
エリアマーケティングラボ
機械学習とは?仕組み・種類・エリアマーケティング分野の具体例
2025年11月14日号(Vol.191)
現代のビジネスにおいて、膨大なデータを活用した的確な意思決定が企業の競争力を左右します。従来の「経験と勘」に基づく戦略立案は、今やデータに基づいた客観的なアプローチへとシフトしています。
この変革の中心にあるのが機械学習です。ECサイトの推薦機能や音声アシスタントなど、すでに私たちの身の回りに深く浸透していますが、その仕組みや具体的なビジネス活用法はまだ曖昧な方も多いでしょう。
本コラムでは、ビジネスパーソン向けに、機械学習の基本、種類、AIとの違いをわかりやすく解説します。さらに、この技術がエリアマーケティング、特に店舗の出店戦略や販促計画といった地理的課題の解決にどのように貢献するのか、具体的な視点からご紹介します。

機械学習とは?AIとの違いから学ぶ基本的な仕組み
まず、「機械学習(Machine Learning)」とは何か、その定義とAI(人工知能)との関係性から見ていきましょう。
AIと機械学習の関係性
しばしば混同されがちな「AI」と「機械学習」ですが、両者は包含関係にあります。AIが「人間の知的振る舞いを模倣する技術や概念」という広範な枠組みであるのに対し、機械学習はそのAIを実現するための具体的な手法の一つです。
例えるなら、AIが「乗り物」という大きなカテゴリだとすれば、機械学習は「エンジン」のような中核技術にあたります。そして、機械学習の中には「ディープラーニング(深層学習)」といった、さらに特定の技術分野が存在します。このように、AI > 機械学習 > ディープラーニングという階層構造を理解することが、最初のステップとなります。
機械学習の基本的な仕組み
機械学習の最も重要な特徴は、「膨大なデータの中から、成功の法則や隠れたパターンを自律的に学習し、それに基づいて未来を予測したり、最適な判断を下したりする」点にあります。これは、人間が一つひとつ「もしAならばB」といったルールを教え込むのではなく、コンピュータ自身がデータから学び、「賢く」なるための最先端の技術です。
このプロセスは、従来の「経験と勘」に頼りがちだったエリアマーケティングや店舗開発を、データに基づいた科学的なアプローチへと進化させます。その仕組みを、具体的なステップに沿って見ていきましょう。
ステップ1:データ入力(分析の"食材"集め)
まず、コンピュータに分析の元となる多種多様なデータを「入力」します。料理の味が食材の質と量で決まるように、機械学習の精度もデータの質と量に大きく左右されます。エリアマーケティングでは、主に以下のようなデータが"食材"となります。
■データの収集と準備
【社内データ(自社の強み・実績)】・店舗の販売実績:各店舗の売上、利益、客単価、来客数、時間帯別の売上動向など。
・顧客データ:会員情報やアプリから得られる顧客の年齢、性別、居住地、購買履歴、来店頻度など。
【商圏データ(立地のポテンシャル)】
・統計データ:国勢調査などによる人口、世帯構成、年齢構成、昼間・夜間人口など。
・地図・施設データ:競合店の位置や規模、駅からの距離、周辺の学校・オフィス・商業施設の有無、交通量など。
これらのデータを組み合わせることで、初めて精度の高い分析が可能になります。
■データの前処理
集めたままの「生データ」は、ノイズ(無関係な情報)や欠損値(入力漏れ)を含んでいたり、形式がバラバラだったりすることがほとんどです。そのため、学習に適した形に整える「前処理」という作業が不可欠です。【クリーニング】 欠損値の補完や、異常な値(外れ値)の除去を行います
【整形】 テキストデータを数値に変換したり、画像のサイズを統一したりします
【分割】 用意したデータを通常、「訓練データ」「検証データ」「テストデータ」の3つに分割します
・訓練データ:モデルがパターンを学習するために使います(教科書)
・検証データ:学習中のモデルの性能を評価し、チューニングするために使います(練習問題)
・テストデータ:学習完了後のモデルの最終的な実力を測るために使います(本番の試験)
ステップ2:パターンの発見("勝ちパターン"の探求)
次に、入力された膨大なデータの中から、アルゴリズムが人間では気づけないような複雑な「勝ちパターン(成功法則)」や「負けパターン(失敗法則)」を見つけ出します。これは、何千もの店舗データを一瞬で分析できる超優秀なマーケターが、成功と失敗の要因を徹底的に探求するようなものです。
【アルゴリズムの選択】
解決したい問題の種類(予測、分類など)やデータの特性に合わせて、適切な機械学習アルゴリズム(学習手法)を選びます。アルゴリズムには、線形回帰、決定木、サポートベクターマシン、ニューラルネットワークなど、多種多様なものが存在します。
【パターンの学習】
選択したアルゴリズムが、訓練データを読み込み、その中に潜むパターンや相関関係、ルールを自動的に見つけ出します。このプロセスが「学習」や「訓練 (Training)」と呼ばれます。
【仕組み】
コンピュータは、まず仮の予測を立て、それを正解(訓練データに含まれる実際の答え)と比較します。この「予測と正解のズレ(誤差や損失と呼ばれます)」を計算し、そのズレができるだけ小さくなるように、内部の計算式(パラメータ)を何度も何度も微調整していきます。
■発見されるパターンの例
• 「高収益店舗の多くは、半径500m以内の単身世帯比率が30%以上で、かつ大手競合チェーンAから1km以上離れている」
• 「30代女性の来店率が高い店舗は、近くに保育園があり、午前中に集客のピークを迎える傾向がある」
• 「売上が伸び悩んでいる店舗は、近隣の昼間人口は多いものの、前面道路の交通量が多すぎて車でのアクセスがしにくい」
このように、複数の要因が複雑に絡み合った、ビジネスの成否を分ける本質的なルールを発見します。
ステップ3:モデルの構築("未来予測ツール"の作成)
発見した「勝ちパターン」を基に、いつでも使える予測・判定のための数理的なモデル(予測モデル)を構築します。これは、いわば「エリアマーケティング専用の未来予測ツール」や「優秀な店舗開発コンサルタントの頭脳」をコンピュータ上に再現するようなものです。
学習プロセスを経て、データから発見されたパターンやルールが凝縮されたものが「モデル」です。
• モデルとは
モデルは、特定のタスク(予測や分類)を実行するための、いわば「判断基準が詰まったプログラム」や「数式」と考えることができます。学習によって賢くなった頭脳のようなものです。
• 性能評価とチューニング
学習途中で作成されたモデルが、未知のデータに対しても正しく機能するかどうかを「検証データ」を使って確認します。この評価結果を基に、モデルの性能がさらに向上するように設定(ハイパーパラメータ)を調整する作業を「チューニング」と呼びます。
• 注意点
過学習 (Overfitting): モデルが訓練データに過剰に適合しすぎて、未知のデータにはまったく対応できなくなる状態です。これを避けるために、検証データでの評価が重要になります。
■構築されるモデルの例
【売上予測モデル】
新しい出店候補地の「人口」「競合店の数」「駅からの距離」といった情報を入力するだけで、その場所に出店した場合の将来の売上を高精度で予測してくれるモデル。
【顧客分類モデル】
顧客データから、自動的に「ロイヤルカスタマー」「離反しそうな顧客」「特売品にしか興味がない顧客」などに分類し、それぞれの顧客層に最適なアプローチを導き出すモデル。
ステップ4:予測・分類(データに基づく意思決定)
最後に、構築したモデルを実際のビジネスシーンで活用します。これにより、客観的なデータに基づいた、より確かな意思決定が可能になります。
• 最終評価
最後に「テストデータ」をモデルに入力し、その正解率や精度を客観的に評価します。この評価によって、モデルが実社会の問題に対してどれだけ有効であるかを最終的に判断します。
最終的に完成したモデルを使って、新しい未知のデータに対する判断を行います。これが機械学習の最終的な目的です。
• 活用例①:新規出店戦略
複数の出店候補地(A, B, C)の商圏データを売上予測モデルに入力します。すると、「候補地Aの予測年商は1.2億円、Bは9,000万円、Cは6,000万円」といった具体的な数値が出力されます。これにより、最も成功確率の高い場所を選び、出店の失敗リスクを大幅に減らすことができます。
• 活用例②:既存店の販売促進
顧客分類モデルを使い、「離反しそうな顧客」グループを特定。その顧客層にだけ特別なクーポンを送付して再来店を促したり、「特定の高級品を購入する優良顧客」が多い店舗では、関連商品の品揃えを強化したりするなど、店舗ごとの特性に合わせたきめ細やかなマーケティング施策を実行できます。
この「データからパターンを見つけ出し、意思決定に活かす」という根本的な思想は、実はエリアマーケティングの目的と深く共通しています。例えば、成功している店舗の立地条件や商圏特性から「勝ちパターン」を見つけ出し、新たな出店戦略に活かすアプローチは、まさに機械学習的な思考の応用と言えるでしょう。当社、技研商事インターナショナルが提供するGIS(地図情報システム)は、この地理的なパターン発見を支援し、データに基づいた意思決定を可能にするための専門的なツールです。
機械学習の「学習」とは?代表的な3つの種類を解説
一口に「学習」と言っても、そのアプローチは一つではありません。機械学習は、与えられるデータの性質と解決したい課題に応じて、主に3つの種類に大別されます。
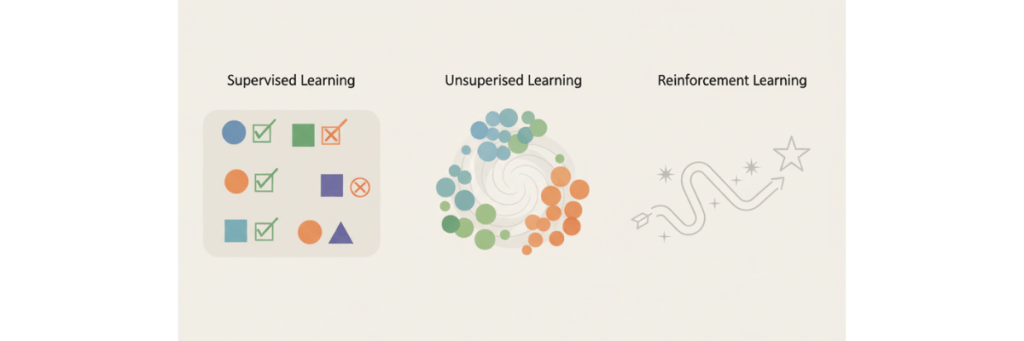
教師あり学習
「教師あり学習」は、正解ラベルが付与されたデータ(教師データ)を用いて学習する手法です。入力データとそれに対応する正解をセットで学習させることで、未知のデータに対して正しい出力を予測するモデルを構築します。例えるなら、問題と解答がセットになった問題集で勉強するようなものです。
【ビジネスでの活用例】
• 売上予測: 過去の店舗売上(正解)と、その時の立地条件、天候、販促活動などのデータ(入力)を学習させ、新規出店候補地の売上を予測する。
• 顧客の離反予測: 過去にサービスを解約した顧客(正解)の行動パターン(入力)を学習し、同様の傾向を示す既存顧客を特定して対策を講じる。
• 迷惑メールフィルタ:受信したメールが迷惑メールか否か(正解)を、その内容や送信元(入力)から判断する。
教師なし学習
「教師なし学習」は、正解ラベルのないデータから、その背後にある構造やパターン、グループ分けなどを見つけ出す手法です。解答のない資料の中から、類似するものを自分で整理・分類していくイメージです。
【ビジネスでの活用例】
• 顧客セグメンテーション(クラスタリング):購買履歴やウェブサイトの閲覧履歴といったデータから、顧客を類似した特徴を持つ複数のグループ(クラスター)に自動で分類する。これにより、各グループの特性に合わせたマーケティング施策を展開できます。
• 店舗のグルーピング:各店舗の売上構成や商圏の人口統計データなどを用いて、似た性質を持つ店舗をグループ化する。これにより、店舗ごとの特性に応じた品揃えや運営方針を検討できます。
• 異常検知:通常のデータパターンから大きく外れたものを検出し、システムの不正アクセスや製造ラインの異常などを発見する。
強化学習
「強化学習」は、明確な正解データがない状況で、システム(エージェント)が試行錯誤を繰り返しながら、特定の目標に対する報酬を最大化するように行動を学習する手法です。ペットに「おすわり」を教える際、うまくできたらおやつ(報酬)を与えるのに似ています。
【ビジネスでの活用例】
• 動的価格設定(ダイナミックプライシング): 航空券やホテルの宿泊料金、配車サービスの料金などを、需要と供給のバランスに応じてリアルタイムに最適化し、収益を最大化する。
• 広告配信の最適化:ユーザーの反応(クリックやコンバージョンなど)を報酬と捉え、どの広告クリエイティブをどのタイミングで表示すれば効果が最大化されるかを学習する。
• ロボット制御: お掃除ロボットが部屋の形状や障害物を認識しながら、最も効率的な清掃ルートを自律的に見つけ出す。
この中でも特に、ビジネスの現場、とりわけエリアマーケティングで重要となるのが「教師あり学習」による予測と、「教師なし学習」による分類(グルーピング)です。そしてこれらの考え方は、当社のエリアマーケティング用GIS「MarketAnalyzer® 5」に搭載されている統計解析機能と深く関連しています。例えば、売上予測は「重回帰分析」で、顧客や店舗のセグメンテーションは「クラスター分析」で実現可能であり、機械学習のコンセプトを具体的なビジネス課題の解決に結びつけることができます。
機械学習のモデルの2大系統(回帰系と決定木系)
数ある「機械学習モデル」ですが、特に重要なのが「回帰系」と「決定木系」という2つの系統です。
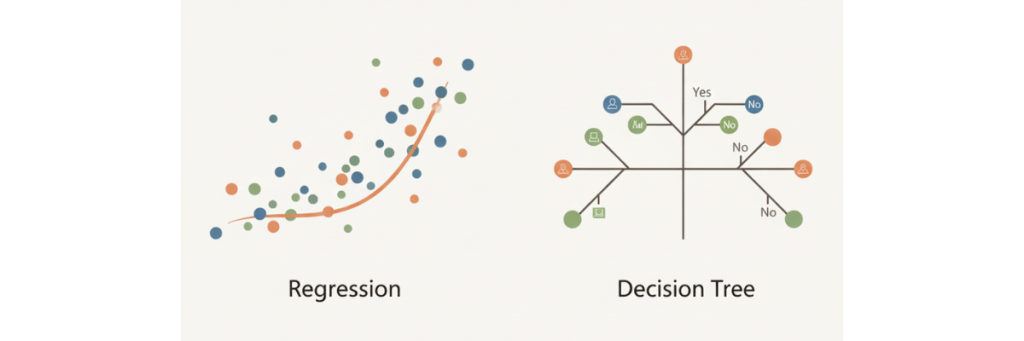
回帰系モデル:データから「関係性の方程式」を見つけ出す
回帰系モデルとは、ある結果(例:売上)が、どのような要因(例:広告費、販売エリア)によってどの程度影響を受けるのかを、一つの数式でシンプルに表現する手法です。グラフ上のデータに最もフィットする一本の線を引く、とイメージすると分かりやすいでしょう。主に、売上や株価、需要といった連続する数値を予測する際に力を発揮します。
【線形回帰】
まず、最もシンプルで直感的なアプローチが線形回帰です。これは、単一の要因と結果の間に「直線的」な関係を仮定し、その関係性を数式で表そうと試みるものです。例えば、「広告費を増やせば、売上も一定の割合で増加する」といった状況を分析する際に用いられます。その構造の単純さから、特定の施策が結果にどの程度影響を与えるかを端的に把握したい場合に非常に有効な手法です。
【重回帰分析】
しかし、実際のビジネスにおいて、一つの要因だけで結果が決まることは稀です。そこで登場するのが重回帰分析です。これは線形回帰を拡張したもので、複数の要因を同時に考慮できる点が最大の特徴です。住宅価格を予測する際に、「部屋の広さ」だけでなく「駅からの距離」や「築年数」といった多様な情報を組み合わせることで、より現実に即した精度の高い予測が可能になります。このように、複雑に絡み合う要因の中から、どの要素が結果に強く影響しているのかを総合的に評価できるのが重回帰分析の強みです。
【非線形回帰】
一方で、世の中には要因と結果の関係が直線で表せない事象も数多く存在します。例えば、広告費を増やし続けてもある時点から売上の伸びが鈍化する「収穫逓減」のような現象です。このような、直線では捉えきれない複雑な関係性をモデル化するのが非線形回帰の役割です。この手法を用いることで、成長の鈍化や限界効果といった、よりリアルなビジネスの動態をデータから読み解き、分析に深みを持たせることができます。
【ロジスティック回帰】
これまで紹介した3つのモデルが売上や価格といった「数値」を予測することを目指していたのに対し、ロジスティック回帰は全く異なる目的で利用されます。その目的とは、「はい/いいえ」や「成功/失敗」といった二者択一の結果を予測することです。このモデルは、ある事象が発生する「確率」を0から1の間で算出し、その確率が一定の基準を超えるかどうかで結果を分類します。例えば、顧客の年齢や購買データから「キャンペーンに反応する確率」を計算し、見込みの高い顧客をリストアップする、といった活用が可能です。顧客の離反予測や融資審査など、結果を分類したい場面で幅広く応用されています。
決定木系モデル:専門家の「思考プロセス」を再現する
決定木系モデルは、「もし〜なら、こうする」という条件分岐(ルール)を繰り返すことで、データをグループ分けしていく手法です。フローチャートのように、「はい/いいえ」で答えながら結論に至るプロセスをイメージすると良いでしょう。数値の予測はもちろん、顧客が「購入するか/しないか」といったカテゴリ分類にも使える汎用性の高さが魅力です。
代表的なアルゴリズムとビジネス活用
・決定木 (Decision Tree)
単体の基本的なモデルです。「年齢は40歳以上か?」「年間購入額は10万円以上か?」といったルールが可視化されるため、なぜその予測に至ったのかという背景が非常に分かりやすいのが最大のメリットです。顧客セグメンテーションのルール作りや、与信審査の判断ロジックを分析する際などに役立ちます。ただし、単体ではルールを細かく作りすぎてしまい、過学習に陥りやすいという側面もあります。
・ランダムフォレスト (Random Forest)
決定木の弱点である過学習を克服した、極めて強力な手法です。「三人寄れば文殊の知恵」の考え方に基づき、少しずつ特徴の異なる多数の決定木を構築し、それらの予測結果の多数決や平均値で最終判断を下します。単体のモデルよりも遥かに精度が高く、安定した結果が得られるため、多くの実務シーンで採用されています。
・勾配ブースティング (Gradient Boosting)
現在、最高峰の精度を誇るアルゴリズム群(XGBoost, LightGBMなど)です。一つ目のモデルの予測間違いを、二つ目のモデルが重点的に学習して修正し、三つ目は一つ目と二つ目の間違いを修正する…というように、モデル同士が間違いから学び、段階的に賢くなっていくのが特徴です。精度が最優先されるコンペティションや、金融商品の価格予測、不正検知といったシビアな場面で絶大な効果を発揮します。
機械学習と統計解析の違いとは?ビジネスにおける使い分けを理解する
機械学習の話題において、しばしば比較対象となるのが「統計解析」です。両者はデータから知見を得るという点で共通していますが、その主たる目的とアプローチには明確な違いがあります。この違いを理解することは、ビジネス課題に対して適切なツールを選択する上で非常に重要です。
目的の違い:「予測」か「解釈」か
両者の最も本質的な違いは、その目的にあります。
• 統計解析の目的は「解釈・説明」
データに潜む変数間の因果関係や構造を理解し、「なぜそうなったのか」を説明することに主眼を置きます。モデルの解釈可能性が重視され、どの要因が結果にどれだけ影響を与えたのかを明らかにしようとします。
• 機械学習の目的は「予測」
未知のデータに対して、いかに高い精度で結果を予測できるかを追求します。「次に何が起こるか」を当てることを最優先とし、そのための予測精度が高ければ、モデルの内部構造が複雑で解釈困難(ブラックボックス)であっても許容される傾向があります。
とはいえ、両者の境界は近年曖昧になりつつあります。統計学の分野でも予測精度の高いモデルが研究されていますし、機械学習の分野でもモデルの判断根拠を説明しようとする「XAI(Explainable AI)」という領域が注目を集めています。
ビジネスにおける使い分け
この目的の違いから、ビジネスにおける適切な使い分けが見えてきます。
複雑な機械学習モデル、特にディープラーニングなどは、その予測精度の高さから需要予測や画像認識といったタスクで絶大な効果を発揮します。しかし、その判断根拠がブラックボックス化しやすいため、「なぜこの予測結果になったのか」を説明することが難しい場合があります。
一方で、企業の重要な経営判断、例えば「多額の投資を伴う新規店舗の出店」や「全社的なマーケティング戦略の策定」といった場面では、単に「予測結果が良いから」という理由だけでは意思決定はできません。そこには、「どの地域の、どのような特性が、売上にプラスの影響を与えるのか」といった、論理的で解釈可能な根拠が不可欠です。
このような戦略的意思決定の場面で力を発揮するのが、統計解析です。重回帰分析のような手法を用いれば、「駅からの距離」や「商圏内の世帯年収」といった各要因が売上に与える影響度を数値で明確に把握できるため、説得力のある戦略立案が可能になります。
つまり、自動化や高精度な予測が求められるタスクには機械学習を、戦略的な意思決定のための要因理解や解釈が求められる場面では統計解析を、というように、目的応じて最適な手法を選択することが賢明です。
ビジネスを加速させる機械学習の身近な活用例
機械学習は、すでに私たちの生活やビジネスの様々な場面で活用され、その利便性や効率性を高めています。具体的な例を知ることで、その可能性をより身近に感じることができるでしょう。

消費者としての活用例
• レコメンデーションエンジン
AmazonやNetflix、YouTubeなどで、過去の閲覧・購買履歴に基づき「あなたへのおすすめ」として商品やコンテンツが表示されるのは、機械学習がユーザーの好みを分析・予測しているためです。
• 地図・ナビゲーションアプリ
Googleマップなどが交通状況や過去のデータをリアルタイムで分析し、最適なルートや正確な到着予測時刻を提示するのも、機械学習の応用例です。
• 画像認識
スマートフォンのカメラが人物の顔を認識してピントを合わせたり、風景や夜景といったシーンを自動で判別して最適な画質に調整したりする機能にも、画像認識技術が活用されています。
ビジネスにおける活用例
これらの技術は、ビジネスの現場でも大きな力を発揮します。
• 需要予測
小売業者が天候データや過去の販売実績、地域のイベント情報などを分析し、特定商品の需要を予測します。これにより、在庫の最適化を図り、品切れによる機会損失や過剰在庫のリスクを低減できます。
• 広告配信の最適化
デジタル広告において、ユーザーの年齢や、興味関心、行動履歴などから、広告効果が最も高くなるターゲット層を自動で特定し、広告クリエイティブを出し分けることで、ROI(投資対効果)を最大化します。
• 顧客分析
膨大な顧客データから優良顧客層や離反予備軍を特定し、それぞれに合わせたアプローチを行うことで、顧客エンゲージメントを高めます。
これらの活用例に共通するのは、「データに基づいて人間の行動を理解し、予測する」という点です。そして、この予測に「場所・地理」というコンテキストを加えることで、戦略はさらに強力になります。例えば、優良顧客層を特定するだけでなく、「その優良顧客層がどのエリアに集中して居住しているか」を可視化できれば、より効果的な販促エリアの選定や新規出店計画が可能になります。機械学習が予測する「誰が」「何を」という情報に、GISが提供する「どこで」という情報を掛け合わせることが、次世代のエリアマーケティングの鍵となるのです。
▶ あわせて読みたい「AIの具体的な活用事例」: 身近な例やビジネス現場の例を解説したコラムはこちら
エリアマーケティングにおける機械学習とデータ分析の可能性
これまで見てきた機械学習やデータ分析の概念は、エリアマーケティングという領域において、企業の成長を加速させる大きな可能性を秘めています。顧客や市場を地理的な視点で捉えることで、ビジネス課題はより具体的に、そして解決策はより的確になります
出店戦略:高精度な売上予測によるリスクの最小化
新規出店の成否は、企業の収益に直結する重要な意思決定です。ここで求められるのは、「候補地の売上をいかに正確に予測するか」という課題です。これは、まさに「教師あり学習」的なアプローチが活きる領域です。
既存店舗の売上実績を目的変数とし、店舗の面積や駐車台数といった店舗属性データ、さらには商圏内の人口、世帯構成、年収、競合店の位置といった多様なデータを説明変数として分析モデルを構築します。このモデルを用いることで、新たな出店候補地に対して客観的なデータに基づいた売上予測が可能となり、出店判断の精度を飛躍的に高め、投資リスクを最小限に抑えることができます。
顧客セグメンテーション:エリア特性から顧客像をあぶり出す
「自社の優良顧客はどのような人々で、どのエリアに住んでいるのか」を把握することは、効果的なマーケティングの第一歩です。これは「教師なし学習」のクラスタリング(分類)の考え方を応用できます。
顧客データと、国勢調査などの公的統計データやライフスタイルデータなどを組み合わせ、地図上で分析します。すると、特定のエリアに特定の特性を持つ顧客層が集中していることが可視化されます。例えば、「都心部に住む単身の若年層」や「郊外に住むファミリー層」といった具体的な顧客セグメントと、その居住エリアを特定できます。これにより、エリアの特性に合わせた商品展開やプロモーション施策を立案することが可能になります。
販促エリア最適化:ROIを最大化するターゲティング
限られた予算の中で広告や販促の効果を最大化するためには、ターゲット層に効率的にアプローチすることが不可欠です。自社の顧客データやGPS位置情報データなどを活用し、店舗に来訪している顧客がどのエリアから来ているのかを分析します。
これにより、自社の集客力が強い「ホットスポット」となるエリアを地図上で特定できます。チラシのポスティングやWeb広告のジオターゲティングをこれらのエリアに集中させることで、無駄なコストを削減し、販促活動のROIを大幅に向上させることが可能です。
このように、エリアマーケティングにおける重要な意思決定は、予測と分類、そしてその根拠の解釈というデータ分析のプロセスそのものです。単に「この場所が良い」という予測結果だけでなく、「なぜなら、このエリアには我々のターゲット顧客層が集中しており、競合も少ないからだ」という解釈可能なインサイト(洞察)を得ることが、ビジネスの成功を確かなものにするのです。
▶ あわせて読みたい「業界別・位置情報データ活用術」: 位置情報の基本とビジネス活用事例の紹介コラムはこちら
MarketAnalyzer® 5で始める、データドリブンなエリア戦略
ここまで解説してきた機械学習や統計解析の考え方を、専門的な知識がない方でも直感的かつ効果的にビジネスへ活用できるように設計されたツールが、当社のエリアマーケティング用GIS「MarketAnalyzer® 5」です。
MarketAnalyzer® 5は、データサイエンティストのような専門家でなくとも、データに基づいた高度なエリア戦略を立案・実行できるよう支援するプラットフォームです。特に、本コラムで解説した機械学習の主要なコンセプトと直結する、強力な統計解析機能を搭載しています。

重回帰分析機能:教師あり学習による高精度な「売上予測」
この機能は、まさに「教師あり学習」のコンセプトを店舗開発に応用するものです。既存店の売上データと、商圏内の様々な統計データ(人口、世帯、年収、競合状況など)の関係性を分析し、売上を予測するための独自の「予測モデル」を構築します。
このモデルを使えば、任意の出店候補地点の予測売上高を瞬時に算出できます。さらに、単に予測値を出すだけでなく、どの要素が売上にプラス(またはマイナス)に影響しているのかを可視化できるため、自社にとっての「成功立地の条件」を深く理解し、戦略的な出店計画を立てることが可能になります。
クラスター分析機能:教師なし学習による「市場・顧客のセグメンテーション」
この機能は、「教師なし学習」の考え方を用いて、店舗やエリアを自動でグループ分けします。例えば、全国の店舗を売上規模や商圏特性が似たもの同士で分類することで、「都心型」「郊外ファミリー型」「地方ロードサイド型」といった店舗タイプを客観的に定義できます。
これにより、各店舗タイプに共通する売れ筋商品や効果的な販促手法を見つけ出し、施策の横展開を図ることができます。また、未出店のエリアを分析し、自社の得意とするタイプの市場がどこに存在するかを発見するなど、新たなビジネスチャンスの探索にも繋がります。
主成分分析機能:複雑なデータを要約し、本質を捉える
エリアマーケティングでは、年齢構成、家族構成、所得水準、住宅種別など、非常に多くの変数を扱います。主成分分析は、これらの多数の変数の中から本質的な情報(主成分)を抽出し、データをよりシンプルで扱いやすい形に要約する手法です。
例えば、様々な人口統計データを統合して「ファミリー層の豊かさ指標」や「単身者の都市型ライフスタイル度」といった新しい総合指標を作成できます。これにより、データのノイズを減らし、重回帰分析やクラスター分析の精度と解釈性をさらに高めることができます。
MarketAnalyzer® 5は、これらの高度な分析機能に加え、豊富な搭載データ、直感的な地図インターフェース、そして2,000社以上の導入実績に裏打ちされた伴走型のサポート体制を強みとしています。さらに、最新の生成AI技術を活用し、複雑な商圏データを文章で分かりやすく要約する「商圏レポートAI」機能も搭載。分析の専門家でなくとも、誰もがデータから深い洞察を得られる環境を提供します。
まとめ
本コラムでは、機械学習の基本的な仕組みから種類、そして統計解析との違いについて解説し、エリアマーケティングという具体的なビジネス領域での活用可能性を探りました。
機械学習は、データからパターンを学び、高精度な「予測」を行うための強力な技術です。一方で、企業の重要な戦略的意思決定においては、予測結果だけでなく、その背景にある「なぜ」を理解し、説明できることが不可欠です。
特に、店舗開発や販促戦略といったエリアマーケティングの分野では、この予測と解釈のバランスが成功の鍵を握ります。
技研商事インターナショナルが提供する「MarketAnalyzer® 5」は、まさにこの思想を具現化したツールです。重回帰分析やクラスター分析といった解釈性の高い統計解析機能を通じて、機械学習的なアプローチをビジネスの現場で実践し、データに基づいた再現性の高いエリア戦略の実現を支援します。ご興味をお持ちいただけましたら、ぜひお気軽に資料請求や無料デモをお申し込みください。
監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員 マーケティング部 部長 シニアコンサルタント |
|
| 医療経営士/介護福祉経営士 流通経済大学客員講師/共栄大学客員講師 一般社団法人LBMA Japan 理事 Google AI Essentials Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/




