
エリアマーケティングラボ
出店戦略の礎を築く、商圏分析定番の売上予測手法3選
2025年9月25日号(Vol.178)

本コラムは2025年8月27日に開催したセミナーの第1部の講演内容に加筆・修正し、開催レポートとして執筆しました。
→ 講演内容詳細と講演資料のご請求はこちら:
https://www.giken.co.jp/past_seminar_document_request/?seminar_id=66918
第1章 売上予測の真価:勘と経験から仕組み化へ
なぜ売上予測は不可欠なのか
売上予測は、単に将来の数値を算出する行為ではありません。それは、企業が持つ貴重な経営資源である「ヒト・モノ・カネ」を最も効率的かつ効果的に配分するための指針として機能します。このプロセスを通じて、企業は事業の安定性と成長を同時に追求することができます。
正確な売上予測がもたらすメリットは多岐にわたります。第一に、これは機会損失を回避するための重要な手段です。たとえば、将来的な売上ポテンシャルが高いにもかかわらず、経験則や漠然とした不安から出店をためらってしまうケースは少なくありません。精度の高い予測モデルを構築することで、このような潜在的な成功機会を客観的なデータに基づいて評価し、積極的に投資を判断することが可能になります。逆に、不適切な立地に出店し、多大な時間とコストをかけてから撤退するといった、不健全な経営判断を防ぐ効果もあります。
さらに、売上予測は「ヒト・モノ」の最適化にも直接的に貢献します。予測に基づいて、繁忙期には適切な人員配置を行い、逆に売上が低迷する時期には無駄な人件費を抑えることができます。製造業においては、需要予測に基づいて適正な在庫量を確保し、過剰在庫による保管コストを削減したり、在庫不足による販売機会の損失を防いだりすることが可能になります。また、データに基づいた現実的な売上目標を設定することは、従業員のモチベーションを維持し、組織全体の士気を高める上で極めて重要です。
属人化という壁を超える
長年にわたり店舗開発やエリアマネジメントに携わってきたベテラン担当者は、その豊富な経験と勘に基づき、優れた意思決定を下すことができます。しかし、こうした知識はしばしば言語化が難しく、特定の個人に依存してしまう「属人化」という課題を生み出します。この状態では、ベテランが異動や退職をした際、そのノウハウが組織から失われ、若手社員へのスムーズな継承が困難になります。
売上予測の仕組み化は、この属人化という壁を乗り越えるための本質的なアプローチです。これは単にITツールを導入することを超え、ベテランが持つ「暗黙知」を「形式知」に変換するプロセスに他なりません。例えば、ベテランが「この立地は道幅が広いから車での来店が多そうだ」と感じるその感覚を、GISとデータ分析によって数値化します。具体的には、「道路の幅員」、「交差点からの距離」、「駐車場台数」、「店舗の間口の広さ」といった要素を売上との相関関係に基づいて分析し、「説明変数」としてモデルに組み込むのです。
このように、経験則をデータとロジックで裏付けることで、熟練者による判断の根拠が客観的に示され、誰が見ても納得できる形になります。その結果、ベテランが不在でも、若手社員が同様のデータとモデルを活用して、同じように客観的で質の高い判断を下すことが可能になるのです。これは、組織の知識資産を共有し、持続的な成長を実現するための、技術導入の最も重要な意義だといえるでしょう。

【店舗売上予測の目的】
第2章 地図情報システム(GIS)という商圏分析ツール
GISの多角的な活用
地図情報システム(GIS)の導入目的は、新規出店における立地選定だけではありません。GISは、店舗を起点とした多角的なエリアマーケティング戦略を支えるものとして機能します。
GISの主要な活用用途としては、既存店の統廃合やリロケーション、販促活動の最適化、顧客データの可視化、小売店向けのコンサルティングなどが挙げられます。特に、顧客データを地図上にマッピングすることは、現場レベルではExcelの表形式でしか見られなかったデータに新たな視点をもたらします。顧客の居住地や購買行動を地図上にプロットすることで、どのエリアからの来店が多いか、逆にどのエリアでシェアが取れていないかを一目で把握できます。例えば、ポテンシャルが高いにもかかわらず顧客の分布が薄いエリアを発見すれば、その地域を重点的な販促対象として絞り込むといった、データに基づいた効率的なマーケティング施策を立案することが可能です。
【GIS(地図情報システム)の商圏分析における活用用途】
予測モデル構築の基礎:データの統合
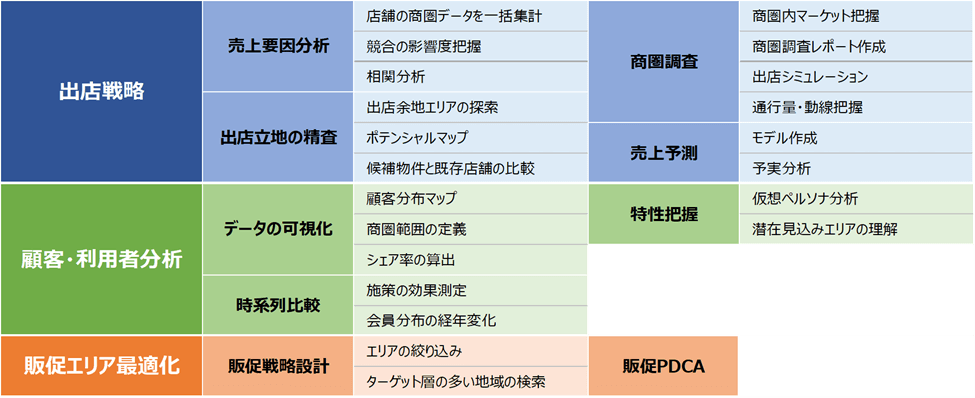
高精度な売上予測モデルの構築は、正確かつ質の高いデータセットを準備することから始まります。成功の鍵は、予測に影響を与えうる多様な要素を網羅的に収集し、一つのデータテーブルに統合することにあります。このデータテーブルは、縦軸に既存の全店舗リスト、横軸に各店舗の「売上(目的変数)」、そしてそれに影響を与える「店舗属性(自社データ)」と「商圏データ(外部データ)」を配置した形式で整理されます。
【売上予測のための店舗データセット】
データセットの構成要素
● 目的変数: 予測したい最終的な成果指標です。売上高、客数、客単価などが該当します。
● 説明変数(特徴量): 目的変数の変動を説明する要因です。
┗自社データ(内部データ): 企業が内部で保有しているデータです。例えば、売り場面積、席数、駐車場台数といった店舗の物理的なキャパシティに関する量的変数や、間口の広さ、視認性といった質的変数が含まれます。
┗外部データ: 外部の統計機関やデータプロバイダーから入手するデータです。人口、世帯構成、年収、昼夜間人口といった商圏データや、近隣の競合店舗数、駅の乗降客数、交通量などがこれに該当します。
内部データと外部データを組み合わせることは、分析の精度を向上させる上で不可欠な要素です。
企業が保有するPOSデータや顧客リストは、すでに自社の店舗を利用している人々の情報に偏りがちです。
これに対し、国勢調査データや人流データといった外部データは、市場全体というより広い視野を提供し、潜在的な顧客層や競合の動向を客観的に捉えることを可能にします。
例えば、内部データを地図にプロットした結果、自社の顧客分布が、外部データで示される「特定の年齢層が集中するエリア」と一致しない場合、そのエリアは未開拓の有望な市場であるという新たな発見につながることがあります。
このように、両者のデータを統合することで、偏りのない、より正確な市場分析と予測モデルの構築が実現します。
第3章 売上予測の3つのアプローチ:理論と実践
方法1:ハフモデル分析
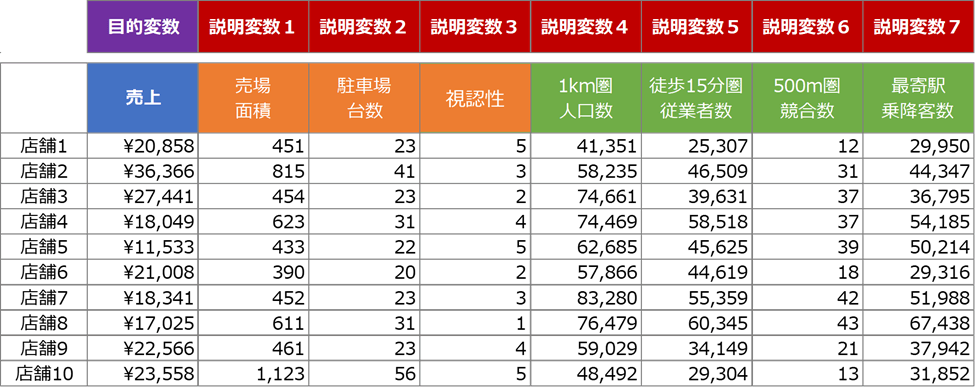
ハフモデルは、売上予測の最も代表的なアプローチの一つであり、その理論的背景は「重力モデル」に由来します。これは、ニュートンの万有引力の法則を小売業における消費者の購買行動に応用したもので、店舗の「魅力」が顧客を引き付けるという考えに基づいています。1960年代に経済学者デビッド・ハフ博士によって考案されて以来、商圏分析の重要なツールとして広く利用されています。
ハフモデルの核心は、消費者が特定の店舗を選ぶ確率を、店舗の「魅力値」と居住地からの「距離」という二つの要素で算出することにあります。一般的に、消費者は「近くて、大きい(魅力的)な店舗」に行く傾向があるという前提に基づき、以下の式で吸引率(購買確率)を計算します。
【ハフモデルの概念イメージ】
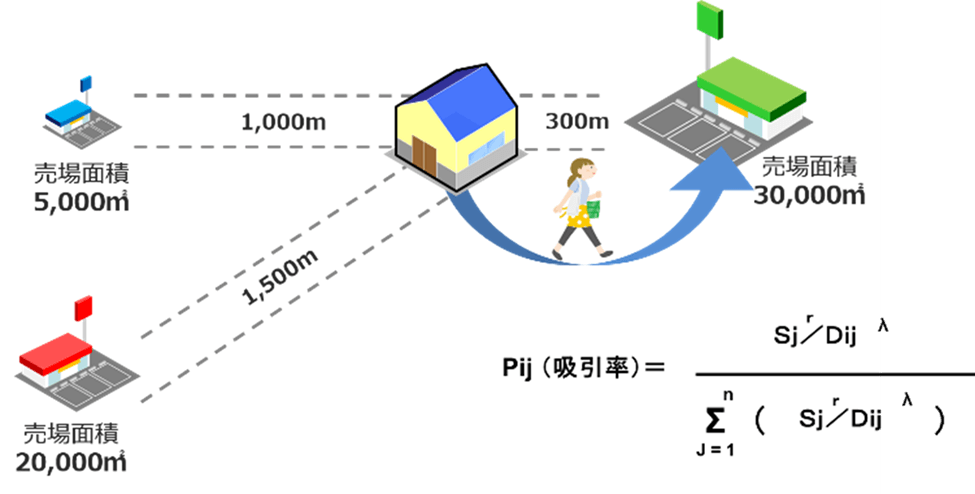
このモデルのビジネスにおける最大の利点は、競合店舗の影響を定量的に評価できる点にあります。例えば、あるエリアの単純な「商圏人口」(例:半径1km圏内に住む人口)が5万人だとしても、その商圏内に強力な競合店舗が複数存在すれば、その店舗が実際に集客できる潜在的な顧客数(「吸引人口」)は5万人よりも少なくなるはずです。
ハフモデルは、この競合の存在を計算に加味することで、より実態に即した「吸引人口」を算出します。この数値は、単なる商圏人口よりも、その店舗が実際に獲得できるポテンシャルを正確に表す指標となります。
【商圏人口と吸引人口】
さらに、ハフモデルの精度を高めるためには、魅力値と距離の定義を多角的に検討することが重要です。魅力値は、初期のモデルでは売り場面積が主流でしたが、今日ではブランド力、営業時間、商品の価格帯、駐車場面積など、多様な要素を組み合わせて総合的に算出することが推奨されています。
また、距離に対する消費者の「面倒くささ」を表す「距離抵抗係数」も、扱う商材によって柔軟に調整する必要があります。
例えば、日用品や食料品といった「最寄り品」は距離抵抗係数が高くなり、消費者は近隣の店舗を選ぶ傾向が強まります。
一方、家具や大型家電のような「買回り品」では、消費者は遠方まで足を運ぶことを厭わないため、距離抵抗係数は低く設定されます。
方法2:類似店検索・クラスター分析
売上予測のもう一つの有力なアプローチは、「類似店検索」です。これは、新規出店候補地の商圏構造が、既存のどの店舗と似ているかを特定し、その類似店の売上実績を参考に将来の売上を予測する手法です。人間が直感的に「似ている」と感じる店舗を客観的なデータに基づいて探し出すことで、予測の信頼性を高めます。
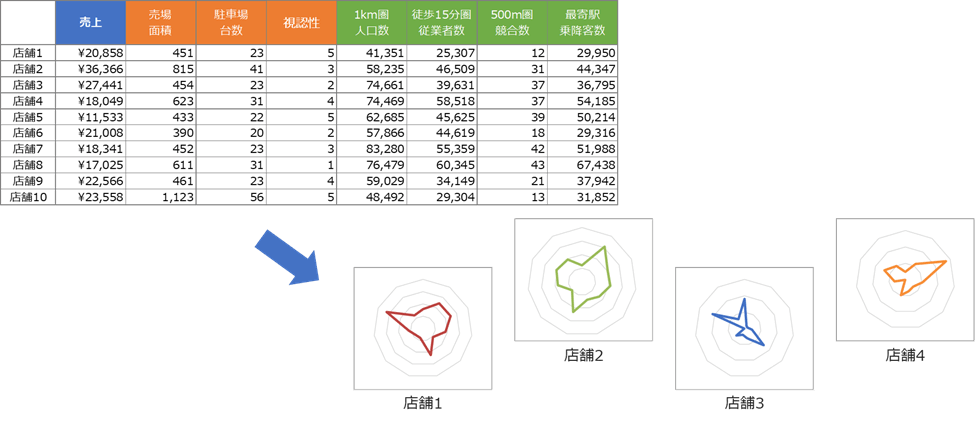
【類似店検索の概念イメージ】
この類似店検索をさらに高度化するのが「クラスター分析」です。クラスター分析は、人口構成、競合数、年収分布など、複数の商圏変数を基に、類似性の高い店舗群を統計的に自動分類する手法です。例えば、約100の既存店舗を分析した結果、それらの店舗が「オフィス街型」「ベッドタウン型」「郊外ロードサイド型」といった特定のグループに分類されることが明らかになる場合があります。この分類は、コンピューターが計算によって自動的に行いますが、その後の「なぜそのように分類されたのか」という解釈は人間が行い、ビジネス上の意味付けを与えることが重要です。
方法3:重回帰分析
重回帰分析は、複数の要因(説明変数)が、予測したい一つの結果(目的変数)にどのように影響するかを数学的な式で表現する統計手法です。この手法を用いることで、「売上は、店舗面積、商圏人口、競合店舗数といった要素の組み合わせによって、どのように決まるか」という関係性をモデル化できます。
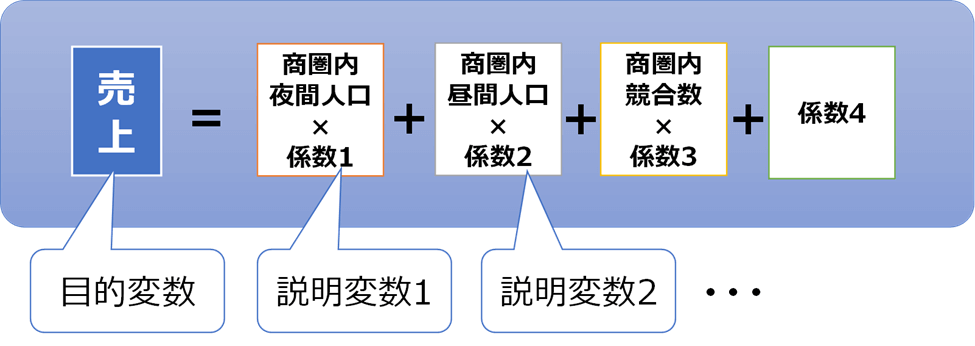
【重回帰モデルの型】
モデル構築のプロセスは、まず売上との関係性が高いと考えられる変数を仮説に基づいて選び出すことから始まります。例えば、「売上が高い店舗は、商圏の昼間人口が多いのではないか」といった仮説を立て、その変数(昼間人口)と目的変数(売上)の間の関係性を「相関係数」で確認します。相関係数は-1から+1の間の値を取り、絶対値が1に近いほど強い線形関係があることを示します 。

【相関係数】
しかし、相関係数が高いからといって、必ずしもその関係が統計的に信頼できるとは限りません。特にサンプル数(店舗数)が少ない場合、偶然その相関が見られた可能性も考慮する必要があります。このため、相関係数の「有意性」を判断することが重要です。統計的有意性を検証することで、その関係が単なる偶然ではなく、母集団全体に当てはまると考えられるかどうかの信頼性を確認できます。例えば、相関係数が0.7あれば、サンプル数が14店舗と少なくても、統計的に意味のある関係性があると判断できるという目安があります。
予測モデルの連携:ハフモデルと重回帰分析のシナジー
売上予測の精度をさらに高めるためには、単一のモデルに固執するのではなく、複数のモデルを連携させることが有効です。ハフモデルと重回帰分析を組み合わせるアプローチは、その代表的な例です。
一般的な重回帰分析では、単純な「商圏人口」を説明変数として投入することが多いですが、これでは競合の影響が考慮されません。その結果、モデルの予測精度が限定的になることがあります。そこで、まずハフモデルを活用して競合の影響を計算し、単純な「商圏人口」をより精度の高い「吸引人口」という変数に変換します。この「吸引人口」を重回帰分析の新たな説明変数として投入することで、モデルの予測精度を飛躍的に向上させることが可能です。
このシナジー効果は、実際の実証データによっても証明されています。あるアパレルチェーンの事例では、売上との相関を見る際に、単純な「世帯数」を説明変数とした場合の相関係数が0.43だったのに対し、ハフモデルで算出した「競合を考慮した吸引世帯数」を説明変数としたところ、相関係数が0.58に向上しました。これは、複数のモデルを連携させることで、単一のモデルでは得られなかったより深い洞察と、高い予測精度が実現できることを明確に示唆しています。
第4章 予測精度を飛躍的に向上させるためのポイント
データ加工と特徴量エンジニアリング
売上予測モデルの精度は、投入するデータの質に大きく左右されます。生データをそのまま利用するのではなく、目的や分析手法に合わせて適切に加工する「特徴量エンジニアリング」は、予測精度を高める上で不可欠な作業です。
例えば、東京都内の二つの地域(文京区本郷と渋谷区恵比寿)で、年収1,500万円以上の世帯数を比較した場合、実数ではそれほど大きな差がないかもしれません。しかし、両地域の総世帯数を分母として「構成比」に変換すると、その差が明確になります。このような場合、実数ではなく構成比を説明変数として用いることで、より地域の特性を捉えやすくなります。
また、人口、世帯数、競合店舗数など、単位やスケールが異なる複数のデータを一つのモデルに投入する際には、「スコア化」が有効です。各データを共通の基準(例えば偏差値)に変換することで、それらを合計した「総合スコア」として多角的な評価が可能になります。このスコアは、単純な売上予測だけでなく、有望な出店エリアや販促エリアを効率的に絞り込む際の指標としても役立ちます。
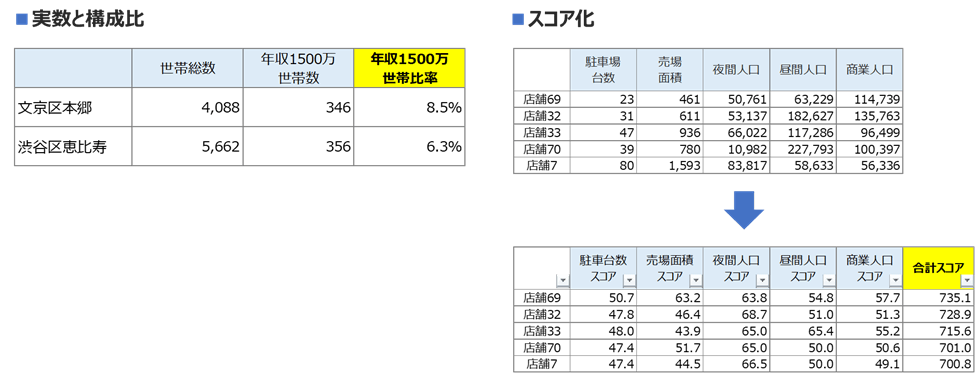
【データ加工の例】
人流データという新たな変数
従来の売上予測モデルは、国勢調査などの静的なデータ(夜間人口など)が中心でした。しかし、スマートフォンの普及により、GPS情報から得られる「人流データ」が、売上予測の精度を飛躍的に向上させる新たな有力な説明変数として台頭しています。
静的な居住人口データは、その地域に住む人々の総数を把握するには適していますが、昼間の活動人口や通行人の動向といった動的な市場ポテンシャルを捉えることは困難です。例えば、オフィス街の店舗が持つ平日昼間の購買力は、夜間人口だけでは過小評価されてしまう可能性があります。
これに対し、人流データは、特定の時間帯や曜日における人の動き、滞在時間、回遊経路といった、より詳細な顧客行動を可視化します。これにより、静的なデータでは見えなかった市場の真の姿を捉えることが可能になります。実際に、ある飲食チェーンの事例では、従来の公的統計データを用いた重回帰モデルの調整済R2乗値が0.62だったのに対し、人流データに置き換えることで0.77とさらに向上し、予測精度が大幅に改善されました。
※調整済R2乗とは、実際の売上と予測した売上との相関係数の2乗のことです。
第5章 売上予測モデルを使う(候補地理解と出店余地)
生成AIによる商圏データの説明
専門的な知識を持つ担当者であっても、膨大な商圏データ(グラフや表)を読み解き、その本質を理解するには時間と労力を要します。しかし、最近のGISツールは、生成AIを活用することでこの課題を解決し、分析結果の解釈をより多くの人が理解できる形へと変革しつつあります。
AIによる商圏レポートの自動テキスト化機能は、複雑なデータやグラフを解析し、「このエリアは30代の一人暮らしが多く、金融や不動産業界で働く人が多い」といった、人間が直感的に理解できるテキストに要約してくれます。これにより、データ分析の専門知識がない人でも、簡単に商圏の特性を把握できるようになります。この技術の最大の利点は、データ活用の「民主化」を促進し、担当者がデータ分析そのものに費やす時間を削減することにあります。その結果、担当者は得られた洞察を基にした戦略立案や、より創造的な業務に注力できるようになります。

【商圏レポートAIによる出店候補地理解】
※商圏レポートAIは当社の商圏分析GIS「MarketAnalyzer® 5」の機能です。
予測モデルを出店余地の探索に応用
一度高精度な売上予測モデルを構築すれば、その活用範囲は特定の出店候補地の分析に留まりません。構築したモデルを日本全国の地理データに適用することで、町丁目やメッシュ単位で予測売上を算出し、「出店余地」を地図上に可視化することが可能になります。
このアプローチにより、企業は物件ありきでエリアを探す従来のやり方から、「最もポテンシャルの高いエリアはどこか」という戦略的な視点に転換できます。例えば、予測売上が高いエリアを地図上でハイライト表示し、その中から未開拓の有望な地域を効率的に絞り込むことができます。前述の飲食チェーンの事例では、人流データを用いたモデルを全国に適用した結果、賃料や競合が少ない郊外エリアで、予測売上が高い地点を発見することができました。このように、予測モデルは物件探しにおける意思決定のスピードと精度を劇的に向上させるための重要なツールとなります。
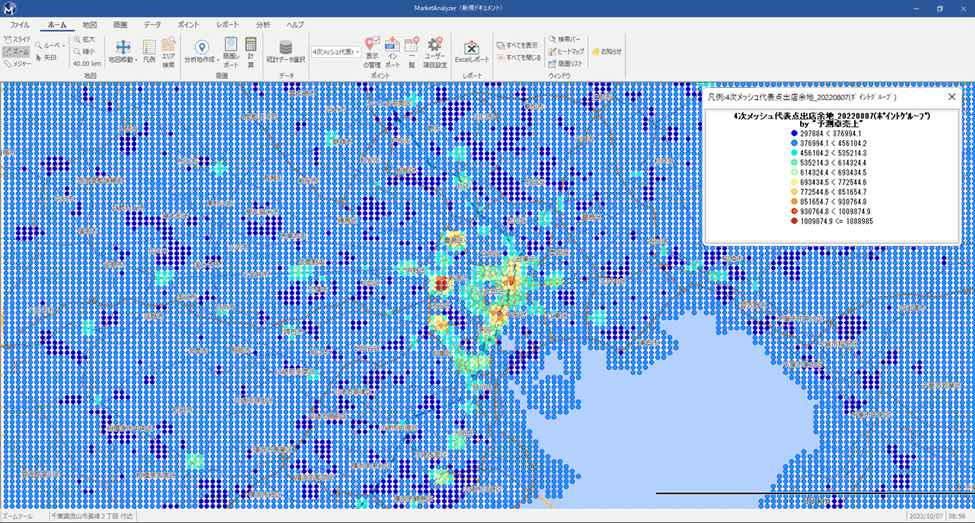
【MarketAnalyzer® 5での出店余地可視化イメージ】
最後に:データ駆動型意思決定の未来
売上予測の進化は、単に高精度なツールやモデルを導入すること以上の意味を持ちます。それは、ベテランの持つ貴重な「勘」や「経験」といった暗黙知を、データという共通言語で補強し、組織全体の知識として共有・継承していくプロセスです。これにより、組織は個人の能力に依存することなく、持続的な成長を実現するための強固な基盤を構築できます。
これからの時代、GISは単なる地図ツールではなく、膨大なデータを統合し、複数のモデルを連携させ、その結果をAIが解釈するという、複合的な戦略プラットフォームへと進化していくでしょう。データ駆動型の意思決定は、企業が市場の変化に迅速かつ柔軟に対応し、未来を切り拓くための不可欠な力となるといえるでしょう。
【AIレポートも試せる!GIS無償提供のお知らせ】
GISがどんなシステムか、どんなことができるのか、ご興味のある方は無償提供がおすすめです。
GISをいきなり導入するのはハードルが高いと感じるかもしれません。
まずは、無償で提供されているGISソフトをお試しください。
▼ MarketAnalyzer® 5


監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員 マーケティング部 部長 シニアコンサルタント |
|
| 医療経営士/介護福祉経営士 流通経済大学客員講師/共栄大学客員講師 一般社団法人LBMA Japan 理事 Google AI Essentials Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/




