
エリアマーケティングラボ
需要予測ツール・システムの種類や機能、選び方を実務視点で解説!
2026年2月25日号(Vol.217)
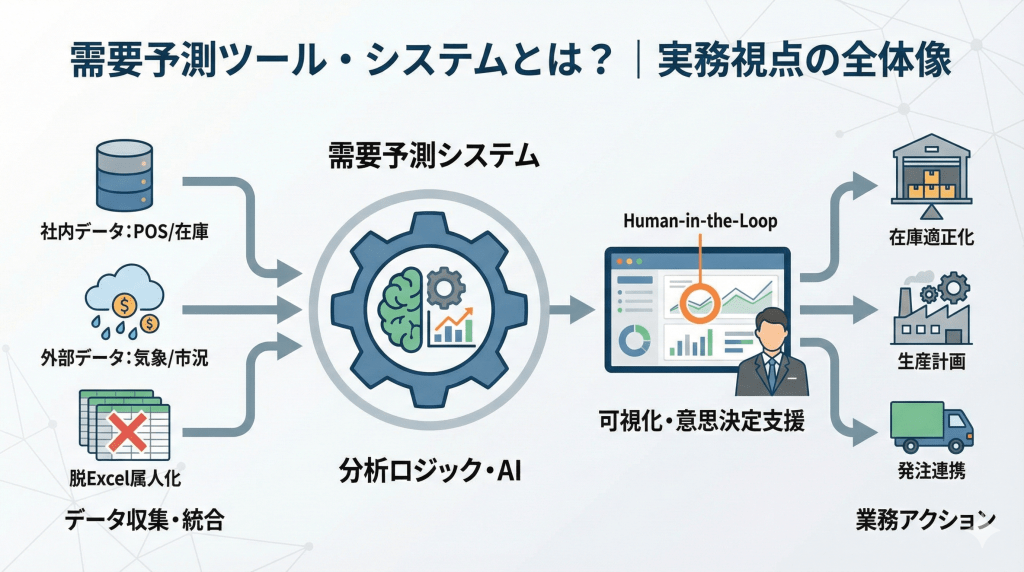
ビジネスの不確実性が高まる中、在庫やコストの最適化を目指し、AIによる需要予測への関心が高まっています。 しかし現場では、ツールの設計不足により「導入しても使いこなせない」というギャップが少なくありません。
需要予測の本質は単なる分析ではなく、利益に直結する「意思決定」を支える業務プロセスそのものです。 単に精度の高さを追うのではなく、データの入力から実務アクションまでをシームレスにつなぎ、組織として使い続けられる「仕組み」を構築することこそが、真のDXと言えます。
本コラムでは、需要予測ツールの種類や機能、導入時の落とし穴、そして自社に最適なシステムを選定するための考え方を整理します。「AIが当たるかどうか」という一点のみに囚われるのではなく、「組織として使い続けられるか」「利益を生むアクションにつながるか」という実務視点に立ち、徹底的に解説していきます。
- 第1回 需要予測とは何か?|定義・目的からビジネスでの重要性までを体系的に解説
- 第2回 需要予測の手法・モデルを基礎から徹底解説!自社に最適な手法の選び方が分かる
- 第3回 AI・機械学習による需要予測|従来手法との違いと実務での活かし方
- 今回はココ 第4回 需要予測ツール・システムの種類や機能、選び方を実務視点で解説!
- 第5回 【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
<name="#1" id="1">
需要予測ツール・システムとは何か
<name="#1-1" id="1-1">分析ロジックと業務運用の融合
需要予測ツールとは、過去の売上実績データや市場トレンド、気象情報などの関連データをもとに将来の需要を予測し、その結果を日々の業務オペレーション(発注、生産計画、要員配置など)で活用するための仕組み全体を指します。
ここで重要なのは、単なる計算ロジック(アルゴリズム)だけでなく、以下のような一連のサイクルを含む「総合的なシステム」と捉える必要がある点です。
データを集める:社内外の多種多様なデータを自動収集する。
データを整える:欠損値の補完や異常値の処理を行い、分析可能な状態にする。
予測を実行する:最適なモデルを選択し、将来の数値を算出する。
結果を確認・比較する:予実管理を行い、精度をモニタリングする。
業務判断につなげる:ERPやWMS(倉庫管理システム)へデータを連携し、自動発注などを行う。
「分析ツール」と「業務システム」の違い
多くの企業で混同されがちなのが、「分析ツール」と「業務システム」の違いです。
統計解析ソフトや一般的なBIツールなどの「分析ツール」は、特定のアナリストが精緻なモデルを作成し、予測値を算出することに長けています。しかし、それを日々のルーチンワークとして回し、数百・数千アイテムの発注データとして出力するには、機能が不足しているケースが大半です。
一方、需要予測ツール(システム)は、現場担当者が毎日・毎週使うことを前提に設計されています。「いつまでにデータを入稿すれば、いつ発注データが確定するか」というタイムライン管理や、アラート機能、承認ワークフローなど、業務遂行に必要な機能が備わっている点が決定的な違いです。
需要予測ツールは、単発の研究的な分析ではなく、企業のサプライチェーンを動かし続けるための「心臓部」としてのインフラと考えるべき存在なのです。
<name="#2" id="2">
需要予測ツールの主な種類
市場には多種多様なツールが存在しますが、大きく以下の5つのタイプに分類できます。自社の規模や課題感、リテラシーに合わせて選択することが重要です。 <name="#2-1" id="2-1">1. Excel・スプレッドシートベース
【特徴とメリット】
中小企業から大企業まで、依然として最も広く利用されているのがExcelやGoogleスプレッドシートによる需要予測です。初期コストがほぼゼロであり、関数やマクロを組める人材がいれば、自社の業務ルールに完全にフィットしたフォーマットを即座に作成できる手軽さが最大のメリットです。現場担当者にとっても、使い慣れたインターフェースであるため、導入教育のコストがかかりません。
【デメリットと限界】
一方で、組織的な運用においては以下のような深刻な「Excelの罠」が顕在化します。
・属人化の極み
「あのマクロはAさんしか触れない」という状況が生まれやすく、担当者が退職すると業務が停止するリスクがあります。
・データ容量と処理速度
データ行数が数万件を超えると動作が重くなり、ファイル破損のリスクが高まります。
・計算ロジックのブラックボックス化
複雑なセル参照や関数が入り組み、計算ミスに気づかないまま発注してしまう事故が起こり得ます。
・バージョン管理の煩雑さ
「最新版」ファイルがどれか分からなくなり、先祖返りが発生するトラブルも頻発します。
Excelは、プロトタイピング(試作)や小規模な運用には適していますが、全社的なサプライチェーンを支える「回し続ける」仕組みとしては、ガバナンスと継続性の観点から限界があります。
2. BI・分析ツール型(Tableau, Power BIなど)
【特徴とメリット】
TableauやMicrosoft Power BI、Qlik Senseなどの汎用BI(ビジネスインテリジェンス)ツールには、時系列分析や回帰分析といった需要予測に使える機能が標準またはプラグインで備わっています。
最大の特徴は、圧倒的な「可視化能力」です。過去の実績と予測値を美しいグラフで重ねて表示したり、地域別・商品カテゴリー別にドリルダウンして要因を分析したりすることが得意です。経営層へのレポーティングツールとしても優れています。
【デメリットと限界】
あくまで「データの可視化と分析」が主目的であるため、算出した予測値をそのまま発注システムへ連携するような「書き込み(Write-back)」機能や業務フロー制御は弱い傾向にあります。
また、予測モデルを構築・調整するためには、データサイエンスの知識を持った分析担当者が必要となるケースが多く、現場部門だけで自律的に運用するにはハードルが高い場合があります。業務システムとの連携には、別途データベースの構築やETL処理の開発が必要になることも、導入コストを押し上げる要因となります。

3. 専用需要予測システム
【特徴とメリット】
需要予測そのものを目的として開発されたパッケージソフトウェアやSaaSです。「小売業向け」「食品製造業向け」「自動車部品向け」など、特定の業界特性や商習慣(特売の影響、賞味期限管理、補修部品のロングテール需要など)に最適化されたロジックがあらかじめ組み込まれています。
ゼロから開発する必要がなく、導入後すぐに業界のベストプラクティスに基づいた運用を開始できる点が強みです。カレンダー機能やイベント管理機能など、現場実務に即したUIが用意されていることが多いです。
【デメリットと限界】
業界標準の機能が豊富である反面、内部の予測ロジックがユーザーから見えない「ブラックボックス」になりがちです。「なぜ、来週の予測が急に増えたのか?」という現場の疑問に対し、「システムがそう弾き出したから」としか答えられない場合、現場の信頼を失い、使われなくなるリスクがあります。
また、自社独自の特殊な業務ルールがある場合、パッケージ機能では対応しきれず、高額なカスタマイズ費用が発生する可能性があります。
4. ERP・SCMシステム内蔵型(SAP, Oracleなど)
【特徴とメリット】
SAPやOracleなどのERP(統合基幹業務システム)や、専用のSCM(サプライチェーン管理)モジュールに含まれる需要予測機能を利用するパターンです。
最大のメリットは「データと業務の統合」です。販売実績、在庫情報、入庫予定などのデータが同じデータベース内にリアルタイムで存在するため、データ収集の手間がありません。予測結果はそのままMRP(所要量計算)や発注勧告データとして直結し、シームレスに業務が流れます。
【デメリットと限界】
ERP内蔵の予測機能は、多くの場合、移動平均法や指数平滑法などの古典的な統計手法が中心で、昨今のAIブームで期待されるような「外部要因(天気、人流など)を加味した高度な予測」には対応していない、あるいはオプション対応となるケースがあります。
また、ERP全体に関わる大規模なシステムとなるため、導入・改修には莫大なコストと時間がかかります。小回りが利きにくいため、市場環境の変化に素早く対応したい現場にとっては、重厚長大すぎて扱いづらいと感じることもあります。
5. AI需要予測プラットフォーム(DataRobot, Vertex AIなど) 特徴とメリット
【特徴とメリット】
近年、急速に普及しているのが、機械学習(Machine Learning)やディープラーニングを活用したAI予測プラットフォームです。
AutoML(自動機械学習)機能を備えたものが多く、データさえ投入すれば、システムが自動的に数百種類のアルゴリズムを競わせ、最適なモデルを選定してくれます。
従来の統計手法では難しかった「非線形な関係」の学習が可能で、天候、競合価格、キャンペーン、SNSのトレンドなど、多様な変数を加味した高精度な予測が期待できます。
【デメリットと限界】
「AIは魔法の杖」ではありません。AIを導入すれば自動的に在庫が適正化されるわけではなく、その前段階である「教師データの整備」に膨大な工数がかかります。汚れたデータ(欠損だらけ、入力ミスなど)を学習させれば、誤った予測が出力されるだけです。
また、導入コストやランニングコスト(クラウド利用料)が高額になりがちで、ROI(投資対効果)を厳密に見極める必要があります。運用には、データエンジニアやデータサイエンティストとの協業、あるいはそれに準ずるスキルを持った社内人材の育成が不可欠です。

<name="#3" id="3">
需要予測システムの基本構成要素
どのようなツールを選ぶにせよ、需要予測システムとして機能するためには、以下の5つの要素が有機的に結合している必要があります。 <name="#3-1" id="3-1">1. データ収集・統合機能
需要予測の出発点はデータです。しかし、社内データはPOSシステム、在庫管理システム、基幹システム、Excelファイルなどに散在しています。これらを一元的に集約する機能が不可欠です。
さらに、精度向上のためには「外部データ」の取り込みも重要です。
気象データ:気温、湿度、降水量(飲料やアパレルに直結)
カレンダーデータ:祝日、連休、地域のイベント
経済指標:為替、原油価格、GDP成長率
これらのデータをAPIなどで自動取得し、社内データと紐付ける機能が求められます。

2. 前処理・データクレンジング
実務において最も工数がかかり、かつ重要なのがデータの前処理です。データサイエンスの現場では「8割の時間はデータ準備に使われる」と言われます。
欠損値処理:在庫切れで売上がゼロだった日のデータをどう扱うか(需要がなかったわけではない)。
異常値除去:台風による臨時休業や、特需によるスパイクを学習データから除外するか補正するか。
粒度の統一:日次データと月次データ、店舗別データとエリア別データの整合性をどう取るか。
この工程を属人的な手作業ではなく、ルールベースで自動化・仕組み化できるかどうかが、ツールの実用性を左右します。

3. 予測ロジック・モデル管理
実務では、単一のモデルで全ての商品を予測することは稀です。
定番品:安定しているため、移動平均などのシンプルな統計モデルで十分。
新商品:過去データがないため、類似品参照(類似の過去商品データを流用)モデルを使用。
販促品:キャンペーンの影響度を測るため、回帰分析や機械学習を使用。
このように、商品特性やライフサイクル(導入期、成長期、成熟期、衰退期)に応じて、複数のロジックを使い分ける機能が必要です。また、「最高精度」を追求するあまり計算に数時間かかるモデルよりも、業務時間内に確実に計算が終わる「安定性と再現性」のあるモデル管理が重要です。
4. 可視化・レポーティング
需要予測の結果は、現場の担当者(店長、バイヤー、工場長)が理解し、納得して初めて使われます。
単に「来週は100個売れます」という数値だけでなく、「なぜ100個なのか」という根拠を示す必要があります。
「昨年同週は80個だったが、来週は気温が5度上がるため+10個、キャンペーン効果で+10個と予測しました」といった具合に、予測の根拠(寄与度)を可視化できる機能(XAI:説明可能なAI)は、現場の納得感を得るための必須要件となりつつあります。

5. 業務連携・意思決定支援
予測結果が出た後、それをどうアクションにつなげるかです。
アラート機能:予測と実績が大きく乖離した場合、担当者に通知を飛ばす。
修正機能:AIの予測値をベースに、担当者が「地域の運動会がある」といった定性情報を加味して数値を手動修正できるUI。
システム連携:確定した予測値を、発注システムや生産計画システムへCSVやAPIで自動連携する。
ここまで含めて設計されていなければ、ツールは単なる「見るだけのダッシュボード」で終わってしまいます。

<name="#4" id="4">
良い需要予測ツールに共通する要件
成功している企業の需要予測システムには、共通する思想と要件があります。 <name="#4-1" id="4-1">精度だけを過度に強調しない(KPIの適切な設定)
「予測精度100%」は不可能です。良いツールやシステムは、予測が外れることを前提に設計されています。
予測誤差(RMSEやMAPEなど)を最小化することだけを目指すのではなく、「外れたときにどうリカバリーするか」「欠品コストと在庫過多コストのどちらを優先して回避するか」といったビジネスルールを組み込める柔軟性を持っています。
データ追加や条件変更に柔軟に対応できる
ビジネス環境は常に変化します。新しい販売チャネルが増えたり、競合他社が出現したりした場合、新たな変数をモデルに追加する必要があります。
この変更を行うたびにベンダーへの高額な改修費用が発生するシステムでは、変化のスピードについていけません。ユーザー側でパラメータ調整やデータ追加がある程度行える「運用上の柔軟性」が重要です。
現場の判断を前提にした設計になっている(Human-in-the-Loop)
完全自動化を目指すのではなく、「AIが提案し、人が決断する」という協働スタイル(Human-in-the-Loop)を前提としています。
例えば、コロナ禍のような未曾有の事態や、テレビ紹介による突発的な需要は、過去データに基づくAIでは予測不可能です。こうした例外事象に対して、現場の人間が直感的に介入・補正できるインターフェースが用意されていることが、実務での使いやすさを決定づけます。

<name="#5" id="5">
需要予測ツール導入でよくある失敗
ツール導入プロジェクトが失敗する典型的なパターンを知り、対策を講じることが重要です。 <name="#5-1" id="5-1">
失敗1:魔法の杖シンドローム
「AIツールを入れれば、勝手にデータが集まり、明日から在庫が最適化される」と経営層が誤解しているケースです。
現実: データ整備や業務プロセスの見直し(BPR)を後回しにしたままツールだけ導入しても、ゴミデータからゴミ予測が量産されるだけです(Garbage In, Garbage Out)。まずはデータの棚卸しから始める必要があります。
<name="#5-2" id="5-2">
失敗2:現場との乖離と抵抗
本社主導で高機能なツールを導入したが、現場(店舗や工場)の意見を聞いていなかったため、「使いにくい」「現場の勘の方が当たる」と反発を招くケースです。
現実: 現場は「予測が当たるか」以上に「作業が楽になるか」を見ています。既存の業務フローを無視したツールは定着しません。導入初期から現場キーマンを巻き込み、UI/UXの検証を行うことが不可欠です。
<name="#5-3" id="5-3">
失敗3:PoC(概念実証)疲れ
「精度90%以上出ないと導入しない」といった高すぎるハードルを設定すると、いつまでもゴールできません。「現状の担当者予測より少しでも良ければOK」「業務工数が半分になればOK」といった、現実的なKPIを設定してスモールスタートすることが成功の秘訣です。

<name="#6" id="6">
自社に合った需要予測ツールの選び方
数あるツールの中から自社に最適なものを選ぶための、具体的なステップを提案します。 <name="#6-1" id="6-1">
ステップ1:現状の課題と目的の明確化
課題は何か?:欠品を減らしたいのか、在庫を減らしたいのか、発注業務の工数を削減したいのか。
予測対象は?:SKU数はいくつか。新商品が多いのか、定番品が多いのか。日次予測が必要か、週次で良いか。
ユーザーは誰か?:本部のデータサイエンティストか、各店舗の店長か。
<name="#6-2" id="6-2">
ステップ2:自社のリテラシーと体制の確認
分析専任の担当者がいない組織で、高度なプログラミングが必要なプラットフォームを導入しても運用は続きません。
「誰がモデルをメンテナンスするのか」という運用体制を見据え、内製化を目指すのか、コンサルティング込みのフルマネージドサービスを利用するのかを判断します。
<name="#6-3" id="6-3">
ステップ3:長期的なコスト試算(TCO)
初期導入費(イニシャルコスト)だけでなく、運用費(ランニングコスト)、モデル再学習に伴う追加費用、データ量増加による従量課金などをトータルで計算します。
安易に安価なツールを選ぶと、データ連携の開発費が膨らんだり、機能不足で別ツールを買い足すことになったりするため注意が必要です。

<name="#7" id="7">
需要予測ツールは「導入後」が本番
最も強調したいのは、需要予測ツールは「導入して終わり」ではなく「導入してからがスタート」であるという点です。 <name="#7-1" id="7-1">
PDCAを回し、モデルを育てる
導入直後の予測精度が完璧であることは稀です。運用を開始し、予測と実績の乖離(予実差)を分析し、なぜ外れたのかという原因を特定します。
「特売の影響を過小評価していた」「競合店の閉店情報を加味していなかった」といった発見をモデルにフィードバックし、パラメータを調整する。この地道なチューニング(MLOps)を継続することで、自社専用の強力な予測エンジンへと育っていきます。
<name="#7-2" id="7-2">
業務ルールとのすり合わせ
ツールが出した予測値を、現場がどう使うかという「業務ルール」も進化させる必要があります。
「予測信頼度が低い商品は、安全在庫を多めに持つ」「予測信頼度が高い商品は、自動発注に切り替える」といったように、ツールの成熟度に合わせて業務プロセスそのものを最適化していく姿勢が求められます。
<name="#8" id="8">
まとめ:需要予測ツールは意思決定インフラである
需要予測ツールの本質は、未来を100%言い当てる水晶玉ではありません。不確実な未来に対して、データに基づいた論理的なシナリオを提示し、企業の「意思決定を安定させ、高速化させるためのインフラ」です。
ツール選定において、機能の多さや最新のAIアルゴリズムといったカタログスペックに目を奪われがちですが、本当に大切なのは以下の3点です。
現場が使いこなせるインターフェースか(定着性)
ビジネスの変化に合わせて柔軟に修正できるか(拡張性)
データからアクションまでの動線が繋がっているか(実効性)
「当たるかどうか」という精度の議論も重要ですが、それ以上に「業務で使えるか」「組織として続けられるか」という実務視点を持って選定・設計することが、需要予測DXを成功させる唯一の道です。
ツールはあくまで道具です。その道具を使って、どのようなサプライチェーンを築き上げたいのかというビジョンこそが、最も重要な成功因子となるでしょう。
監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員CMO シニアコンサルタント 市川 史祥 |
|
| 一般社団法人LBMA Japan 理事 ロケーションプライバシーコンサルタント 流通経済大学客員講師/共栄大学客員講師 統計士/医療経営士/介護福祉経営士 Google AI Essentials/Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/




