
エリアマーケティングラボ
特徴量エンジニアリングとは?AI売上予測の精度を劇的に高めるデータ加工の極意
2026年1月7日号(Vol.207)
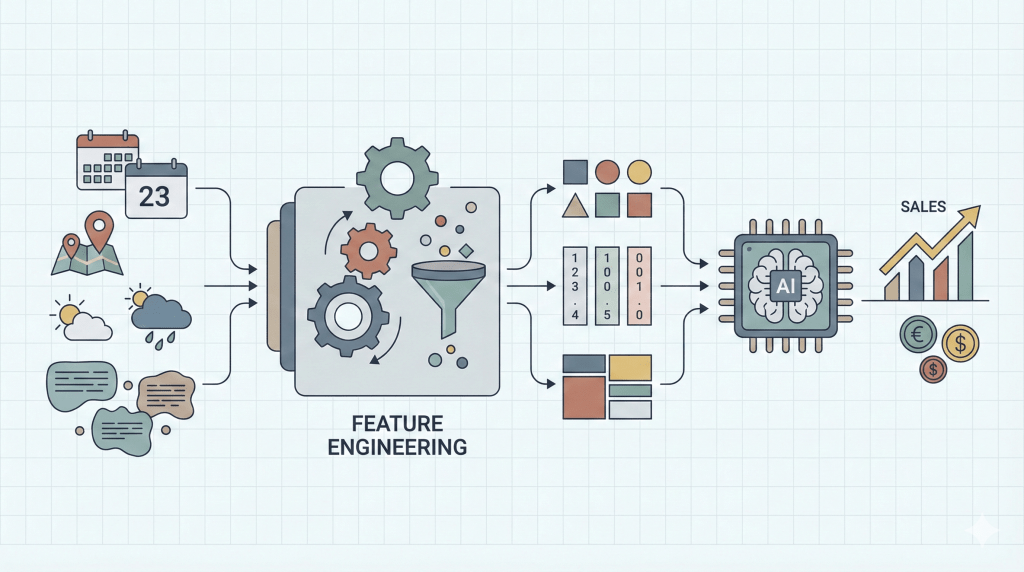
現在、多くの企業がAI(人工知能)や機械学習を導入していますが、「高価なツールを導入したのに精度が出ない」という壁に直面しています。実は、その原因の多くはAIのアルゴリズムではなく、AIに学習させるデータの加工プロセス、すなわち「特徴量エンジニアリング」にあります。
本記事では、データサイエンスの世界で「モデル精度の8割を決める」と言われる特徴量エンジニアリングの本質と、ビジネス現場での実践的な活用法について解説します。
特徴量エンジニアリングの本質
~ 生データを「インサイト」に変える ~
特徴量エンジニアリングを一言で表すと、「現場の暗黙知を形式知化し、AIが理解できる言葉(数式)に翻訳するプロセス」です。
特徴量エンジニアリングの定義とビジネス的意義
機械学習モデルは、入力されたデータ(数値)に基づいてパターンを学習します。しかし、現場にある「生データ」をそのまま入力しても、AIは意味を理解できません。
● 生データの例:「2026年12月28日」「東京都江東区豊洲4丁目」「ビルインタイプ」
● AIが理解できる形式:数値ベクトル、行列
このギャップを埋めるのが特徴量エンジニアリングです。例えば、「2025年12月28日」という日付データそのものには、売上を左右する直接的な意味はありません。しかし、これを「日曜日(週末フラグ)」「年末(繁忙期フラグ)」「給料日後(消費活性化フラグ)」といった、人間の解釈を加えた変数(特徴量)に変換することで初めて、AIは「なぜその日に売上が伸びるのか」という因果構造を学習できるようになります。
ビジネス的な観点から言えば、特徴量エンジニアリングとは「現場の暗黙知を形式知化し、AIに継承させるプロセス」と定義できます。ベテランの店舗開発担当者が物件を見た瞬間に「ここは駅からの動線が良いが、競合店との並びが悪い」と感じる直感。これを「駅徒歩分数」や「競合店までの距離」といった単純な数値だけでなく、「駅改札からの視認性スコア」や「競合店との相乗効果指数」といった高度な変数に落とし込む作業こそが、予測精度を飛躍させる鍵となります。
「Garbage In, Garbage Out」の鉄則とデータ品質
データ分析の世界には、「Garbage In, Garbage Out(ゴミを入れれば、ゴミしか出てこない)」という絶対的な原則があります。どれほど高性能なAIモデルを使っても、入力データの質が低ければ正しい予測はできません。
特に店舗売上予測においては、以下の3つの観点でデータの質と特徴量設計が問われます。
・網羅性:商圏人口、競合状況、天候、経済指標など、売上を左右するあらゆる要因をカバーできているか。
・正確性:欠損値や異常値(ノイズ)が適切に処理されているか。
・表現力:単なる物理的「距離」ではなく、「心理的距離」や「移動コスト」のように実態に即した意味を持たせられているか。
多くの企業がAI導入に失敗する原因は、アルゴリズムの選定ミスではなく、この前処理段階でのつまづきにあります。データサイエンティストは業務時間の約80%をデータのクリーニングと特徴量エンジニアリングに費やすと言われていますが、裏を返せば、ここさえクリアできれば、AIプロジェクトの成功確率は劇的に向上するのです。
「特徴量」をどう設定するか?
売上予測モデルを構築する際、データは「目的変数」と「説明変数」の2つに大別されます。このパートでは、店舗ビジネス特有の変数の構造と、それらを扱う際の技術的・実務的なポイントについて説明します。
目的変数の設計:何をゴールに設定するか
目的変数は、予測モデルが目指すべきゴールです。新規出店時の売上予測の場合、一般的には「店舗売上高」が設定されますが、戦略によってはより細分化された指標を用いるべき場合があります。
|
目的変数の種類 |
特徴と活用シーン |
注意点 |
|
月商・年商 |
最も一般的で経営判断に |
季節変動や営業日数の違いを |
|
客数 |
売上よりも環境要因(通行量、天候)の |
客単価の変動が含まれないため、最終的な |
|
坪効率(坪単価) |
店舗面積が異なる物件同士を |
小型店ほど高くなりやすく、大型店の |
|
店舗ランク |
売上絶対額ではなく、S/A/B/Cのような |
撤退基準の判定等、意思決定の自動化に適するが、 |
ここで重要なのは、目的変数の「分布」を確認することです。異常値(外れ値)が含まれていると、モデルがそれに引きずられて歪んでしまいます。
例えば、リニューアルオープン直後の「オープン特需」による異常な売上や、台風による臨時休業日の売上ゼロといったデータは、学習データから除外するか、平滑化処理を行う必要があります。これも広義の特徴量エンジニアリングの一部です。
説明変数の設計:静的データと動的データの融合
説明変数は、売上の変動要因を説明するためのデータ群です。当社、技研商事インターナショナルの「MarketAnalyzer®」シリーズで扱われる豊富なデータ群を例に、どのような変数が売上予測に寄与するのかを分類・解説します。
マクロ環境データ(商圏ポテンシャル)
店舗周辺にどれだけの顧客が存在し、どの程度の購買力を持っているかを示す基礎データです。
・人口・世帯: 夜間人口や世帯数に加え、「単身世帯率」や「高齢化率」など、業態に合わせた構成比を特徴量とます。
・昼間人口:オフィス街や学生街のポテンシャルを測るために不可欠な、勤務・通学時間帯の人口です。
・富裕度・消費支出:高級店等では、単なる人口数より「年収1000万円以上の世帯数」等の商圏の「質」が決定打となります。
ミクロ環境データ(競合・商業集積)
自店舗を取り巻く競争環境や、相乗効果を生む商業施設の状況です。
・競合店データ:競合店の数や距離。高度な特徴量エンジニアリングでは、単なる数ではなく「距離による減衰(重み付け)」を考慮した「競合圧力指数」を算出します。
・商業集積度:周辺の小売業年間販売額や売り場面積の総和。これが多いほど、地域全体としての集客力が高い(=広域から客を呼べる)ことを示唆します。
物件スペック・内部要因(オペレーション)
店舗そのものの魅力や制約条件です。
・物理的制約:売場面積、駐車場台数、席数。これらは売上の上限(キャパシティ)を決定する重要な変数です。
・視認性とアクセス:角地か否か、看板の視認性、前面道路の交通量、中央分離帯の有無。これらは定性データであることが多く、ダミー変数化(後述)が必要です。
動的データ(人流・時系列)
近年、重要性が増しているのが、リアルタイムに近い動的なデータです。
・GPS人流データ: スマートフォンの位置情報から得られる、時間帯別・曜日別の滞在人口や通行量。国勢調査のような静的な統計では捉えきれない、実際の人の動き(実勢商圏)を可視化します。
・カレンダー要因: 曜日、祝日、連休、イベント開催日。これらは売上の日次変動を説明する上で必須です。
これらの多種多様なデータを、一つの分析テーブル(データマート)に統合する作業こそが、特徴量エンジニアリングの第一歩であり、最大の難関でもあります。
アルゴリズムの選定と特徴量変換の技術論
多くの分析ツールには、以前から「変数重要度」という機能が備わっていました。では、なぜ計算コストのかかるSHAPをわざわざ導入する必要があるのでしょうか。ここでは、従来手法との決定的な違いを明確にします。
カテゴリ変数の数値化:One-Hot EncodingとLabel Encoding
多くのデータは数値ではなく「文字(カテゴリ)」で表現されています。「月曜日」「雨」「ロードサイド」といった情報をモデルに理解させるには、数値化が必須です。
● One-Hot Encoding(ダミー変数化)
カテゴリの数だけ列(カラム)を増やし、該当する箇所に「1」、それ以外に「0」を入れる手法です。
例:曜日(月、火、水...)
→ 月曜日カラム:[1, 0, 0...]
→ 火曜日カラム:[0, 1, 0...]
これにより、各カテゴリが独立した影響力を持つものとして扱われます。重回帰分析など線形モデルではこの手法が一般的ですが、カテゴリ数が多すぎる(例:市区町村名で1700以上)場合、計算コストが増大し、モデルの性能が低下するリスクがあります。
● Label Encoding(ラベルエンコーディング)
カテゴリを整数に置き換える手法です(例:Sランク=3, Aランク=2, Bランク=1)。順序に意味がある場合(店舗規模の大・中・小など)に有効ですが、順序に意味がない場合(都道府県コードなど)に適用すると、モデルが誤って「北海道(1)より沖縄(47)の方が数値的に大きい」という誤った大小関係を学習してしまう危険があります。
数値データのスケーリング:標準化と正規化
「売場面積(100㎡)」と「商圏人口(10,000人)」のように、桁が異なるデータをそのまま扱うと、AIは数値が大きい変数を過大評価してしまいます。
・標準化(Standardization):平均0、分散1に変換。外れ値の影響をある程度抑えられます 。
・正規化(Normalization):最小値0、最大値1に変換。分布の形状を維持したい場合に有効です 。
交互作用項と多項式特徴量:非線形性の捕捉
単一の変数では説明できない複雑な関係性を捉えるためのテクニックです。
● 交互作用項
「駐車場台数 × 駅距離」のように変数を掛け合わせます。「駅近なら駐車場は不要だが、駅遠なら必須」といった相乗効果(または打ち消し効果)をモデルに組み込むことができます。
● 多項式特徴量
変数を2乗、3乗します。「人口が増えれば売上も増えるが、ある程度で頭打ちになる」といった非線形なカーブを表現するのに役立ちます。
しかし、これらの変数を無闇に増やすと「多重共線性(マルチコ)」という問題が発生します。相関の高すぎる変数が複数存在すると、重回帰分析においては係数の推定が不安定になり(例えば、プラスになるはずの人口の係数がマイナスになるなど)、解釈不能なモデルになってしまいます。これを防ぐための「変数選択」や「正則化」といったテクニックも、高度な特徴量エンジニアリングの一部です。
重回帰分析 vs 機械学習 — 「納得感」と「精度」のジレンマを解消する
特徴量エンジニアリングと並んで重要なのが、予測モデルの選択です。伝統的な「重回帰分析」と最新の「機械学習」、どちらを選ぶべきでしょうか。
重回帰分析:ビジネスの共通言語としての信頼性
重回帰分析は、統計学に基づいた伝統的な手法であり、数式が以下のようにシンプルな一次式で表現されます。

【重回帰のメリット】
・解釈性が高い: 「駅徒歩分数が1分減ると、売上が◯万円上がる」というように、各変数の影響度(係数)が明確であり、人間にとって直感的に理解しやすい。
・説得材料として強力: 出店稟議書や撤退基準の説明資料において、「なぜこの予測値なのか」という根拠(ロジック)を明示できるため、経営層やFCオーナーの合意形成を得やすい。
・少ないデータでも機能する: 学習に必要なデータ数が比較的少なくても、安定した結果が得られやすい。
【重回帰のデメリット】
・複雑なパターンを捉えられない: 基本的に直線的な関係しか表現できないため、現実世界の複雑な非線形関係(ある閾値を超えると急激に売上が下がる等)を捉えきれず、予測精度に限界がある。
機械学習:高精度が生むブラックボックス問題
ランダムフォレストやニューラルネットワークなどの機械学習は、予測精度において重回帰を凌駕します。
【機械学習のメリット】
・圧倒的な予測精度: 変数間の複雑な相互作用や非線形な関係性を自動的に学習するため、重回帰では捉えきれない微細なパターンを反映できる。
・多様なデータの活用: 画像やテキスト、時系列データなど、非構造化データに近い情報もモデルに取り込みやすい。
【機械学習のデメリット】
・ブラックボックス性: 内部計算が極めて複雑であるため、「なぜAIがその予測値を出したのか」を人間が理解・説明することが困難。「AIが言っているから」という理由だけでは、数千万円の投資判断を下せないという経営判断の壁にぶつかることが多い。
「デュアルアプローチ」という解決策
この「解釈性(重回帰)」と「精度(機械学習)」のトレードオフを解消するのが、技研商事インターナショナルの「THE NOVEL」が採用する「デュアルアプローチ(業界初)」です。
「THE NOVEL」は、ユーザーがデータを投入すると、裏側で「重回帰分析」と「機械学習」の両方のエンジンを同時に駆動させます。そして、それぞれのモデルの精度を自動的に検証・比較し、最適な結果をユーザーに提示します。
・2つのエンジンを同時実行
重回帰と機械学習の両方を自動で走らせ、データ特性に応じて最適なモデルを提案します。
・XAI(説明可能なAI)の実装
機械学習を採用した場合でも、SHAP値などの技術を用いて「どの変数が予測に寄与したか」を可視化・言語化します。
これにより、「機械学習の高精度」と「重回帰のような納得感」を両立させ、専門知識がないビジネスパーソンでも自信を持って意思決定を行える環境を提供します 。

まとめ
AI売上予測の成功を握るのは、魔法のようなアルゴリズムではなく、「特徴量エンジニアリング」という泥臭くも創造的なデータ加工プロセスです。
現場の「暗黙知」をAIが理解できる「形式知」へと翻訳し、ビジネスの実態に即した特徴量を設計すること。そして、重回帰分析の「説明力」と機械学習の「予測力」をハイブリッドに活用すること。これこそが、不確実な市場環境で勝ち残るための、科学的かつ強力な武器となります。
データと現場の知見を融合させ、次世代のデータドリブン経営を実現していきましょう。
監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員CMO シニアコンサルタント |
|
| 一般社団法人LBMA Japan 理事 ロケーションプライバシーコンサルタント 流通経済大学客員講師/共栄大学客員講師 医療経営士/介護福祉経営士 Google AI Essentials/Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/




