業界の最新動向をチェック
エリアマーケティングラボ
比較的少なめのデータで機械学習!交差検証とは?
2025/12/19
2025年12月19日号(Vol.201)
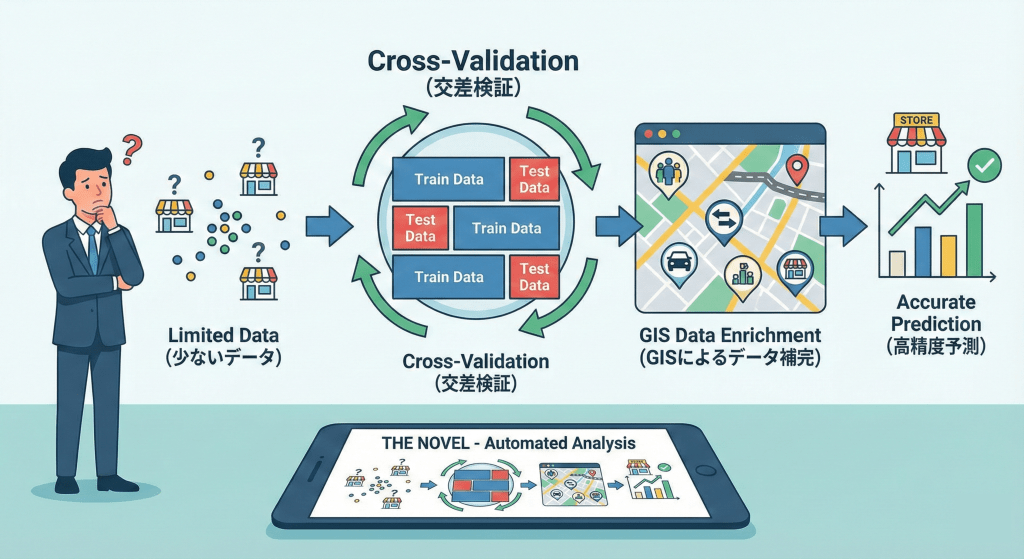
はじめに:データで経営する理想と「データが足りない」という現実
DXやデータドリブン経営が叫ばれる昨今、多くの企業がAIによる将来予測を競争力の源泉と捉えています。しかし、小売・流通・飲食業界の現場では、「AIを活用したいが、学習に必要な数万件ものビッグデータがない」という壁に直面し、導入を断念するケースが後を絶ちません。
本コラムは、数十〜百店舗程度の「スモールデータ」しか持たない店舗開発・マーケティング担当者様に向けて執筆しました。結論から申し上げますと、データが少なくてもAI活用は可能です。 限られたデータを最大限に活かす分析手法「交差検証」と、データの質を劇的に高める「GIS(地図情報システム)」を組み合わせることで、経験や勘に頼っていた出店判断を、科学的根拠のある高精度な予測へと変える方法を解説します。
交差検証とは| 「少ないデータ」で戦うための武器
データが少ない状況でも予測精度を高めるための手法が「交差検証」です 。これは少量のデータを「学習用」と「検証用」に分けて繰り返し使い回すことで、モデルの実力(汎化性能)を正しく評価し、実務に耐えうる予測モデルを構築する技術です。
さらに、技研商事インターナショナルが強みとするGISを組み合わせることで、データ量の不足を商圏データなど多様な外部情報で補完できます。人口や人流、競合状況といった地理情報をAIに取り込むことで、予測の精度と実用性は大きく向上します。
機械学習の基礎と「覚えすぎ(過学習)」の恐怖
予測モデルを作る基本の手順
交差検証の具体的な方法に入る前に、まず「機械学習がどのようにして予測モデルを作るのか」という基本の仕組みを共有しておく必要があります。
ビジネスにおける「予測」とは、過去のデータ(実績)から法則を見つけ出し、それを未来のデータ(まだ知らない案件)に当てはめる行為です。
例えば、新しいお店の売上予測であれば、以下のような手順を辿ります。
-
1. 勉強(学習)
すでにあるお店の「立地条件(駅からの距離、周りの人口、ライバル店の数など)」と「売上実績」のセットをAIに読み込ませます。AIは、「駅から歩いて5分以内で、周りの人口が3万人以上の時、売上は月1,000万円を超える傾向がある」といった複雑なルールや計算式(モデル)を自動的に作り上げます。
-
2. 推測(推論)
完成したモデルに、出店しようとしている場所の「立地条件」を入力します。
-
3. 予測
モデルが学習したルールに基づいて、候補地の「予測売上」を計算します。
この手順において、最も重要で難しいのが「モデルの評価」です。作ったモデルが本当に賢いのか、それとも単に過去のデータを丸暗記しただけなのかを見極める必要があります。ここで最大の敵となるのが「過学習(かがくしゅう=覚えすぎ)」です。
過学習:優等生の落とし穴
過学習とは、モデルが学習用のデータの特徴を過剰に学習しすぎてしまい、そのデータに対しては完璧な正解を出せるものの、少しでも傾向の違う新しいデータに対しては全く通用しなくなってしまう状態を指します。
直感的な例え:定期テストと入試問題
この現象を、学生の勉強に例えてみましょう。
•未知のデータ: これから受ける「入学試験(本番)」
•モデル(AI): 受験生
ある受験生(AI)は、過去の問題集(勉強用データ)を完璧に暗記しました。問題文の最初の5文字を見ただけで答えがわかるレベルです。この段階で、勉強用データに対する正解率は100%です。
しかし、いざ本番の入試(未知のデータ)を受けると、問題の出し方が少し変わっただけで手も足も出ず、赤点を取ってしまいました。彼は「過去問を解くこと」に特化しすぎて、「数学の本質的な解き方」を学んでいなかったのです。
ビジネスの現場でもこれと同じことが起こります。
「すでにあるお店のデータには完璧に当てはまる(誤差ほぼゼロ)予測式ができました!」と担当者が自信満々に持ってきたモデルが、いざ新しいお店を出してみると予測を大きく外し、数千万円の赤字店舗を作ってしまう。これが過学習の恐怖です。特にデータの数が少ない場合、AIは数少ない事例の「ノイズ(偶然の要素)」まで法則として覚え込んでしまいやすいため、過学習のリスクは極めて高くなります。
応用力(汎化性能)とは
ビジネスで必要なのは、過去の説明ではなく、「まだ見ぬ未来のデータを正しく予測する能力」です。これを専門用語で「汎化性能(はんかせいのう=応用力)」と呼びます。
•学習性能: 学習用データに対する当てはまりの良さ
•応用力(汎化性能): 未知のデータに対する予測の正確さ
AI開発のゴールは、学習性能を高めることではなく、この応用力を最大にすることにあります。そして、この応用力を正しく測るために欠かせない手続きが、データを「学習用」と「評価用」に分けて検証することなのです。

これまでの検証方法とその限界
取り置き法(ホールドアウト法)の仕組み
応用力を測るための最もシンプルで昔からある方法が「取り置き法(ホールドアウト法)」です。
この方法では、手持ちの全データを一定の割合で2つ(あるいは3つ)に分けます。
•学習用データ: モデルを作る(学習させる)ために使う。全体の70%〜80%程度
•評価用データ: 作ったモデルの正確さを確認するために使う。全体の20%〜30%程度
手順:
1. 全部で100店舗のデータがあるとする
2. ランダムに70店舗を「学習用」、30店舗を「評価用」に分ける
3. 学習用70店舗のデータだけを使ってモデルを作る
4. 完成したモデルに、評価用30店舗の条件を入力し、売上を予測させる
5. 予測値と実際の売上(正解)を比較し、ズレ(精度)を計算する
この際、評価用データはモデルにとって「未知のデータ(初めて見る問題)」として扱われるため、ここでの成績が良ければ「応用力がある」と判断します。
少ないデータにおける取り置き法の致命的な弱点
取り置き法は、データが十分に多い場合(数万件以上など)は非常に有効で効率的な方法です。しかし、日本の店舗ビジネスのような「少ないデータ(数十〜数百件)」の環境下では、以下の2つの致命的な問題が発生します。

問題1:データの「無駄遣い」
100店舗しかない貴重なデータのうち、30店舗分を評価のためだけに「取り置く」ことになります。つまり、AIは残りの70店舗分の情報しか学習できません。
データの世界では「情報の量=賢さ」です。学習用データが3割も減れば、モデルの性能は確実に下がります。データが少ない環境では、1件のデータも無駄にできないのです。
問題2:分けることによる「偏り(バイアス)」のリスク
データの数が少ないと、分け方の運・不運が結果を大きく左右します。
例えば、たまたま評価用に選ばれた30店舗が「予測しやすい、標準的な店舗」ばかりだった場合、モデルの評価は実力以上に高くなります(過大評価)。逆に、「特殊な事情(改装中、天災の影響など)がある店舗」ばかりが評価用に含まれてしまうと、評価は不当に低くなります(過小評価)。
「もう一度ランダムに分け直して検証したら、正確さが全然違った」という現象が起きやすく、これでは経営陣に対して「このモデルの的中率は80%です」と胸を張って報告することができません。
この「データの少なさ」と「評価の不安定さ」を同時に解決するのが、本コラムの本題である「交差検証」です。
交差検証:データを使い倒す技術
交差検証の基本の仕組み
交差検証とは、データを何回かにわたって分け、役割を交代させながら検証を繰り返す方法です。最も代表的な「K分割交差検証」を例に、その仕組みを詳しく解説します。
K分割交差検証(例:5つに分ける場合)
手持ちの100店舗のデータを、5つのグループに等しく分けます。各グループには20店舗ずつが入ります。
-
1回戦:
グループA(20店舗)を「評価用」にする。
残りのグループB, C, D, E(計80店舗)を「学習用」にしてモデルを作る。
グループAで正確さを評価する(スコア1)。
-
2回戦:
今度はグループBを「評価用」にする。
グループA, C, D, Eを「学習用」にする。
グループBで正確さを評価する(スコア2)。
-
3〜5回戦:
同様に、C、D、Eを順に評価用として回していく。
この5つのスコアの平均値を、そのモデルの最終的な性能評価とします。

交差検証がビジネスにもたらす3つのメリット
メリット1:全データを評価に使える(信頼性の向上)
取り置き法では、一部のデータしかテストされませんでした。交差検証では、最終的にすべてのデータが必ず1回は評価用として評価されます。
「特定のデータだけが評価されたから、たまたま良い結果が出た」というまぐれ当たりを排除し、モデルの実力を公平かつ漏れなく測ることができます。
メリット2:学習用データを最大化できる(正確さの向上)
5つに分ける場合、各ラウンドで全データの80%(4/5)を学習に使用できます。
10個に分ければ90%です。取り置き法(例えば70%学習)に比べて、より多くのデータを学習に回せるため、モデル自体の性能アップが期待できます。
データが少ない環境では、この数パーセントの差が決定的な意味を持ちます。
メリット3:結果の「安定性」を確認できる
5回のテスト結果のバラつきを見ることで、モデルの安定性を診断できます。例えば、5回の正確さが「80%, 81%, 79%, 80%, 82%」であれば、このモデルは安定しています。
しかし、「95%, 60%, 85%, 55%, 90%」のようにバラバラであれば、データの選び方によって結果が変わる「不安定なモデル」であることがわかります。平均値は同じ80%でも、ビジネスで採用すべきは前者です。交差検証は、この「リスクの見える化」を可能にします。
少ないデータの切り札「一個抜き交差検証 (Leave-One-Out)」
データの数が極端に少ない場合(例えば全店舗数が30店舗以下など)、5分割ですらデータを十分に学習できないことがあります。この場合に用いられる究極の方法が「一個抜き交差検証」です。
• 仕組み: データの数と同じ回数だけ検証を繰り返す。
• 手順: 30店舗ある場合、
1. 1店舗だけを評価用に抜く。
2. 残りの29店舗すべてで学習する。
3. 抜いた1店舗で評価する。
4. これを30店舗すべてに対して30回繰り返す。
計算回数は膨大になりますが、常に「全データ引く1個」という最大限のデータ量で学習できるため、極めてデータが少ない場合においては最も偏りの少ない評価が可能になります。地域分析の初期段階や、高額商品を扱う法人営業の受注予測など、サンプル数がどうしても稼げない領域では、この方法が標準的に用いられます。

比較まとめ:取り置き法 vs 交差検証
|
特徴 |
ホールドアウト法 |
K分割交差検証 |
Leave-One-Out |
|
学習データの量 |
少ない (例: 70%) |
多い (例: 80-90%) |
最大 (N-1個) |
|
計算コスト |
低い (1回計算) |
中 (K回計算) |
高 (N回計算) |
|
評価の信頼性 |
低い (分割による運が絡む) |
高い (平均化される) |
非常に高い |
|
適したデータ数 |
ビッグデータ (>1万件) |
中〜小データ |
極小データ (<50件) |
|
ビジネス用途 |
リアルタイム分析、大規模Webログ |
店舗売上予測、需要予測 |
希少疾患分析、初期出店分析 |
地図情報システム(GIS)による「データの質」の向上
向上し、偏りの少ない評価が可能になります。また、過学習を抑制し、未知のデータに対する予測精度を高めることが期待できます。k分割交差検証は、データが少ない場合でも、モデルの性能を最大限に評価し、改善するための強力なツールとなります。

「データが少ない」とはどういうことか。
ここまで「データの数(行の数=店舗の数)」の話をしてきましたが、機械学習にはもう一つ重要な「データの項目数(列の数、特徴の数)」という考え方があります。
• データの数: 店舗の数(例:50店舗)
• 特徴の数: 売上を説明する要因(例:店舗面積、席数、駅からの距離...)
データの数が50件しかなくても、特徴が十分に多く、かつ売上と強い関係があれば、AIは正確な予測モデルを作ることができます。しかし、多くの企業の社内データは以下のような貧弱な状態に留まっています。
• 店舗ID
• 住所
• 売上
• 店舗面積
• 駅からの距離
これだけでは、「なぜA店は売れて、B店は売れないのか」の理由をAIが深く理解することは不可能です。消費者の行動はもっと複雑で、多様な要因(年収、生活スタイル、競合、天候、人の流れなど)が絡み合っているからです。
地図情報システム:外部データの宝庫
ここで、私たち技研商事インターナショナルの強みである「地域分析データ」が決定的な役割を果たします。地図情報システムを使うことで、単なる「住所」情報をカギにして、その地点周辺の膨大な環境データを紐付ける(豊かにする)ことができます。
地図情報システムによって付け加えられるデータの一例を挙げます。
• 国勢調査・住民基本台帳: 人口、性別、年齢構成、家族の人数
→ 「一人暮らしが多いエリアか、家族層か?」
• 年収・消費支出データ: 年収別の世帯数、貯金額、支出額
→ 「高級品が売れる地域か、安さが重視されるか?」
• 施設データ: ライバル店の数、スーパー・コンビニの有無、集客施設
→ 「競合との食い合いや相乗効果は?」
• 人流データ (GPS): 時間帯ごとの滞在人口、来訪者の住まい、通行量
→ 「実際に人が動いている場所か? 昼と夜の違いは?」
• 地形・道路: 道路の幅、交通量、昼と夜の人口比率
→ 「車での行きやすさは? お店の見つけやすさは?」
これらを付け加えることで、元々は5項目しかなかった社内データが、数百、数千項目の「リッチなデータ」へと生まれ変わります。
AIにとっては、学習するためのヒントが爆発的に増えることを意味します。「データの数が少ない」という弱点を、「特徴の圧倒的な多さ」でカバーし、予測精度を底上げする。これが地図情報システムと機械学習の勝利の方程式です。

特徴選びと交差検証の相乗効果
ただし、特徴は多ければ多いほど良いわけではありません。無関係なデータ(ノイズ)まで混ぜると、逆に精度が落ちる「次元の呪い」という現象が起きます。
ここで再び交差検証が活躍します。
「どのデータ(特徴)を使うのがベストか?」を選ぶ際、様々な特徴の組み合わせでモデルを作り、交差検証で評価を繰り返します。
-
「年収データを入れたら、交差検証のスコアが上がった」→採用
-
「天候データを入れたが、スコアが変わらなかった」→不採用
このように、交差検証を羅針盤として地図情報データの大海原を探索することで、自社の売上にとって本当に重要な「真の成功要因」を科学的に特定することが可能になります。
専門家不要のデータ分析 「THE NOVEL」
現場が抱える「実行の壁」
交差検証とGISの有効性は明らかですが、実務での実行には「プログラミングスキル」「データの紐付け」「データサイエンティストの採用」という高い壁が存在します。
多くの企業が、「理論はわかったが、ウチには無理だ」と諦めてしまうのが現状です。この課題を技術の力で解決し、高度な分析を誰でも使えるようにするために開発されたのが、技研商事インターナショナルの新サービス「THE NOVEL(ザ・ノベル)」です。
THE NOVELの概要と革新性
「THE NOVEL」は、株式会社データインサイトとの共同開発による、次世代のクラウド型地域分析プラットフォームです。2026年春(予定)のリリースを目指し、現在開発が進められています。
そのコンセプトは、「誰でも使える高度なAI」と「説明可能な予測」です。

機能1:自動化された売上予測モデル作成
THE NOVELの核となるのが、最新の自動機械学習エンジンです。ユーザーが行うのは、自社の店舗データ(売上と位置情報)をアップロードすることだけ。あとはシステムがほぼ自動で処理を行います。
• 自動データ連携:地図情報データベースから最適な商圏データを自動で付け加えます。
• 自動モデル選択: 統計解析系の重回帰と機械学習系のLightGBMの両方のモデルを自動作成します。
• 交差検証: 本コラムの本題である「交差検証」も実施できる予定です。
機能2:統計モデルと機械学習の「デュアルアプローチ」
THE NOVELのユニークな点は、精度の高い「機械学習モデル」と、因果関係がわかりやすい「統計モデル(重回帰)」を同時に作り、比較して見せる機能です。
• 機械学習: 「なぜかは複雑だが、とにかく当たる」。出店のリスク判定や売上数値の予測に使います。
• 統計解析: 「人通りの多さが売上の30%を決めている」 。売上要因の特定や、改善策の立案に使います。
この2つを併用することで、現場の店長への説明(統計モデル)と、経営層への投資判断(機械学習モデル)の両方に対応できます。
機能3:AIモデルを“説明可能”にするインサイト機能
「AIがこう言っています」だけでは、数千万円、億単位の投資決裁は下りません。
THE NOVELは、予測結果の根拠を言葉にして提示します。結果を色々なリテラシーをもつ社内の色々な人に共有できるようなモデル説明レポートも自動的に作成します。
おわりに
機械学習と交差検証は、もはや一部のIT企業だけの専売特許ではありません。それは、先が見えない時代を生き抜くすべてのビジネスマンにとっての必須教養であり、武器です。
2026年春、地域分析の世界は大きく変わります。勘と経験の時代を終わらせ、データと論理に基づいた、再現性のある成長戦略を描く。技研商事インターナショナルは、その最前線で皆様のビジネスを支援してまいります。
監修者プロフィール市川 史祥技研商事インターナショナル株式会社 執行役員 マーケティング部 部長 シニアコンサルタント |
|
| 医療経営士/介護福祉経営士 流通経済大学客員講師/共栄大学客員講師 一般社団法人LBMA Japan 理事 Google AI Essentials Google Prompt Essentials 1972年東京生まれ。早稲田大学政治経済学部卒業。不動産業、出版社を経て2002年より技研商事インターナショナルに所属。 小売・飲食・メーカー・サービス業などのクライアントへGIS(地図情報システム)の運用支援・エリアマーケティング支援を行っている。わかりやすいセミナーが定評。年間講演実績90回以上。 |
 |
電話によるお問い合わせ先:03-5362-3955(受付時間/9:30~18:00 ※土日祝祭日を除く)
Webによるお問い合わせ先:https://www.giken.co.jp/contact/
人気のコラム
カテゴリー名
商勢圏(しょうせいけん)とは?店舗の枠を超えた「広域エリア支配」の考え方
- サービス
- MarketAnalyzer® 5
- 出店計画
- 店舗マーケティング
- 基礎知識
- 競合分析
2026/00/00
カテゴリー名
関係人口とは?その分析例と創出の戦略
- ニーズ
- MarketAnalyzer® Satellite
- 活用事例
- お役立ち情報
- インバウンド
- イベント分析
2026/00/00
カテゴリー名
【業界別】需要予測の実務事例|小売・飲食・製造で何が違うのか
- サービス・ニーズ
- KDDI Location Analyzer
- ジオターゲティング広告
- 屋外広告
- 商圏分析
- オルタナティブデータ
2026/00/00



