
ノウハウ
決定木分析とは?回帰分析との違いと予測・分類への応用
2025/09/17

2025年9月17日号(Vol.175)
データがビジネスの重要な指針となる現代において、機械学習は意思決定の精度を飛躍的に高めるための不可欠なツールです。しかし、数多あるアルゴリズムのなかで、その原理と結果を直感的に理解できる手法は限られています。その筆頭が「決定木分析」です。
決定木分析は、意思決定のプロセスを明確に可視化し、複雑なデータから導かれた結論の背景を誰もが理解できるようにする強力な手法です。本コラムでは、決定木分析の基本的な仕組みから、アルゴリズムの詳細、実践的な活用事例、そして他の主要な分析手法との比較まで、ビジネスの現場でデータ活用を推進する皆様に向けて、網羅的かつ実践的な視点から解説します。
🎧 このページの内容を音声で聞く:所要時間約19分 🎧
目次

決定木分析 とは?
決定木分析の基本概念
決定木分析は、データを木のような階層的な構造(ツリー構造)に整理し、予測や分類を行う機械学習の一手法です。これは、質問に「はい/いいえ」で答えていくと最終的な答えにたどり着く診断チャートに似ています。たとえば、「休日に外出するか?」を予測するために、「天気は晴れ?」「気温は25度以上?」といった質問を繰り返すことで、最終的な判断を下します。
この手法は、一連の条件分岐を繰り返すことで、最終的な結論へと至るプロセスをモデル化します。データから論理的な思考プロセスを自動的に学習し、再現することに非常に長けています。
決定木の強み:解釈性の高さ
決定木分析の最大の強みは、その解釈性の高さです。
多くの機械学習モデルが内部動作を人間が理解しにくい「ブラックボックス」であるのに対し、決定木は意思決定のロジックが明確に可視化される「ホワイトボックス」モデルです。これにより、「なぜその結論に至ったのか」を論理的に説明できるため、説明責任が求められる医療や金融などの分野で特に重宝されます。

「決定木」と「ディシジョンツリー」の違い
「決定木」を調べていると、「ディシジョンツリー」や「デシジョンツリー」という言葉を目にすることがあります。これらは基本的にすべて同じものを指しており、決定木を英語にした「Decision Tree」のカタカナ表記です。
決定木分析の基本的なステップ
決定木分析の進め方
決定木分析は、以下の4つのステップで進められます。
1. 目的設定とデータ準備: 「何を予測したいのか」という目的を明確にし、関連データを収集・整理します。
2. モデルの学習: 準備したデータ(訓練データ)を使って、決定木のモデルを作成(学習)させます。
3. モデルの評価: 作成したモデルが未知のデータ(テストデータ)に対しても正しく予測できるか、その精度を評価します。
4. 予測・分類の実行: 評価済みのモデルを使って、実際に新しいデータの予測や分類を行います。
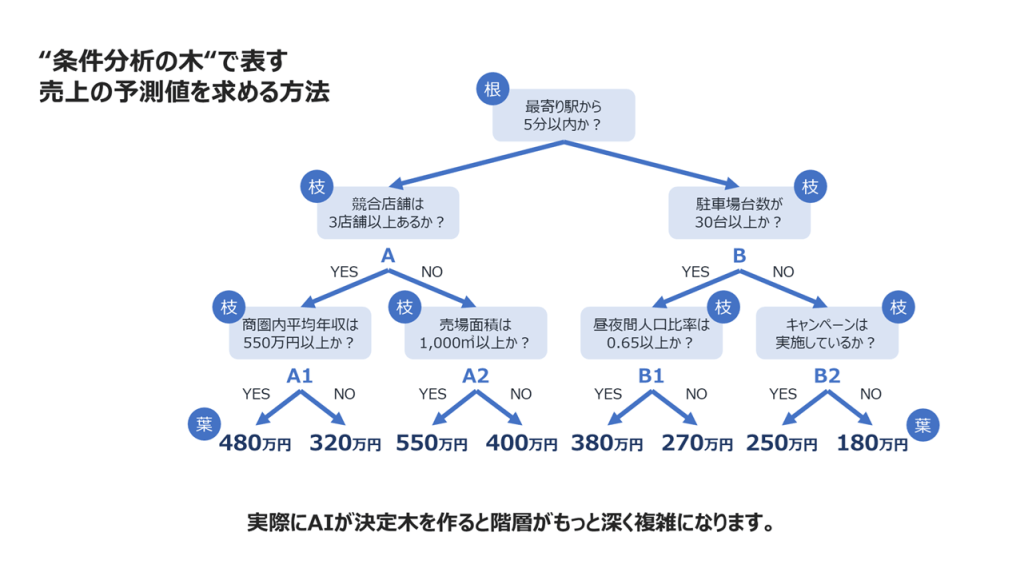
決定木の見方:ツリー構造が語るデータの傾向
決定木は以下の3つの要素で構成されます。
• 根(ルートノード): 分析の出発点であり、全てのデータが集約される場所です。
• 枝(ブランチ): データを分割するための条件分岐(質問)を表します。
• 葉(リーフノード): それ以上分割されない、最終的な予測結果や分類クラスです。
この構造において、根に近い位置にある枝(条件)ほど、目的変数の予測に与える影響が大きいと判断できます。これにより、決定木は単なる予測ツールとしてだけでなく、ビジネスにおける主要な成功要因や課題の根本原因を特定するための要因分析ツールとしても機能します。
目的別の種類:「分類木」と「回帰木」
決定木は予測の目的によって、以下の2つのタイプに分類されます。
• 分類木 (Classification Tree): 顧客が「購入する/しない」といった、データを特定のカテゴリに分類する場合に用います。質的な変数を予測するタイプです。
• 回帰木 (Regression Tree): 新規出店時の「売上予測」のように、具体的な数値を予測する場合に用います。量的な変数を予測するタイプです。
決定木分析のメリット・デメリット
メリット:結果の解釈が直感的でわかりやすい
決定木分析の最大のメリットは、なんといってもその結果のわかりやすさです。
・分析プロセスが可視化される
ツリー構造を見るだけで、どのような条件でデータが分類されたのかが一目瞭然です。専門家でなくても、ビジネスの現場で分析結果を共有しやすいという利点があります。
・重要な変数がわかる
ツリーの上位にある条件ほど、結果に与える影響が大きいと判断できます。これにより、どの要素が予測において重要なのかを直感的に把握できます。
・データの前処理が比較的容易
他の多くの機械学習手法と比べて、データのスケールを揃える(正規化など)といった前処理の手間が少ない傾向にあります。
デメリット:過学習に陥りやすい

一方で、決定木分析には注意すべきデメリットも存在します。過学習(か学習)とは、モデルが訓練データに過剰に適合してしまい、未知の新しいデータに対する予測精度が低くなってしまう現象のことです。
決定木は、データを完璧に分類しようとするあまり、訓練データにしか当てはまらない複雑なルールを作りすぎてしまうことがあります。その結果、汎用性の低いモデルになってしまうリスクがあります。この過学習を防ぐためには、木の深さを制限したり、「枝刈り」と呼ばれる調整を行ったりする必要があります。
決定木分析のアルゴリズム:不純度と過学習への対策
データが分岐する仕組み「不純度」とは
コンピュータは、データを分岐させるために「不純度」という考え方を利用します。不純度とは、あるデータ群の中に、どれだけ異なる種類のデータが混じり合っているかを示す指標です。
決定木のアルゴリズムは、データを分割した後の不純度が最も低くなるような条件を探し出します。この不純度を計算する代表的な指標には、ジニ不純度とエントロピーがあります。
• ジニ不純度 (Gini Impurity): 分類における誤り確率を直感的に示す指標で、計算が高速なため、広く用いられています。
• エントロピー (Entropy): 情報理論に基づき、データの不確実性を定量化する指標です。
代表的な決定木分析アルゴリズム:CARTとCHAID
決定木を構築するアルゴリズムには複数の種類があります。
• CART (Classification and Regression Trees): ジニ不純度または分散を指標とし、常に二分岐(「はい」/「いいえ」)でデータを分割する最も一般的なアルゴリズムです。
• CHAID (Chi-squared Automatic Interaction Detector): カイ2乗検定を用いて、多分岐のツリーを生成します。
決定木の最大の課題:過学習と剪定(プルーニング)
過学習を防ぎ、モデルの汎化性能を高めるためには、剪定(プルーニング)と呼ばれる手法が不可欠です。
• 事前剪定(停止基準): ツリーの成長を途中で止める方法です。
• 事後剪定: ツリーを最大限に成長させた後、予測性能に寄与しない枝を切り落としてモデルを単純化します。
決定木分析の具体例とビジネス活用事例
新規出店時の売上予測

決定木分析は、新規出店時の売上予測に活用できます。
1. データ収集: 既存店舗の売上データ(目的変数)に加え、店舗面積、従業員数、商圏人口、競合店の数など、売上に影響を与えうる様々な要因(説明変数)を収集します。
2. 回帰木の構築: 収集したデータを用いて回帰木モデルを構築し、売上という目的変数の分散を最小化するような条件分岐をツリー構造に配置します。
3. 予測と解釈: 完成したモデルに新規出店候補地のデータを入力すると、予測売上額が算出されます。さらに、このモデルは「商圏人口が5万人以上で、競合店が2店舗以下であれば売上は高くなる」といった具体的な意思決定ルールを提示します。
天候によるゴルフ実施可否の予測
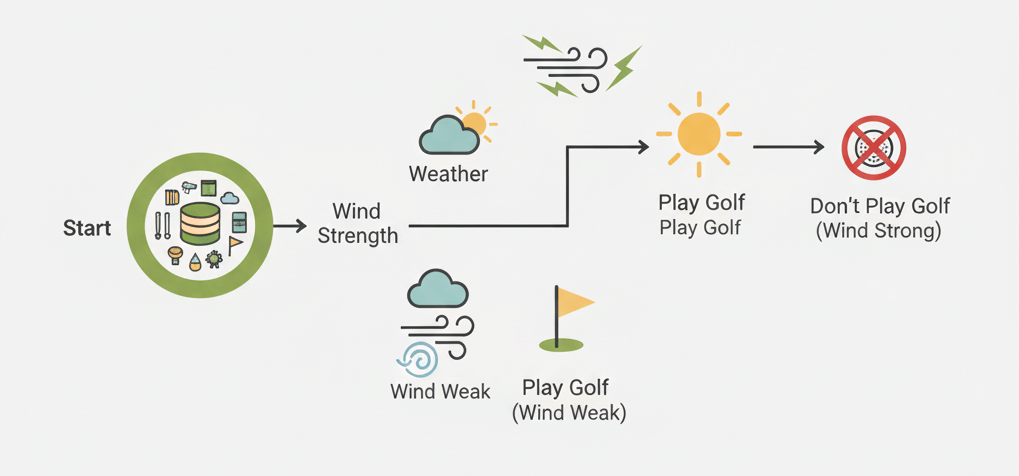
決定木分析の簡単な例として、過去のデータから「ゴルフを実施するかどうか」を予測するモデルを考えてみましょう。
1. 根(スタート地点): 過去のゴルフ実施データがすべて集まっています。
2. 最初の分岐: 「天気」で分けます。
3. 次の分岐: 「雨」のグループを「風」の強さで分けます。
4. 葉(最終結果): 条件に応じた「実施/しない」の結論が出ます。
その他の応用例
• 購入予測: 顧客の購買履歴から特定の商品を購入する可能性が高いセグメントを特定します。
• 解約予測(チャーン分析): 「サービスを解約する可能性が高い顧客」を予測し、先回りしてアプローチします。
• 金融: 融資の可否を判断する与信審査モデルに活用されます。
• 医療: 特定の疾患リスクを評価する補助診断システムに利用されます。
決定木分析と他手法の比較
決定木分析と回帰分析の違い:線形と非線形の関係性
回帰分析は、変数間の関係を線形的な数式でモデル化します。一方、決定木分析はデータを複数の領域に分割していくため、変数間の複雑な非線形関係も捉えることができます。データの関係性が複雑な場合には、決定木分析がより優れた性能を発揮することが期待されます。
決定木の進化形:ランダムフォレスト
ランダムフォレストは、複数の決定木を作成し、それらの予測結果を統合することで精度を高める手法です。個々の決定木の弱点である過学習を克服し、安定した高精度の予測が可能になります。

ディープラーニング、クラスター分析、判別分析との関係性
• ディープラーニング: 高精度ですが、プロセスが不明瞭な「ブラックボックス」です。説明責任が重要な場面では決定木が優位です。
• クラスター分析: 教師なし学習であり、未知のグループを自動的に見つけ出します。
• 判別分析: 線形的な境界線で分類するのに対し、決定木はより複雑な関係性を捉えます。
まとめ:決定木分析の価値
◎ 決定木分析は、予測や分類を行う、解釈性の高い機械学習手法です。
◎ 過学習は「剪定」や「アンサンブル学習」で克服可能です。
◎ ビジネスの様々な場面で活用されており、根拠となるルールセットを提示できることが大きな付加価値です。
\AI×商圏データの実践的な活用方法、公開中/

監修者プロフィール
市川 史祥
技研商事インターナショナル株式会社
執行役員CMO シニアコンサルタント 市川 史祥
一般社団法人LBMA Japan 理事
ロケーションプライバシーコンサルタント
流通経済大学客員講師/共栄大学客員講師
統計士/医療経営士/介護福祉経営士
Google AI Essentials/Google Prompt Essentials

1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



