業界の最新動向をチェック
エリアマーケティングラボ
需要予測の手法・モデルを基礎から徹底解説!自社に最適な手法の選び方が分かる
2026/02/05
2026年2月10日号(Vol.214)
- 第1回 需要予測とは何か?|定義・目的からビジネスでの重要性までを体系的に解説
- 今回はココ 第2回 需要予測の手法・モデルを基礎から徹底解説!自社に最適な手法の選び方が分かる
- 第3回 AI・機械学習による需要予測|従来手法との違いと実務での活かし方
- 第4回 需要予測ツール・システムの種類や機能、選び方を実務視点で解説!
- 第5回 【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
はじめに:需要予測に「手法」を求める理由
ビジネスにおける需要予測の重要性と難しさ
現代のビジネス環境は、VUCA(変動性、不確実性、複雑性、曖昧性)の時代と言われて久しく、企業にとって「将来を見通す力」はかつてないほど重要性を増しています。「需要予測 手法」「需要予測 モデル」といった検索ワードで情報を探している方の多くは、在庫の適正化、生産計画の精度向上、あるいはキャッシュフローの改善といった切実な経営課題に直面していることでしょう。
誰もが、「来月の売上はいくらか?」「この新商品はどれだけ売れるか?」という問いに対して、魔法のように正解を導き出せるツールや手法を求めています。しかし、結論から申し上げますと、需要予測の世界において、あらゆる状況に対応できる「万能な手法(シルバーバレット)」は存在しません。ある企業で劇的な成果を上げた手法が、別の企業では全く役に立たないということも日常茶飯事です。

需要予測手法選びの失敗が招くリスク
手法の選定を誤ると、単に予測が外れるだけでなく、業務オペレーション全体に悪影響を及ぼす可能性があります。
例えば、季節変動が激しい商品に対して、直近の平均値だけを見る単純な手法を適用してしまえば、繁忙期の欠品による機会損失(チャンスロス)や、閑散期の過剰在庫による廃棄ロスを招きます。逆に、安定した定番商品に対して過度に複雑なAIモデルを導入すれば、システムコストが増大するばかりか、なぜその予測値が出たのかを誰も説明できず、現場の信頼を失う「ブラックボックス化」の問題を引き起こします。

本コラムの目的:ツールの奥にある「論理」を理解する
重要なのは、手法の名前(ARIMAモデル、指数平滑法など)を暗記することではなく、それらが「どのような考え方(ロジック)」に基づいて設計されているのか、そして「どのような業務・データ特性・ビジネスフェーズ」に向いているのかを深く理解したうえで選択することです。
本コラムでは、AIや機械学習といった高度な技術へ進む前の必須教養として、需要予測に用いられる代表的な統計・数理的手法の全体像と、その背後にある思想を徹底的に整理します。これを読み終える頃には、自社の課題に対してどの手法のアプローチが適切か、論理的に判断できる視座が得られるはずです。
需要予測における「手法」とは何か
手法とモデルの違い
需要予測の文脈では、「手法(Method)」「モデル(Model)」「アルゴリズム(Algorithm)」といった言葉が混在して使われがちで、これが初学者の混乱を招く原因となっています。これらは厳密には異なる階層の概念です。料理に例えて整理すると、以下のように理解しやすくなります。
手法(Method):料理のジャンルや方針(例:和食を作る、イタリアンを作る)。需要予測においては「時系列のパターンを見る」「要因との関係性を分析する」といった大きなアプローチの方向性を指します。
モデル(Model):具体的なレシピ(例:肉じゃがのレシピ)。手法という方針に基づき、数式や構造として具体化したものです。「過去の売上の平均をとる数式」「気温と売上の関係を表す方程式」などがこれに当たります。
アルゴリズム(Algorithm):調理の手順(例:野菜を切ってから肉を炒め、出汁を入れる手順)。モデルという数式を解き、具体的な予測値を計算するための計算手順やプログラムの仕組みを指します。
実務における「前提」の重要性
実務担当者にとって重要なのは、アルゴリズムの細かい計算プロセス(微分方程式の解き方など)を詳しく知ることよりも、そのモデルが「どのような前提で現実世界を捉えようとしているか」を理解することです。
例えば、「明日の売上は、今日の売上と似ているはずだ」という前提に立つのか、「売上は気温の変化に支配されているはずだ」という前提に立つのか。この前提がビジネスの実態とズレていれば、どんなに高度なアルゴリズムを使っても精度の高い予測はできません。技術用語の違いに惑わされず、その手法が持つ「世界観」を掴むことが第一歩です。
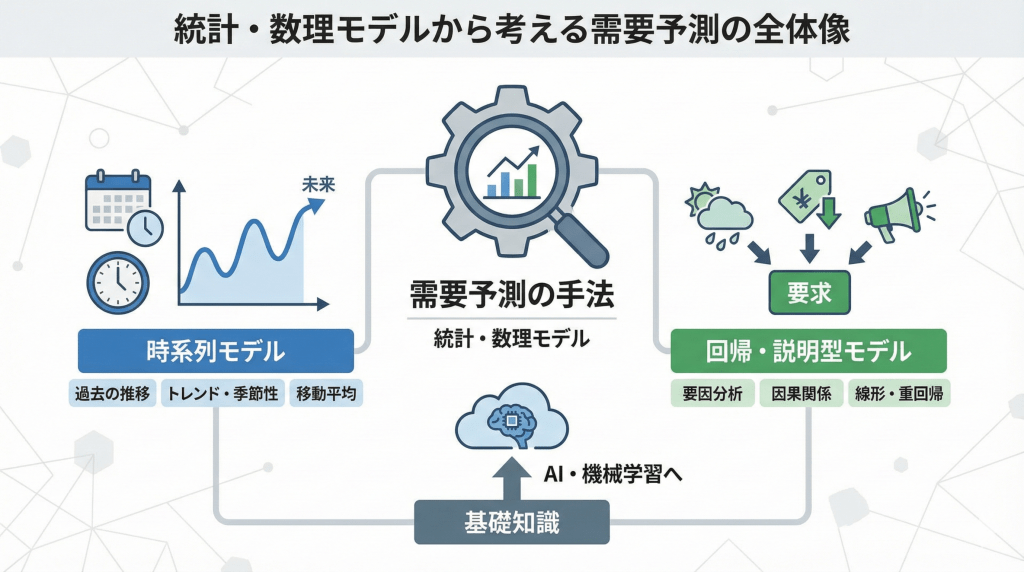
需要予測手法の分類軸
数ある需要予測の手法は、主に以下の軸で整理することができます。この軸を持っておくことで、新しい手法に出会った際もその位置付けを即座に理解できるようになります。
【データの見方による分類】
時系列型(Time Series):過去の売上推移そのもの(実績データ)のパターンを分析する。
回帰・説明型(Causal / Regression):売上に影響を与える要因(価格、天候、広告など)との因果関係を分析する。
【モデルの複雑性による分類】
単純統計モデル:移動平均など、電卓やExcelでも計算可能なシンプルなモデル。
高度数理モデル:ARIMAや状態空間モデルなど、統計的な仮定に基づく厳密なモデル。
機械学習・AI:ニューラルネットワークなど、非線形な関係や膨大な変数を扱えるモデル。
まずは、最も基礎的かつ実務での利用頻度が高い「時系列データに基づく手法」と「回帰・説明型モデル」について、その詳細を見ていきましょう。
時系列データに基づく需要予測手法
時系列モデルとは
時系列モデルとは、過去から現在までの需要の推移(時系列データ)そのものに着目し、その延長線上に将来を描こうとするアプローチです。「歴史は繰り返す」という考え方が根底にあります。
時系列データには、一般的に以下の4つの成分が含まれていると考えられています。これを「時系列の分解(Decomposition)」と呼びます。
トレンド(T: Trend):長期的な上昇や下降の傾向(例:企業の成長に伴う売上増、市場の縮小に伴う減少)。
季節性(S: Seasonality):1年、1週間、1日といった周期で繰り返される決まったパターン(例:夏のアイスクリーム需要、週末の来店客増)。
循環変動(C: Cycle):季節性よりも長い、景気循環などの波(数年単位の変動)。
不規則変動(I: Irregular / Noise):上記に当てはまらない、突発的で予測不可能なランダムな動き(ノイズ)。
時系列モデルの目的は、データの中からノイズを取り除き、トレンドや季節性といった「意味のあるパターン」を抽出して将来に当てはめることにあります。

移動平均・指数平滑法の考え方
これらは最も古典的でありながら、現在でも多くの企業の在庫管理システムや発注システムで稼働している、現役の実務的な手法です。
移動平均法(Moving Average)
直近の n期間のデータの平均値を、次の期間の予測値とする方法です。単純移動平均(SMA):過去3ヶ月の平均など、単純に数値を均して予測します。突発的なノイズ(たまたま売れた、売れなかった)の影響を薄める効果があります。
加重移動平均(WMA):直近のデータほど重要と考え、重み付けをして平均をとります。トレンドの変化に追随しやすくなります。
指数平滑法(Exponential Smoothing)
「新しいデータほど価値が高い」という考え方を突き詰め、過去のデータに対して指数関数的に重みを減少させていく手法です。特徴:計算式がシンプルでメモリを消費しないため、何万点ものSKU(Stock Keeping Unit)を管理する小売業や卸売業の発注計算などで広く利用されています。
用途:短期的な需要のブレをならし、「来週もだいたいこのくらいの水準だろう」と予測する用途、特に需要が比較的安定している定番商品の予測に向いています。

ARIMA系モデルの位置づけ
ARIMA(AutoRegressive Integrated Moving Average:自己回帰和分移動平均)モデルは、時系列分析の王道とも言える統計手法です。移動平均などが直感的なアプローチであるのに対し、ARIMAはデータの背後にある確率的な構造を数学的に捉えようとします。
AR(自己回帰):過去の値が現在の値に影響を与える(例:昨日売れたから今日も売れる)。
I(和分):トレンドを除去してデータを安定させる処理。
MA(移動平均):過去の予測誤差(予期せぬ変動)が現在に影響を与える。
これらを組み合わせることで、非常に精緻な予測が可能になります。しかし、実務での運用には注意が必要です。ARIMAモデルが威力を発揮するには、「データが統計的に安定していること(定常性)」や「長期的な構造変化(コロナ禍のような外部ショック)が少ないこと」といった条件が求められます。
理論的には優れていても、市場環境が激変する現代においては、調整やメンテナンスが難しく、実務でのハンドリング難易度が高いケースも少なくありません。「理論的な正しさ」と「実務での使いやすさ」は別物であることを理解しておく必要があります。

回帰・説明型モデルによる需要予測
回帰モデルとは何か
時系列モデルが「過去の売上」だけを見ていたのに対し、回帰モデルは「なぜ売れたのか?」「何が需要を決めているのか?」という要因(説明変数)に着目します。
これは Y = f(X) という数式で表されます。
Y(目的変数):予測したいもの(売上数量など)
X(説明変数):予測の手がかりとなる要因(価格、気温、広告費、店舗数など)
「価格を10円下げたら、売上は何個増えるか?」「気温が1度上がれば、ビールは何本多く売れるか?」といったビジネス上の問い(What-If分析)に答えることができるのが、回帰モデルの最大の特徴です。
線形回帰モデルの基本的な考え方
線形回帰(単回帰分析)は、一つの要因と需要の関係を直線(線形)で結びつける、最も基本的なモデルです。
※前提※「要因が増えれば需要も比例して増える(または減る)」という単純な関係を仮定します。
メリット
結果の解釈が非常に容易です。「広告費の係数がプラスであるため、広告を出せば売上が上がる」といった説明が誰にでも理解できるため、社内プレゼンや予算策定の根拠資料として非常に強力です。
デメリット
現実は必ずしも直線ではありません。「広告費を増やしすぎると効果が薄れる(飽和する)」といった複雑な現象を捉えきれない場合があります。
重回帰モデルと多変量需要予測
実際のビジネスにおいて、売上がたった一つの要因で決まることは稀です。価格、販促キャンペーン、季節、競合の動き、マクロ経済など、複数の要因が絡み合っています。これらを同時に考慮するのが「重回帰分析」です。
重回帰モデルの強み
・要因の特定どの要因が最も売上に貢献しているかを数値化(係数の大きさやt値による有意性判定)できます。「実はチラシの効果よりも、天候の影響の方が大きかった」といったインサイトを得ることができます。
・施策のシミュレーション
「来月は価格を維持しつつ、広告費を20%増やした場合の着地見込み」といったシナリオごとの予測が可能になります。これはマーケティング計画やキャンペーン設計において必須の機能です。
実務上の注意点:多重共線性(マルチコ)
重回帰モデルを扱う際によくある落とし穴が「多重共線性」です。これは、説明変数同士(例:店舗面積と従業員数)に強い相関がある場合、計算が不安定になり、正しい予測ができなくなる現象です。変数を入れれば入れるほど精度が上がるわけではなく、適切な変数選択(特徴量エンジニアリング)のスキルが求められます。

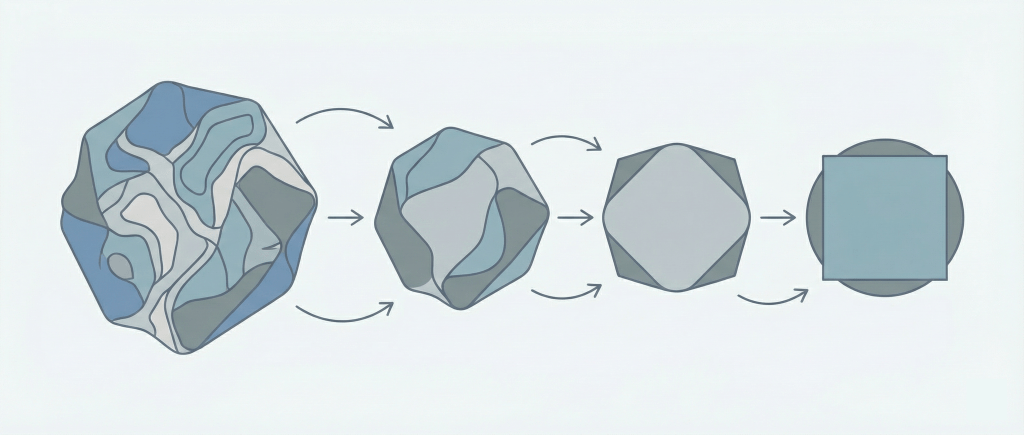
需要予測における数理モデルの考え方
数理モデルとは何か
ここで改めて、「数理モデル」というものの本質について触れておきましょう。数理モデルとは、複雑怪奇な現実世界を、人間が扱えるレベルまで単純化・抽象化した「地図」のようなものです。
現実の需要は、消費者の気まぐれ、SNSでの突発的なバズ、競合店の臨時休業、天変地異など、無限に近い要因によって形成されています。これら全てを計算式に組み込むことは不可能です。そこで数理モデルでは、以下のプロセスを経ます。
抽象化:重要度の低い要因を捨てる。
仮定:一定のルールを置く(例:「需要は正規分布に従う」とする)。
定式化:数式に落とし込む。
つまり、モデルによる予測値はあくまで「単純化された世界での正解」であり、現実そのものではないことを常に意識する必要があります。
モデルの仮定と制約
すべての数理モデルには、設計者が置いた「仮定」が存在します。
「需要の構造(トレンドや季節性)は、来年も急激には変わらないだろう」
「各要因はお互いに独立しており、影響し合わないだろう」
「誤差は平均0の範囲でランダムに発生するだろう」
予測が大きく外れる場合、計算ミスではなく、この「仮定」が現実と乖離してしまった(前提が崩れた)ことが原因である場合がほとんどです。例えば、新型コロナウイルスの流行初期において多くの需要予測モデルが機能不全に陥ったのは、過去データに基づく「構造が変わらない」という前提が根本から崩れたためです。「なぜ当たらないのか分からない」という事態を避けるためには、使用しているモデルがどんな仮定の上に成り立っているかを知る必要があります。
モデルの複雑さと汎化性能
「複雑で高度なモデルほど精度が良いはずだ」というのは、よくある誤解です。
過去のデータに対してモデルを合わせ込みすぎると、過去のデータの「ノイズ(偶然のブレ)」まで学習してしまい、肝心の将来予測の精度が落ちてしまうことがあります。これを**過学習(オーバーフィッティング)**と呼びます。
訓練データへの適合:過去データにどれだけ合っているか。
汎化性能(Generalization):未知のデータ(将来)に対してどれだけ通用するか。
実務では、過去データを完璧に説明できる複雑なモデルよりも、多少の誤差はあっても構造がシンプルで、将来の変化に対しても大外ししない(汎化性能が高い)モデルの方が、「運用に耐えうる優れたモデル」として評価されることが多いのです。これを「オッカムの剃刀(説明は単純である方がよい)」の原則とも関連付けて理解するとよいでしょう。
統計的需要予測の評価方法
なぜ予測精度を評価するのか
需要予測モデルは「作って終わり」ではありません。市場環境は常に変化するため、予測モデルも定期的に健康診断(精度のモニタリング)を行い、ズレが生じていればチューニングを行う必要があります。また、複数の手法(移動平均 vs 重回帰など)を比較し、自社にベストなものを選択するためにも、客観的な「ものさし」が必要です。
誤差指標の考え方(概要)
予測値と実績値の「ズレ」を測るための代表的な指標を紹介します。これらは学校のテストの点数とは異なり、数値が「小さいほど優秀」であることを意味します。
MAE(Mean Absolute Error:平均絶対誤差)
計算:予測と実績の差(絶対値)を単純に平均したもの。
特徴:直感的に理解しやすい。「平均して10個くらいのズレがある」と現場に説明しやすい指標です。
RMSE(Root Mean Squared Error:二乗平均平方根誤差)
計算:誤差を二乗して平均し、ルートをとったもの。
特徴:二乗するため、大きな外し方をすると数値が跳ね上がります。「大きく外すこと」を厳しくペナルティとして評価したい場合(例:欠品が許されない重要部品など)に適しています。
MAPE(Mean Absolute Percentage Error:平均絶対パーセント誤差)
計算:誤差を実績値で割り、パーセント表示にしたもの。
特徴:「平均して5%ズレている」といった形で、規模の異なる商品(1個100円の商品と1個10万円の商品)を横並びで比較・評価するのに便利です。ただし、実績値が0や極小の場合に計算できない・不安定になる弱点があります。
評価と業務目的の関係
ここで重要なのは、「数値上の精度が良い(誤差が小さい)」ことと、「ビジネスで使える」ことは必ずしもイコールではないという点です。例えば、
ケースA:誤差は小さいが、常に実績よりも「少なめ」に予測するモデル。
ケースB:誤差は少し大きいが、実績よりも「多め」に予測するモデル。
もしあなたの会社が「欠品はお客様への信頼を損なうため絶対に許されない」という方針であれば、数値上の精度が悪くても、安全側に倒してくれるケースBのモデルの方が「優秀」と判断されるかもしれません。逆に、「廃棄ロス削減」が至上命題ならケースAが選ばれます。
需要予測の評価は、数式上の正しさだけでなく、必ず「その予測を使ってどのような意思決定をするのか」「どちら側に外すリスクなら許容できるか」という業務目的とセットで設計する必要があります。
需要予測手法の選択で重要な視点
1. データ量・粒度・品質
需要予測において、「どの手法(アルゴリズム)を使うか」よりも圧倒的に重要なのが「どのようなデータがあるか」です。AIや統計モデルは、データという燃料で動くエンジンです。燃料がなければ、あるいは燃料が汚れていれば、F1カーのような高性能エンジン(高度な手法)も動きません。
■ データ量
発売直後の新商品など、過去データがほとんどない場合、高度な統計モデルは機能しません。この場合は、類似商品のデータを参照したり、定性的な判断(担当者の勘)をルール化する手法が現実的です。
■ 異常値・欠損
特売によるスパイク(突出した売上)や、在庫切れによる売上ゼロ期間などのデータ処理(クレンジング)が不十分な場合、複雑なモデルはノイズに過剰反応してしまいます。データが汚い場合は、頑健性のあるシンプルなモデル(移動平均など)の方が安全です。

2. 予測期間と業務用途
「いつの」「何を」予測したいのかによって、適切な手法は異なります。
■ 短期予測(翌日〜翌週)
日々の発注や配送計画に使います。直近のトレンドを重視するため、移動平均や指数平滑法、時系列モデルが適しています。即応性と安定性が求められます。
■ 中長期予測(半年〜翌年)
設備投資、予算策定、人員計画に使います。市場の成長性や経済指標との連動を見る必要があるため、回帰モデルやマクロ要因を考慮できるモデルが適しています。ここでは「なぜそうなるか」という説明性(Why)が重要になります。
3. 説明可能性と運用性
需要予測システムは、現場の担当者が日常的に使う道具です。
高度なAIが「来週は1000個売れる」と弾き出したとしても、その根拠がブラックボックスであれば、現場の店長は「そんなに売れるわけがない」と直感で修正してしまうでしょう。結果として、システムが使われなくなる失敗例は枚挙にいとまがありません。
■ 説明可能性(Explainability)
「気温が上がるから」「キャンペーンがあるから」と理由を説明できる回帰モデルや決定木系のモデルは、現場の納得感を得やすく、運用定着しやすいメリットがあります。
■ 運用コスト
モデルの再学習やメンテナンスに高度なデータサイエンティストが必要な手法は、属人化のリスクがあります。社内のリソースで維持管理できるかどうかも、重要な選定基準です。
AI・機械学習手法との関係
統計モデルとAIの違い
昨今話題のAI(機械学習・ディープラーニング)による需要予測と、本コラムで解説した統計モデルは、対立するものではありません。むしろ、相互補完的な関係にあります。
■ 統計モデル(Statistical Models)
データの「構造」を人間が理解・記述することに重点を置きます。データ数が少なくても機能しやすく、結果の解釈が容易です。「なぜ」を重視するアプローチです。
■ AI・機械学習(Machine Learning)
データから「パターン」を自動的に学習し、予測精度を極限まで高めることに重点を置きます。大量のデータと計算リソースが必要ですが、人間が気付かない非線形な関係性(複雑な相互作用)を見つけ出します。「当てに行く」ことを重視するアプローチです。
統計・数理がAI需要予測の基礎になる理由
これからAIによる需要予測に取り組む場合でも、統計・数理モデルの知識は不可欠です。なぜなら、AIが出した結果が妥当かどうかを判断したり、AIにどのようなデータを学習させるか(特徴量エンジニアリング)を考えたりする際には、統計学的な視点(分布、相関、定常性など)がベースとなるからです。
「基本の型」である統計モデルを知らずして、応用であるAIを使いこなすことはできません。

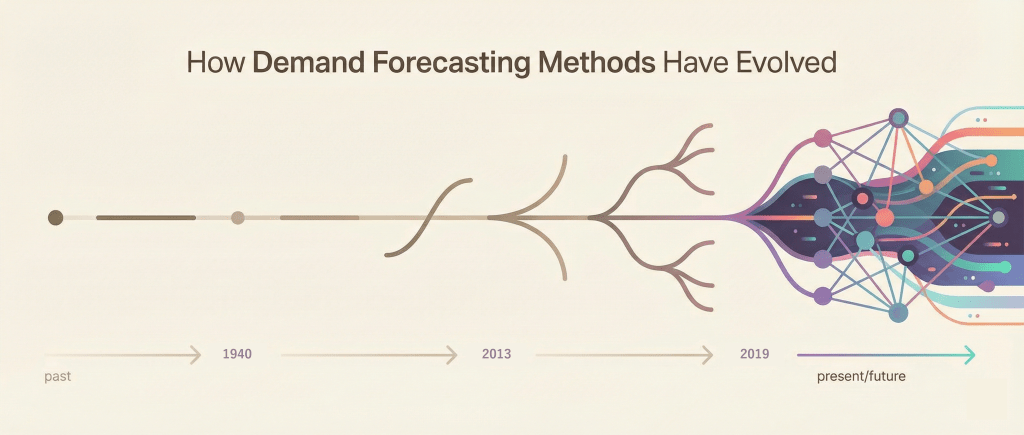
需要予測手法はどう進化してきたか
ルールベースから統計モデルへ
かつての需要予測は、熟練担当者の「勘・経験・度胸(KKD)」や、「昨対比105%で発注する」といった単純な社内ルール(ヒューリスティクス)が中心でした。これがコンピュータの普及とともに、客観的なデータに基づく統計モデル(移動平均、回帰分析)へと進化し、属人性の排除と業務の標準化が進められてきました。
複合モデル・アンサンブルの考え方
そして現在は、単一の「最強の手法」を探すのではなく、複数の手法を組み合わせるアプローチが主流になりつつあります。
これを「アンサンブル学習」や「ハイブリッドモデル」と呼びます。例えば、「ベースの需要は指数平滑法で予測し、キャンペーンによる跳ね上がり分は回帰モデルで予測して足し合わせる」といった方法や、AIと統計モデルの予測値の平均を取るといった方法です。
一つ一つの手法には弱点がありますが、それらを組み合わせることで、より頑健で精度の高い予測システムを構築しようという思想です。
まとめ:需要予測手法を知ることの本当の意味
手法選択は「経営の意思決定」そのもの
本コラムでは、需要予測の様々な手法とその背景にある考え方について解説してきました。
需要予測の手法を学ぶ目的は、単に「最新の流行りのモデルやツールを使うこと」ではありません。
自社のビジネスは、どのような要因で動いているのか?
どの程度のリスク(予測誤差)なら許容できるのか?
現場が納得して動けるロジックは何か?
これらを深く考察し、「自社の業務とデータの実態に合った適切な考え方(手法)を選び取る」ことこそが重要です。需要予測のモデル構築は、単なるデータ分析作業ではなく、データとビジネスの現場、そして経営の意思決定をつなぐクリエイティブな業務と言えるでしょう。
次のステップへ
統計・数理モデルの基礎を理解した今、次のステップとしては以下のテーマを掘り下げることをお勧めします。
AI・機械学習を活用した需要予測:統計モデルでは捉えきれない複雑なパターンをどう攻略するか。
業界・用途別の事例研究:小売行、飲食業、製造業など、業界特有の課題に対し、他社はどのようなモデルで挑んでいるか。
「予測は外れるものである」という前提に立ちつつ、それでもなお、論理とデータに基づいて未来の不確実性を少しでも減らそうとする姿勢こそが、激変するビジネス環境を生き抜くための最大の武器になります。
監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員CMO シニアコンサルタント 市川 史祥 |
|
|
一般社団法人LBMA Japan 理事 ロケーションプライバシーコンサルタント 流通経済大学客員講師/共栄大学客員講師 医療経営士/介護福祉経営士 Google AI Essentials/Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



