業界の最新動向をチェック
エリアマーケティングラボ
アンサンブル学習とは?機械学習モデルの種類と手法
2025/12/25
2025年12月25日号(Vol.204)
当社が専門とする「エリアマーケティング」の領域においては、実店舗の売上や顧客の来店行動は、商圏内の人口や世帯数といった単純な人口統計データ(デモグラフィクス)だけでなく、競合店の配置、道路の接続状況、地域の嗜好性、さらには昼夜間人口の変動といった無数の変数が複雑に絡み合った結果として現れます。これら多数の要因が非線形に相互作用する現象を、単一の数理モデルで解き明かすことには、もはや限界が生じています。
こうした中、データサイエンスの最前線で「予測精度の切り札」として定着している技術があります。それが本コラムの主題である「アンサンブル学習」です。
アンサンブル学習は、一人の天才的な予測モデルに頼るのではなく、多数の多様なモデル(学習器)を構築し、それらの予測を統合することで、より堅牢で精度の高い結論を導き出す手法です。これは、人間社会における「集合知」の概念をアルゴリズムに応用したものと言えます。
本コラムでは、マーケティング担当者や経営企画のプロフェッショナルに向けて、アンサンブル学習の理論的背景から、バギング・ブースティング・スタッキングといった主要な手法、そしてRandom ForestやXGBoostなどの具体的アルゴリズムまでを、専門用語の壁を取り払いながらわかりやすく解説します。
アンサンブル学習の理論的基盤
「集合知」の数学的裏付け
アンサンブル学習の本質は、「三人寄れば文殊の知恵」を数学的に実装することにあります。単独のモデルが完璧である必要はありません。むしろ、精度が多少低くても、それぞれが異なる視点やバイアスを持ったモデルを多数組み合わせることで、個々の誤りを相殺し、真実に近い予測を得ることが可能になります。
機械学習においても同様に、多様性のあるモデル群を作成し、その予測を統合(多数決や平均化)することで、単一モデルよりも優れた性能を発揮します。

なぜ複数のAIを使うと精度が上がるのか
機械学習モデルの予測誤差は、主に「バイアス(大雑把さ)」と「バリアンス(神経質さ)」、そして削減不可能な「ノイズ」の3要素に分解されます。

一般に、モデルを複雑にすればバイアスは下がりますがバリアンスが上がり(過学習)、単純にすればバリアンスは下がりますがバイアスが上がります(学習不足)。これを「バイアス・バリアンスのトレードオフ」と呼びます。
アンサンブル学習は、たくさんのAIを組み合わせることで、この「大雑把さ」と「神経質さ」のバランスをうまくとり、どんな状況でも安定して正解を出せるようにするテクニックなのです。
アンサンブル学習の主要なアプローチ
アンサンブル学習には、モデルの構築と統合の方法によって、主に3つのアプローチが存在します。それぞれの特性を理解し、課題に応じて使い分けることが重要です。
バギング
バギングは「並列」のアプローチです。元のデータから、ランダムにデータを抽出して複数のデータセットを作成します。そして、それぞれのデータセットに対して独立してモデルを学習させ、最後にそれらの予測結果を集約します。
分類問題の場合:多数決で最終クラスを決定。
回帰問題の場合:全モデルの予測値の平均を算出。
【メリット】
バギングの最大の利点は、「過学習への耐性」です。個々のモデルがデータの一部に過剰適合してしまっても、他の多数のモデルと平均化することで、その極端な判断が相殺され、滑らかな予測が得られます。ノイズの多いデータセット(例:アンケート結果や天候データを含む売上データなど)において特に有効です。

ブースティング
ブースティングは「直列」のアプローチです。バギングのように独立して学習するのではなく、モデルを順番に作成していきます。
1. 最初のモデルを作成し、予測を行う。
2. そのモデルが予測を外した(誤差が大きい)データに対し、重み付けを行う。
3. 次のモデルは、重み付けされた「難しいデータ」を重点的に学習するように構築される。
4. このプロセスを繰り返し、最終的に全てのモデルを重み付きで統合する。
【メリット】
ブースティングは、前のモデルの弱点を次々と補強していくため、「予測精度(Biasの低減)」において圧倒的な性能を発揮します。データに潜む複雑なパターンや微細なシグナルを捉える能力に長けており、Kaggleなどのデータ分析コンペティションでは優勝モデルの常連となっています。
一方で、ノイズまで学習してしまうリスク(過学習)があり、ハイパーパラメータの調整が難しいという側面もあります。
スタッキング
スタッキングは、異なる種類のモデル(決定木、ロジスティック回帰、ニューラルネットワーク、SVMなど)を組み合わせる階層的な手法です。
第1段階:複数の異なるアルゴリズムで予測を行い、その予測値を出力します。
第2段階:第1段階の予測値を「新たな特徴量(入力データ)」として受け取り、最終的な予測を行うモデルを学習させます。
【メリット】
スタッキングは、全く異なるアルゴリズムの「得意分野」を融合できる点が強みです。例えば、全体的なトレンドを捉えるのが得意な線形モデルと、局所的な異常値を捉えるのが得意な近傍法を組み合わせることで、単一の手法では到達できない精度を実現します。ただし、モデルの構造が極めて複雑になり、計算コストと実装難易度が跳ね上がるため、実務での運用には高度な環境が必要です。
代表的なアルゴリズムとその特性
アンサンブル学習の理論を実装した具体的なアルゴリズムについて、マーケティング応用の視点から解説します。
ランダムフォレスト
バギングの代表格であり、実務で最も広く使われているアルゴリズムの一つです。
・仕組み
多数の「決定木」を作成します。バギング(データのランダムサンプリング)に加え、各分岐点で使用する特徴量(説明変数)もランダムに選択します。これにより、似通った木ができるのを防ぎ、多様性を最大化しています。
・マーケティング活用
┗特徴量重要度の算出:ランダムフォレストは、「どの変数が予測に寄与したか」を数値化できます。例えば、店舗売上予測において「駅距離」「商圏人口」「競合店数」のうち、どれが最も効いているかを可視化できるため、施策の優先順位付けに役立ちます。
┗扱いやすさ:パラメータ調整が比較的容易で、デフォルト設定でも高い性能が出やすいため、初期分析のベースラインモデルとして最適です。

勾配ブースティング決定木
ブースティングの考え方をさらに洗練させ、「勾配降下法」を用いた手法です。前のモデルの「残差(正解と予測のズレ)」を、次のモデルが予測するように学習を進めます。
XGBoost
勾配ブースティング決定木を高速化し、正則化項(モデルの複雑さを抑えるペナルティ)を導入して過学習を防ぐ工夫を凝らしたライブラリです。・特徴:欠損値を自動的に処理する機能を持ち、大規模データに対しても高速に動作します。数年前までデータ分析コンペの上位を独占していた伝説的なアルゴリズムです。
LightGBM
Microsoftが開発した、XGBoostよりさらに高速でメモリ効率が良いアルゴリズムです。・特徴:「Leaf-wise」という木の成長戦略を採用しており、深い探索を行うことで高い精度を実現します。数百万件の顧客データ(ID-POSなど)を扱うような大規模分析において、現実的な処理時間で解を得るためのデファクトスタンダードとなっています。
CatBoost
Yandexが開発したアルゴリズムで、特にカテゴリカル変数(質的データ)の扱いに優れています。・特徴:通常、機械学習モデルに「都道府県」や「性別」などの文字データを入れる際は数値変換(エンコーディング)が必要ですが、CatBoostはこれを自動かつ高精度に行います。顧客属性や地域区分などの質的変数が多いマーケティングデータ分析において、前処理の手間を大幅に削減します。
エリアマーケティングへの応用とGISの融合
ここからは、当社の専門領域である「エリアマーケティング」において、なぜアンサンブル学習が革新的なのかを深掘りします。
空間的異質性の克服
地理的データには「場所によって関係性が変わる」という特性があります。これを空間的異質性と呼びます。
例えば、「駐車場台数」と「店舗売上」の関係を考えてみましょう。
郊外ロードサイド:車での来店が前提のため、駐車場台数は売上に強い正の相関を持ちます。
都心駅前:徒歩や公共交通機関での来店が主であり、駐車場は不要。むしろ、駐車場スペースを売場にした方が売上が上がる可能性があります。
従来の単一の回帰モデルでは、これらを「全エリアの平均」として処理してしまうため、「駐車場は少しプラスの効果がある」という、どのエリアにも当てはまらない曖昧な結論しか出せません。
一方、決定木ベースのアンサンブル学習は、データを条件分岐によって分割します。「都心フラグ=1のグループ」と「郊外フラグ=1のグループ」で異なるルールを学習できるため、場所ごとの特性(異質性)を自動的にモデルに組み込み、高精度な予測を実現します。
非線形な商圏特性の捕捉
商圏における事象は、直線的な比例関係にないことがほとんどです。
飽和効果:商圏人口が増えれば売上は増えますが、ある一定数を超えると店舗オペレーションの限界や混雑回避行動により、売上の伸びは鈍化(飽和)します。
閾値効果:例えば、特定の年齢層の比率があるライン(閾値)を超えた瞬間に、特定の商品カテゴリーの需要が爆発的に増えるといった現象です。
アンサンブル学習は、このような非線形な関係性を捉える能力に長けています。複雑な現実世界を無理やり直線に当てはめることなく、ありのままのパターンとして学習できる点が、既存の統計手法に対する圧倒的な優位性です。

空間的自己相関と「THE NOVEL」のアプローチ
「近くにあるものは、遠くにあるものよりも似ている」。これは地理学の第一法則であり、空間的自己相関と呼ばれます。隣り合うメッシュ(区画)の年収や消費性向は似通る傾向があります。
当社の提供するGISソリューションは、この空間的構造を考慮したデータ(空間ラグ変数など)を生成し、アンサンブル学習モデルに投入することで、単なる属性分析を超えた、地理的な文脈を理解した予測を可能にします。
「THE NOVEL」が実現する高度分析の民主化
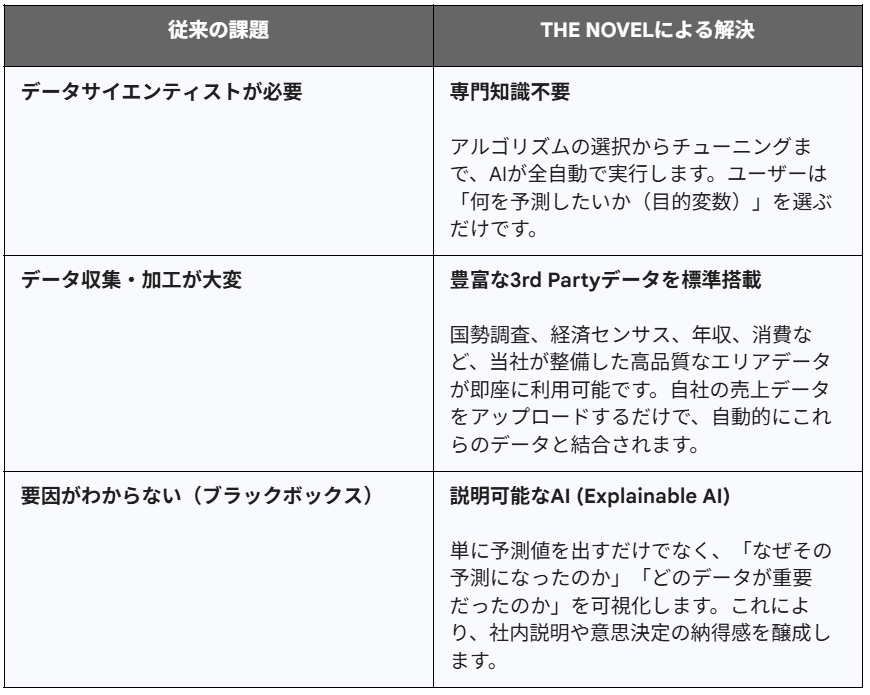
これまで述べてきたように、アンサンブル学習は極めて強力な技術です。しかし、これを自社のマーケティング実務に導入しようとすると、巨大な「実装の壁」に直面します。
導入を阻む3つの壁
高度な専門知識の不足:適切なアルゴリズムの選択、ハイパーパラメータのチューニング(数多くの設定値の調整)、過学習の防止など、データサイエンティスト級のスキルが必要です。
データ準備の泥沼:予測モデルを作るためには、社内データだけでなく、人口統計、人流、競合店データなどを収集し、それらを正確に紐付ける(空間結合)という膨大な前処理が必要です。
計算リソースとコスト:何千もの決定木を計算するには高性能なサーバーが必要であり、クラウド環境の構築・維持コストがかかります。

「THE NOVEL」によるソリューション
当社、技研商事インターナショナルの「THE NOVEL」は、これらの壁を破壊し、誰でも最先端のアンサンブル学習を利用可能にする「AutoML(自動化された機械学習)搭載型・商圏分析ツール」です。
活用シナリオ:THE NOVELで変わる業務フロー
シナリオA:小売チェーンの「高精度売上予測」
・Before開発担当者の勘と経験、またはExcelでの単純な重回帰分析に頼っており、新店オープン後に「想定外の売上不振」が頻発。
・THE NOVEL
既存店の売上データを取り込むだけで、商圏内の人口構成、昼間人口、競合店など数百の変数から、AIが自動的にアンサンブル学習モデルを構築。
・結果
候補物件の住所を入力するだけで、高精度な予測売上が算出される。さらに「なぜ高いのか(例:30代ファミリー層が多く、かつ競合店から適度に離れているため)」という根拠も示されるため、出店判断の質とスピードが劇的に向上する。
シナリオB:消費財メーカーの「販促エリア最適化」
・Before「とりあえず人口の多いエリア」に一律でサンプリングや広告投下を行っており、費用対効果(ROI)が悪化していた。
・THE NOVEL
過去のキャンペーン反応率やID-POSデータを教師データとして学習。
・結果
「人口は少ないが、当該カテゴリの消費性向が高く、かつ特定のライフスタイルの人が集まるエリア」という、人間では気づかないニッチな高反応エリア(ホットスポット)を発見。広告予算をそこに集中投下することで、ROIを最大化する。

まとめ
本コラムでは、現代のマーケティングにおいて、なぜ従来の分析手法ではなく「アンサンブル学習」が必要なのか、その理論的背景と実務的優位性について解説してきました。
複雑性の克服:現代の市場環境はあまりに複雑であり、単一のモデルでは捉えきれません。多数のモデルの知恵を結集するアンサンブル学習こそが、この複雑性に立ち向かう唯一の解です。
非線形な現実への適応:エリアマーケティング特有の「空間的異質性」や「非線形な相互作用」を捉えるには、決定木ベースのアンサンブル手法(ランダムフォレスト、LightGBMなど)が最適です。
技術の民主化:かつては専門家だけの特権だったこの技術は、「THE NOVEL」によって民主化されます。
もはや、高度なデータ分析を行うために、高額なデータサイエンティストを採用したり、何ヶ月もかけてシステムを構築したりする必要はありません。「THE NOVEL」は、貴社のマーケティングチームに即座に「データサイエンスの頭脳」を提供します。
最小限のデータから、最大限の洞察(インサイト)を引き出す。そして、不確実な未来を、根拠ある「予測」へと変える。技研商事インターナショナルの「THE NOVEL」で、貴社のマーケティングを次なるステージへと進化させてください。
監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員 マーケティング部 部長 シニアコンサルタント |
|
| 医療経営士/介護福祉経営士 流通経済大学客員講師/共栄大学客員講師 一般社団法人LBMA Japan 理事 Google AI Essentials Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



