業界の最新動向をチェック
エリアマーケティングラボ
AI・機械学習による需要予測|従来手法との違いと実務での活かし方
2026/02/20
2026年2月20日号(Vol.216)
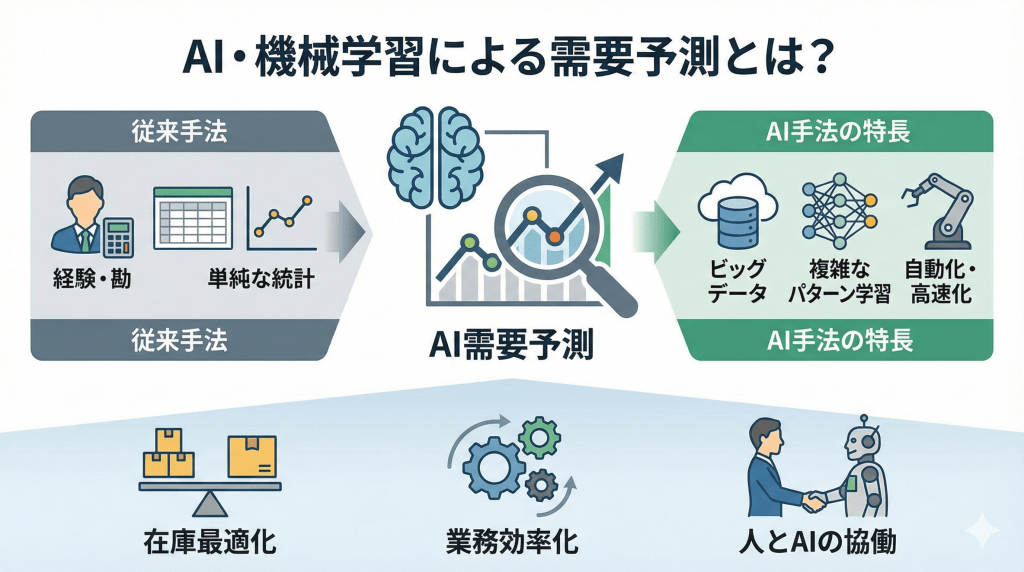
需要予測において、従来手法では対応しきれない市場の変化に対し、AIを用いた需要予測への期待が高まっています。
しかし導入現場からは「従来のExcelで行う手法との違いが分からない」「予測精度は上がったが、実務成果に繋がらない」といった戸惑いの声も少なくありません。AIは魔法の杖ではなく、強力な計算道具です。
本コラムでは、AI需要予測を実用的な道具として捉え直し、メカニズムから実務での活かし方、導入の注意点まで網羅的に解説します。
- 第1回 需要予測とは何か?|定義・目的からビジネスでの重要性までを体系的に解説
- 第2回 需要予測の手法・モデルを基礎から徹底解説!自社に最適な手法の選び方が分かる
- 今回はココ 第3回 AI・機械学習による需要予測|従来手法との違いと実務での活かし方
- 第4回 需要予測ツール・システムの種類や機能、選び方を実務視点で解説!
- 第5回 【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
AI・機械学習による需要予測とは何か
AI需要予測の基本的な考え方
AIを活用した需要予測の基本プロセスは、人間が経験則で行ってきたことを数学的に模倣し、それを圧倒的な計算量で拡張することにあります。
従来の需要予測(特に小規模な運用)では、担当者が「この商品は夏に売れる」「キャンペーンを打てば1.2倍になる」といったルールや構造を頭の中で考え、そのルールに基づいてExcelなどで予測値を算出するケースが一般的でした。
一方、AI・機械学習による需要予測では、アプローチが根本的に異なります。
大量のデータ(教師データ)を与える:過去の販売実績、日付、天候、価格など。
パターンを自動学習する:データの中に潜む「Aという条件のときはBになりやすい」という法則性をAI自身が見つけ出す。
モデルを構築する:学習した法則性の集合体(モデル)を作成する。
推論する:新しいデータ(未来の条件)をモデルに入力し、予測値をはじき出す。
ここで重要なのは、AIが人間の言葉の意味や市場の文脈を「理解している」わけではないという点です。AIはあくまで、過去データに含まれる数理的な傾向や相関関係を再利用し、確率的に最もありえる数値を計算しているに過ぎません。したがって、データに含まれていない事象(全く新しい社会現象など)を予測することは原理的に不可能です。
従来の統計モデルとの本質的な違い
ビジネスの現場では、長らく「移動平均法」や「指数平滑法」、「ARIMAモデル」といった統計的手法が使われてきました。これらと近年の機械学習(マシンラーニング)はどう違うのでしょうか。
■ 統計モデルのアプローチ
統計モデルは、「説明可能性」と「シンプルな構造」を重視します。ホワイトボックス:どの変数がどう影響しているかが数式で明確です。
線形性:基本的に「Aが上がればBも上がる」といった直線的な関係を仮定することが多いです。
少数の変数:過去の売上実績など、限られた変数(単変量)での予測が主です。
■ 機械学習(AI)のアプローチ
一方、機械学習は「予測精度」と「複雑性への対応」を重視します。非線形性:「気温が25度までは売上が上がるが、30度を超えると逆に下がる」といった複雑なカーブを描く関係性を捉えるのが得意です。
多変量(高次元):売上データだけでなく、天候、競合価格、SNSの口コミ数、カレンダー情報など、数百〜数千種類の要因(特徴量)を同時に処理できます。
相互作用の発見:「雨の日」かつ「週末」かつ「セール中」といった、要因同士の複雑な組み合わせによる影響を自動的に学習します。
両者は優劣の関係ではなく、役割が異なる手法と考えるのが適切です。単純な傾向把握なら統計モデルの方が低コストで運用しやすく、複雑な要因が絡み合う現代の市場予測には機械学習が適しています。
なぜ今、需要予測にAIが使われるのか
データ量・計算資源の劇的な変化(ビッグデータとクラウド)
AI需要予測が研究室レベルから実ビジネスの現場へと降りてきた最大の理由は、理論の進化以上に、インフラ環境の変化があります。
■ データの爆発的増加
POSレジのデータだけでなく、ECサイトの閲覧ログ、アプリの行動履歴、IoTセンサーによる在庫情報など、企業が取得・保持できるデータの種類と量が桁違いに増えました。これを人間が手作業で分析することはもはや不可能です。
■ 計算資源の低コスト化(クラウドの普及)
かつてはスーパーコンピュータが必要だった膨大な行列演算が、AWSやGoogle Cloud、Azureといったクラウドサービスを利用することで、安価かつ手軽に行えるようになりました。特にGPU(画像処理半導体)の活用により、深層学習などの計算コストが劇的に下がっています。
■ ライブラリ・ツールの充実
PythonやRといったプログラミング言語において、高性能な機械学習ライブラリ(Scikit-learn, TensorFlow, PyTorchなど)がオープンソースで提供され、データサイエンティストでなくとも高度な分析を試せる環境が整いました。
需要構造の複雑化(VUCA時代の到来)
消費者の行動は、以前よりも多様で流動的になっています。いわゆるVUCA(変動性、不確実性、複雑性、曖昧性)の時代において、従来の「前年踏襲」や「季節係数」だけでは説明できない変動が常態化しています。
季節性の崩壊:気候変動により「例年通りの気温」が通用しなくなっています。
マイクロトレンドの発生:SNSでの突発的なバズりにより、一夜にして需要が急騰・急落します。
オムニチャネル化:実店舗とECが相互に影響し合い(ショールーミングなど)、販売チャネルごとの予測が難しくなっています。
商品サイクルの短期化:新商品の投入サイクルが早まり、過去データが蓄積する前に商品が入れ替わるケースが増えています。
こうした複雑な需要構造は、人間が設定する単純な「if文(もし〜なら)」のルールや、単一の統計モデルだけでは捉えきれません。AIは、この人間には認知しきれない「複雑さ」や「ノイズに見えるごく僅かなシグナル」を扱える点において、現代のビジネス環境に不可欠なツールとして注目されています。

需要予測で使われる代表的な機械学習手法
決定木系モデル(勾配ブースティング決定木など)の考え方
現在、実務の需要予測(特に構造化データ)において最も広く使われ、高い成果を上げているのが「決定木」を応用したモデル(LightGBM, XGBoostなど)です。
▼ 基本的な発想
「もし○○なら需要はこうなる」という条件分岐(ツリー構造)を積み重ねる発想です。アキネーターのような「YES/NOクイズ」をイメージすると分かりやすいでしょう。
質問1:今日は平日か?(YESなら下へ)
質問2:気温は25度以上か?(NOなら下へ)
質問3:過去1週間の売上は平均以上か?(YESなら予測値は100個)
▼ なぜ実務で人気なのか
解釈しやすさ:どの条件が効いているのか(特徴量重要度)を可視化しやすいため、現場への説明責任を果たしやすい。
データの許容力:データの欠損や、数値のスケール(桁数)の違いに対して比較的頑健で、データの前処理の手間がニューラルネットワークに比べて少なくて済みます。
カテゴリ変数の扱い:「商品カテゴリ」や「店舗ID」といった数値ではないデータも扱いやすい。
アンサンブル学習の発想(集合知)
アンサンブル学習とは、1つの強力なモデルを作るのではなく、複数のモデルを組み合わせて予測する考え方です。「3人寄れば文殊の知恵」を数学的に行うものです。
・バギング(Bagging)
データを少しずつ変えて複数のモデルを作り、その平均を取ることで、極端な予測ミス(過学習)を防ぎます(例:ランダムフォレスト)。
・ブースティング(Boosting)
1つ目のモデルが間違えた部分を、2つ目のモデルが重点的に学習し、3つ目がさらに修正する…というように、弱点を補強しながら精度を高めていく手法です(例:勾配ブースティング)。
・スタッキング(Stacking)
全く異なる種類のモデル(線形回帰と決定木とニューラルネットなど)の予測結果を、さらに別のAIに入力して最終結論を出す高度な手法です。
実務では、「一発で完璧な数式」を求めるより、こうした「複数の視点を統合してリスクを分散する」アプローチの方が、安定して運用できます。

ニューラルネットワーク(ディープラーニング)の位置づけ
人間の脳の神経回路を模したニューラルネットワークは、画像認識や自然言語処理で有名ですが、需要予測(時系列解析)でも活用が進んでいます(LSTM, Transformerなど)。
・強み
非常に複雑なパターン、特に「長期的な依存関係(昨年の同じ時期だけでなく、3年前のトレンドが今影響しているなど)」や「非構造化データ(画像やテキスト)」を捉える能力を持っています。
・課題
大量のデータが必要:決定木系よりもさらに多くのデータを必要とします。データが少ないとすぐに過学習します。
ブラックボックス:なぜその予測値になったのか、中身が複雑すぎて人間には解釈不能になりがちです。
計算コスト:学習に時間がかかり、高価なGPU環境が必要です。
需要予測においては、画像データなどを併用する場合や、超大量のデータを保有する巨大テック企業などを除き、「精度が最優先され、説明責任が問われない場面」で慎重に使われることが多い手法です。一般企業の在庫予測などでは、まだ決定木系モデルの方が運用コスト対効果(ROI)が良いケースが大半です。

特徴量設計がAI需要予測の成否を分ける
特徴量(Feature Engineering)とは何か
AI需要予測プロジェクトが失敗する最大の原因は、モデルの選び方ではなく「入力データの作り方」にあります。AIの世界には「Garbage In, Garbage Out(ゴミを入れたらゴミが出てくる)」という格言があります。
最も重要な工程が、入力データを予測に役立つ形に加工する「特徴量設計(フィーチャー・エンジニアリング)」です。AIは生のデータをそのまま渡されても、うまく学習できません。人間が「AIが理解しやすい形」に翻訳してあげる必要があります。
需要予測における代表的な特徴量
需要予測では、次のような特徴量を作成し、AIに入力します。これらをどれだけ精緻に作れるかが、データサイエンティストや現場担当者の腕の見せ所です。
1.ラグ特徴量(過去の実績)
1日前、7日前(先週の同曜日)、365日前(昨年の同日)の売上数。
「昨日の売上が高ければ今日も高いはず」という直近の傾向を捉えます。
2.ウィンドウ特徴量(移動平均などの集計)
過去7日間の売上平均、過去30日間の売上最大値・最小値。
日々の細かな変動を平滑化し、ベースとなるトレンドを捉えます。
3.カレンダー特徴量(時系列要素)
曜日、月、旬、祝日フラグ。
「給料日前後」「ゴールデンウィーク」「連休の最終日」といった消費行動に影響するタイミングを数値化します。
「次の日が休みかどうか」というフラグも有効です。
4.イベント・キャンペーン情報
ポイント5倍デー、チラシ投函日、テレビCM放映期間。
これらは未来の予定として分かっているため、予測時に強力なヒントになります。
5.商品・店舗属性
商品カテゴリ、価格帯、賞味期限。
店舗の立地(駅前、ロードサイド)、駐車場の有無、競合店の距離。
6.気象データ
最高/最低気温、降水量、湿度。
単純な気温だけでなく「前日との気温差(急に寒くなった)」や「体感温度」の方が消費行動(アパレルやおでんの売上など)に影響する場合もあります。
特徴量設計が属人化しやすい理由と対策
「この商品は、雨が降ると売れるのではなく、雨が上がった直後に売れる」といった知見は、データサイエンティストだけでは気づけません。現場の店長やバイヤーが持っている暗黙知(ドメイン知識)こそが、最強の特徴量になります。
AI導入プロジェクトでは、データ分析の専門家と現場の業務エキスパートが対話する場を設けることが不可欠です。
現場:「給料日の後の最初の週末が一番売れるんだよ」
分析官:「では、『給料日から何日経過したか』という特徴量を追加してみましょう」
このように、現場の「勘」を「特徴量」という形に翻訳してAIに教え込むプロセスこそが、実務におけるAI構築の本質です。

AI需要予測の精度評価と注意点
精度が上がれば成功なのか(ビジネスKPIとの接続)
AI導入の目的が「予測精度の向上(誤差率の最小化)」だけになると、プロジェクトは迷走します。なぜなら、精度が数ポイント改善したとしても、ビジネス上のインパクトが出るとは限らないからです。
過剰在庫の削減:在庫回転率の向上、保管コストの削減
欠品の防止:機会損失の最小化、顧客満足度の維持
業務時間の短縮:発注担当者の工数削減
これらが達成されて初めて「成功」と言えます。例えば、売上が1日1個しかない商品の予測を「1.1個」と当てることにリソースを割くよりも、売上が1日1000個ある商品の誤差を5%縮める方が、ビジネスインパクトは大きくなります。
評価指標としては、一般的に以下が使われますが、使い分けが重要です。
MAE(平均絶対誤差):実際の個数とどれくらいズレたかの平均。在庫量そのものを把握したい場合に直感的。
RMSE(二乗平均平方根誤差):大きな外し方をペナルティとして重く評価する指標。突発的な大外しを避けたい場合に重視。
MAPE(平均絶対パーセント誤差):ズレを%で表したもの。規模が異なる商品同士の精度を比較するのに便利。

過学習(Overfitting)を直感的に理解する
AI運用で最も恐れるべき現象が「過学習」です。
これは、AIが過去のデータの「ノイズ」や「偶然」まで丸暗記してしまい、未知のデータ(未来)に対して全く通用しなくなる状態を指します。
【例え話】
過去問の答えを「1問目はア、2問目はウ…」と丸暗記した学生は、過去問では満点を取れますが、数字が変わった本番の試験では0点になります。これが過学習です。
需要予測では、「過去のデータに100%合致するモデル」は危険です。「過去の説明はある程度ラフだが、未来のデータに対しても安定してそこそこの精度を出す(汎化性能が高い)」モデルが優秀とされます。
検証と再学習(MLOps)の重要性
AIモデルは「作って終わり」ではありません。リリースした瞬間から、モデルの陳腐化(劣化)が始まります。これを「データドリフト」や「コンセプトドリフト」と呼びます。
消費者の好みの変化:タピオカブームのように、需要構造は変化します。
外部環境の変化:コロナ禍、法改正、増税、競合店の出店。
商品構成の変更:新商品の投入や廃番。
こうした変化に対応するためには、定期的に(例えば週次や月次で)最新のデータを取り込んでAIを再学習させるパイプライン(MLOps)の構築が必須です。これを怠ると、半年後には「全く当たらないAI」になってしまいます。

AI需要予測が向いているケース・向いていないケース
AIが力を発揮しやすいケース
1.データ量が十分にある
過去2〜3年以上の販売実績があり、SKU(商品数)が多い場合。データが多ければ多いほどAIは賢くなります。
2.需要変動の要因が多く複雑
天候、曜日、イベント、競合価格など、多数の変数が絡み合って需要が決まる商品(食品スーパー、コンビニ、アパレルなど)。
3.高頻度・多地点での予測
全国数千店舗×数万商品の毎日の発注数を決めるような、人間では処理しきれない規模の業務(自動発注システム)。
4.属人的判断を減らしたい
「ベテランのAさんしか発注ができない」というリスクを解消し、業務を標準化したい場合。

従来手法(人手や単純な統計)の方が適しているケース
1.データが極端に少ない
発売直後の新商品(コールドスタート問題)や、数年に一度しか売れない特殊な産業機械部品など。これらは人間の経験や類似商品からの類推の方が当たります。
2.説明責任が極めて重要
なぜその予測になったのかを株主や経営層に論理的に説明し、責任を負う必要がある中期経営計画の策定など。AIの「なんとなくこうなる」という出力は使いにくい場合があります。
3.突発的な社会的事象
法規制の変更やパンデミックなど、過去データに前例がない事態が発生した直後。AIは過去を知らないことには対処できないため、人間が介入してパラメータを修正する必要があります。
AI需要予測を業務に活かすためのポイント
モデルよりも業務設計(プロセス)が重要
高精度なAIモデルができても、現場が使ってくれなければ無価値です。AI需要予測プロジェクトは、システム開発というより「業務改革(BPR)」プロジェクトとして進めるべきです。
・誰が使うのか:本部のコントローラーか、店舗の発注担当者か。
・いつ使うのか:発注締め時間の1時間前に予測値が出ていなければ意味がない。
・どう判断に使うのか:
AI予測値をそのまま発注数として自動送信するのか(完全自動化)。
AI予測値を「参考値」として表示し、最終決定は人間が修正するのか(半自動化)。
初期段階では「参考値」として運用し、現場の信頼を得てから徐々に自動化範囲を広げるアプローチが定石です。
現場とのコミュニケーションと「納得感」
AIの予測結果(特に推奨発注数)に対して、現場は「多すぎる」「少なすぎる」と懐疑的になりがちです。ここで「AIが言っているから正しい」と押し付けると反発を招きます。
・予測の根拠を示す(XAI: Explainable AI)
「明日は気温が急激に下がり、かつ給料日後の週末なので、通常より20%増の予測です」というように、なぜその数値になったかの理由(寄与度)を提示するツールやダッシュボードを用意することが、定着の鍵となります。
・フィードバックループ
現場がAIの予測を修正した場合、その理由(「近所で運動会があるから」など)を記録させ、次回の学習に活かす仕組みを作ります。これにより、現場は「AIを育てている」という当事者意識を持てます。

AI需要予測と外部データ活用
外部データがもたらす価値
社内の売上実績(内部データ)だけでは、予測精度の向上には限界があります。需要は常に「外の世界」の影響を受けるからです。近年、多くの企業が外部データのプロバイダーと契約し、予測モデルに組み込んでいます。
1.気象データ
最も基本かつ強力なデータです。予報データを使うことで、リードタイム(発注から納品までの時間)を考慮した先回りの予測が可能になります。
2.人流データ
店舗周辺のリアルタイムな人口増減。イベント開催や鉄道の遅延などによる突発的な需要変動を捉えられます。
3.カレンダー・イベント情報
近隣の学校行事、コンサート情報、地域の祭事など。
4.SNS・Web検索データ
「風邪」という検索ワードが増えれば風邪薬が売れる、「タピオカ」の投稿が増えればブームが来る、といった先行指標として活用できます。

GIS・エリアデータとの親和性
特に多店舗展開する小売・飲食業では、GIS(地理情報システム)とAIの組み合わせが威力を発揮します。
・商圏分析
店舗ごとの商圏範囲内の人口構成(年齢、性別、世帯年収)を特徴量として学習させることで、「このエリアでは高級品が売れやすい」「学生街なので大容量パックが売れる」といった店舗ごとの個性をAIが加味できるようになります。
・カニバリゼーション(自社競合)の予測
近くに新店を出した場合、既存店の売上がどれくらい食われるかを予測する際にも、空間的な距離データは必須です。
まとめ:AIは需要予測をどう変えるのか
AI・機械学習は、需要予測を「魔法のように未来を透視する技術」にするものではありません。AIの本質的な価値は、以下の3点に集約されます。
扱える情報の次元を広げる:人間には処理しきれない多種多様なデータ(天候、人流、相関関係)を考慮に入れることができる。
業務の標準化と効率化:ベテランの勘に頼っていた予測業務を形式知化し、自動化・高速化することで、人間はより戦略的な業務(販促企画や商品開発)に時間を割けるようになる。
意思決定の精度向上:「なんとなく」ではなく「データによる裏付け」を持って在庫リスクをコントロールできるようになる。
統計・数理の考え方を土台にしつつ、現場の業務知見(ドメイン知識)をAIに学習させ、そしてAIが出した答えを人間がうまく使いこなす。「人かAIか」ではなく、「人とAIの協働(Human-in-the-loop)」こそが、これからの需要予測のスタンダードとなります。
次のステップとして、自社の課題に合った具体的なツール選定や、業界別の成功事例(ユースケース)を深くリサーチすることをお勧めします。まずは「スモールスタート」で、特定のカテゴリーや店舗からPoC(概念実証)を始めてみてはいかがでしょうか。
監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員CMO シニアコンサルタント 市川 史祥 |
|
|
一般社団法人LBMA Japan 理事 ロケーションプライバシーコンサルタント 流通経済大学客員講師/共栄大学客員講師 統計士/医療経営士/介護福祉経営士 Google AI Essentials/Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



