
商圏分析 用語集
ナショナルチェーン(全国チェーン)
ナショナルチェーン(全国チェーン)とは、全国的規模で複数の地域に展開している飲食・小売企業のこと。店舗を戦略的に開発し、ドミナント化出店しているチェーン店のことです。
大手カフェチェーンの出店立地の居住特性
大手カフェチェーンの出店傾向をエリアマーケティング用GIS(地図情報システム)マーケットアナライザー(MarketAnalyzer™)を用いて分析してみます。各カフェチェーンの商圏特性を俯瞰し、カフェはどういう立地に出店しているのか、各チェーン毎に違いがあるのかを考察してみます。
1.競合店舗のデータベース
競合を分析するためによく使われるデータベースは、電話帳データです。業種分類毎に利用できるため、古くから活用されています。
今回は、全国チェーン店ポイントデータと言うデータベースを用いました。小売チェーンや飲食チェーンの店舗は出退店のペースが早いですが、このデータは数日周期でメンテナンスされており、より最新の出店状態を把握することができます。
指定できるカテゴリーは図1の通りですが、今回はこの中からカフェカテゴリーのデータ、全国4591店舗を利用しました。
座標データも付いているため、そのままGIS(地図情報システム)にインポートすることができます。
店舗リストを地図上にプロットすることは技術的に難しいことではありませんが、肝心なのはここからです。弊社のGIS「MarketAnalyzer™」では、地図にプロットした複数の店舗に対して商圏範囲を設定し、商圏データを一括で集計、付与することができます。
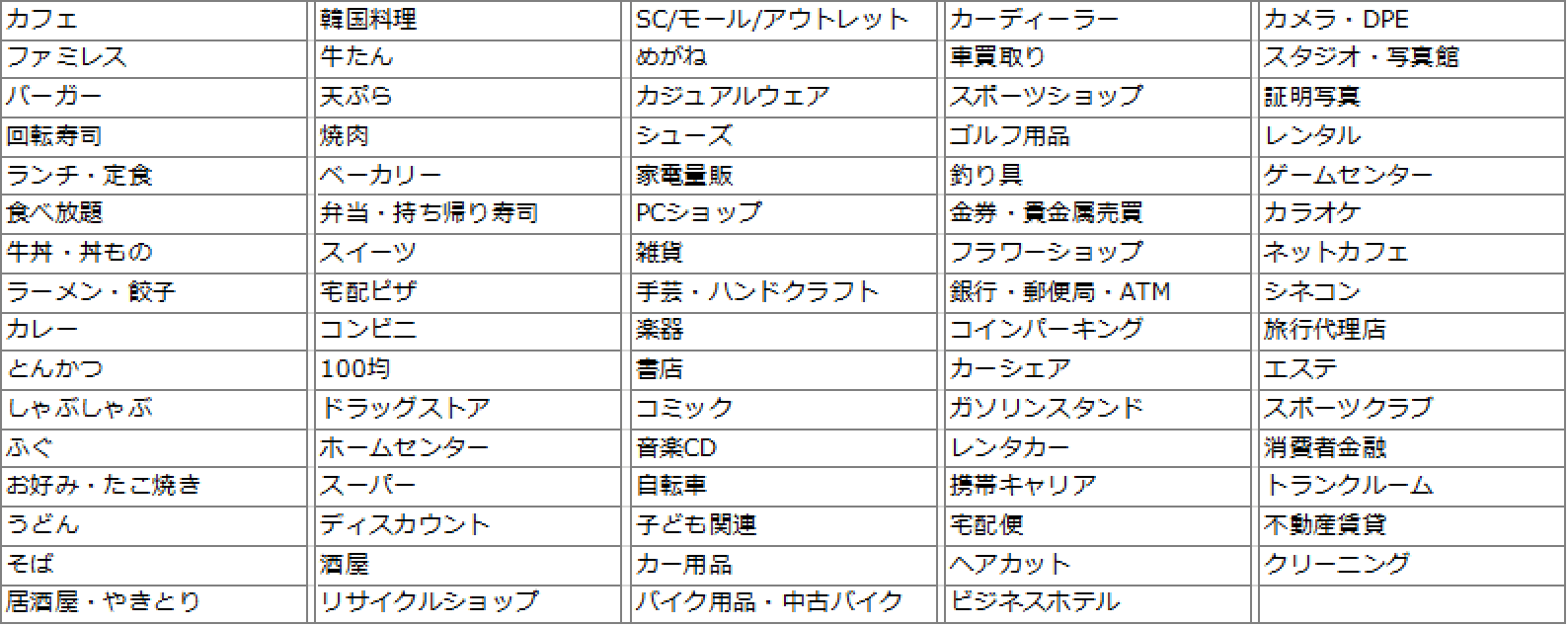
【図1:全国チェーン店ポイントデータの業態カテゴリ 】
2.3つの人口
まずは各チェーン店の商圏特性を分析します。カフェチェーンのターゲットは地域に居住している人々だけではなく、働いている人、買い物をしている人と様々ですので、まずは全体的な傾向を見ていきましょう。
地図にプロットした店舗を中心に、半径300m圏内の「3つの人口」を集計しました。「3つの人口」とはエリアマーケティングの基本的分析指標で、夜間人口・昼間人口・商業人口を指します。夜間人口は居住特性、昼間人口はビジネス特性、商業人口は繁華街特性を分析するイメージです。図2はカフェチェーン毎の3つの人口の平均値です。プロントはビジネス・繁華街立地を表す昼間人口・商業人口が突出しています。バータイムを展開していることからイメージ通りというところでしょうか。対して珈琲館は、どちらかというと居住地ベースの立地も意識しているのではないでしょうか?
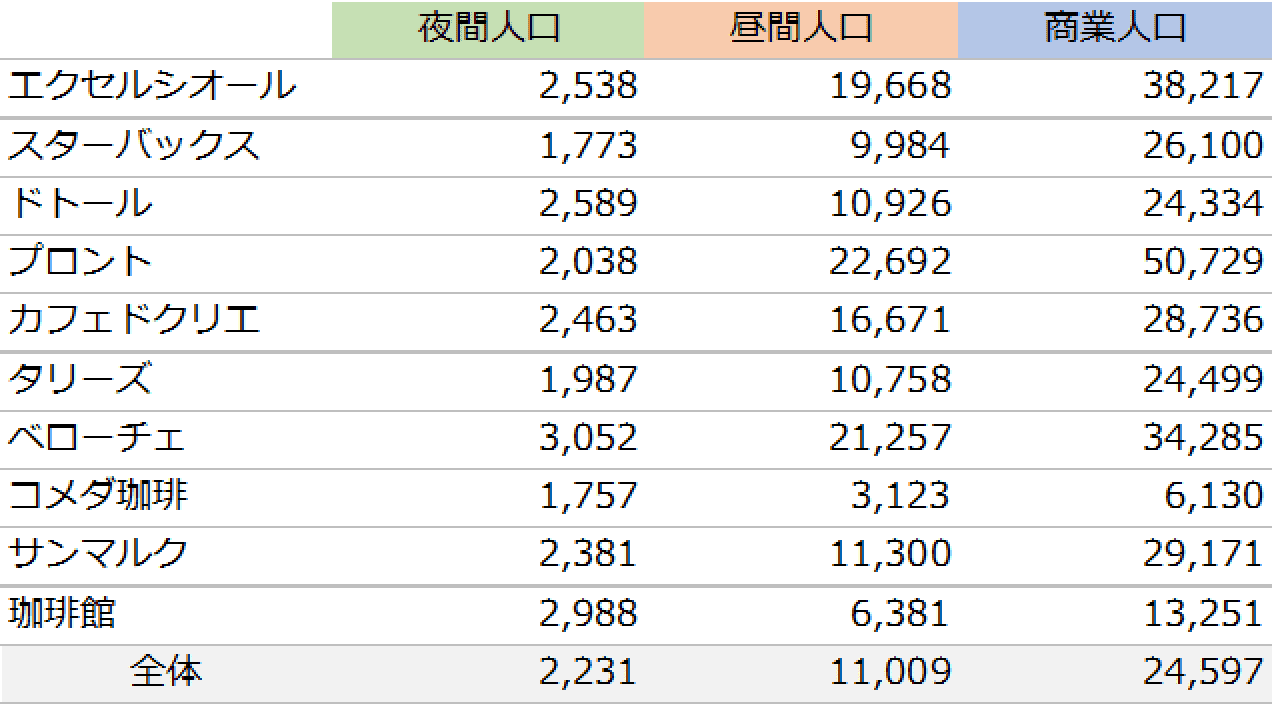
【図2:半径0.3km商圏の3つの人口の平均値 】
3.居住特性を知るデータベース
ここからは各チェーンの居住地ベースの出店傾向を見ていきます。居住特性を分析するデータは先の夜間人口だけではありません。年齢、家族構成、住宅、職業など様々です。商圏分析で重要なのはデータをいかに読み解くかですが、単一の指標を見ても何の知見も得られないと思います。複数の指標を複眼的に見てはじめて商圏特性を把握することができます。しかしながら複数の指標を同時に読み解くのは困難です。そこで商圏の質を読み解く「居住者プロファイリングデータ」を用いました。
■居住者プロファイリングデータとは?
カフェチェーンの出店立地の居住特性を分析する前に、居住者プロファイリングデータがどのように開発されたかを説明します。大きく分けると、①データの縮約・因子スコア化、②クラスター分析という2つのステップによって開発されています。
全国の人口や世帯数など約300項目が町丁目単位でセットされているのが国勢調査データです。その中から年齢、世帯構成、住宅、職業を表す60項目をピックアップし、主成分分析によって有意な9つの因子に縮約します。60項目の元データを比較しても判別しにくいため、人間が解釈できるようにデータ項目を少なくするというわけです。わかりやすく言えば、砂糖と酒とみりんという3軸を甘いという1軸に、とうがらしと胡椒と山椒は辛いという1軸にまとめるというような具合です。
データのレイアウトイメージは図3のとおりです。全国の町丁目単位で9つの因子スコアがセットされています。スコアはゼロが真ん中の偏差値で、Zスコアと言います。各因子は当社で解釈しており、因子1のスコアが高ければニューファミリー性が高いというように解釈します。各解釈については本コラムでは割愛します。
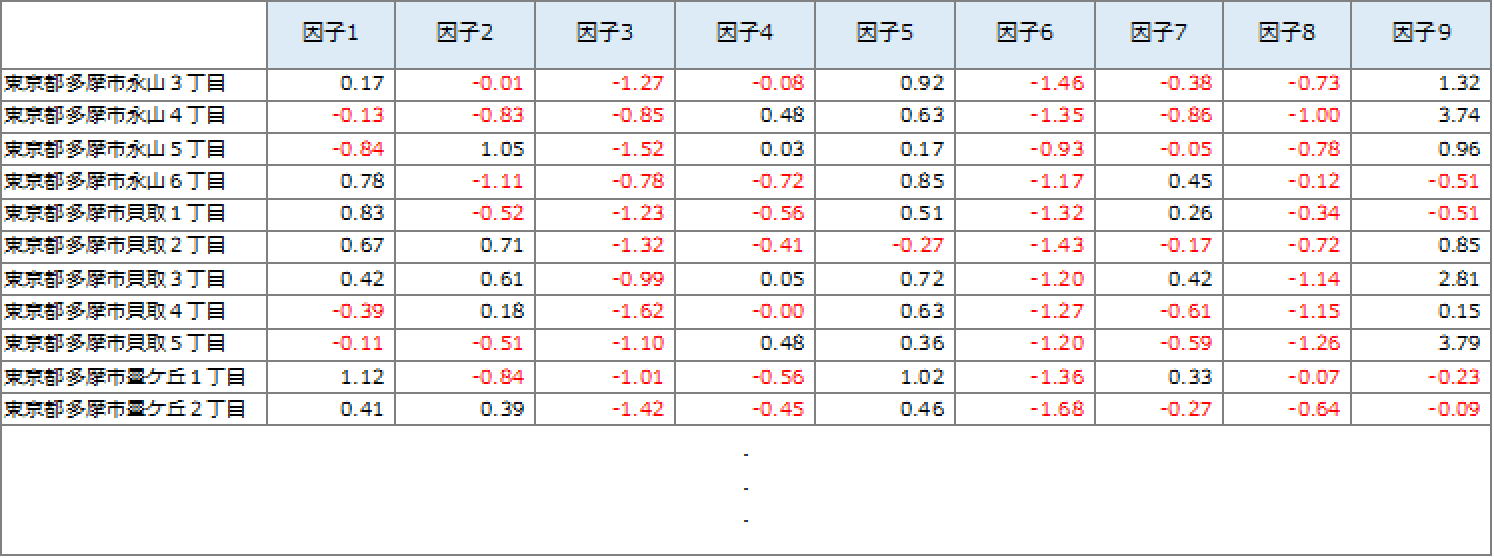
【図3:町丁目単位の9つの因子スコア 】
さらに町丁目単位で縮約された9つの因子スコアを用いて、クラスター分析を行い30分類します。クラスター分析とはデータをグルーピングする統計解析手法です。9つの因子スコアの波形パターンが似ている町丁目は同じグループとするやり方です。最終的に町丁目単位に9つの因子スコアとグループ番号(グループをクラスター=CLと呼びます。)がセットされます。図4はクラスター番号別に地図を色塗りしたものです。
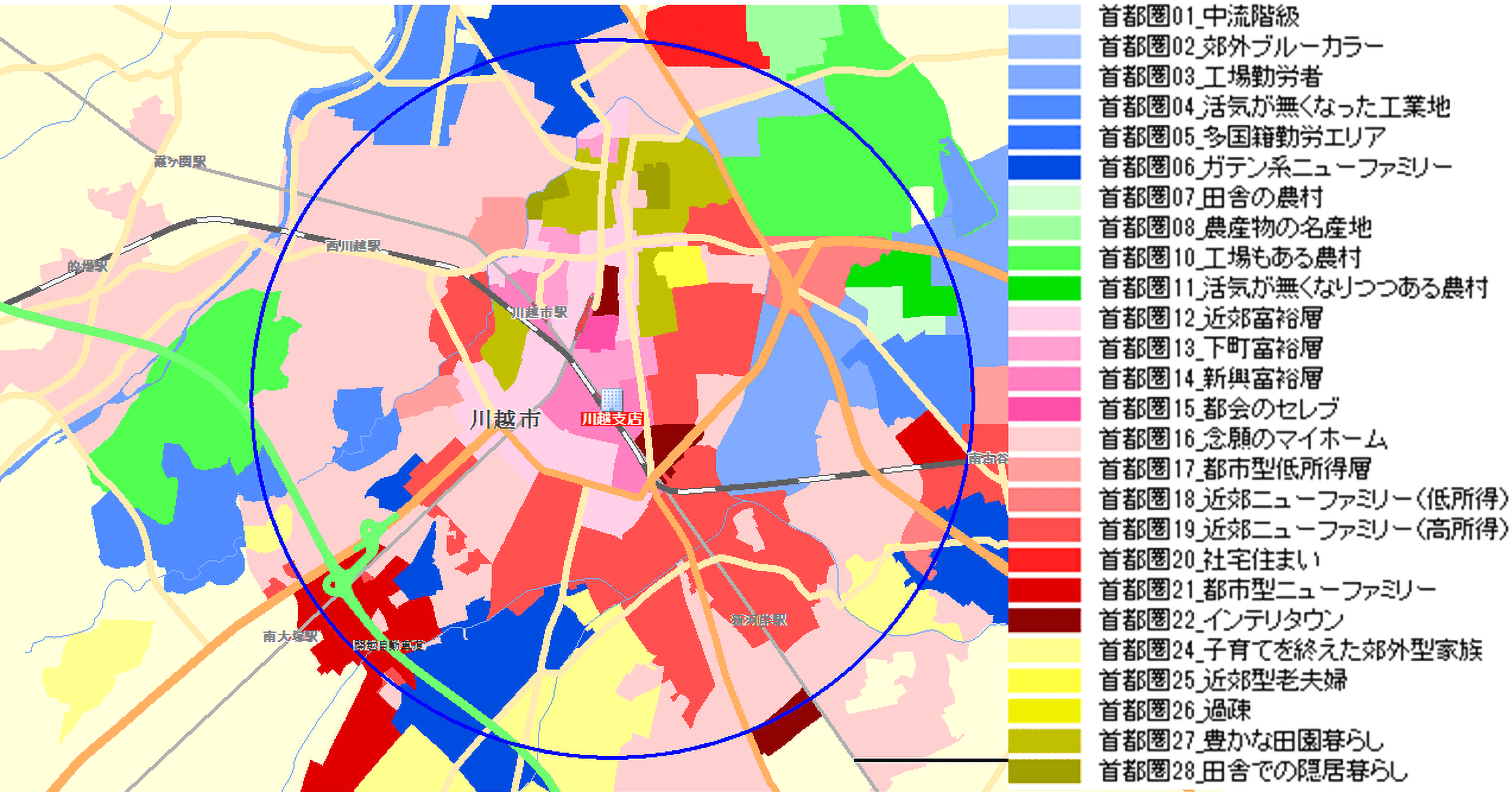
【図4:川越駅周辺のクラスター分布 】
4.居住特性と出店傾向
各カフェチェーンの属性に、店舗が位置する町丁目のクラスター番号を付与します(図5)。MarketAnalyzer™であれば一括処理が可能です。
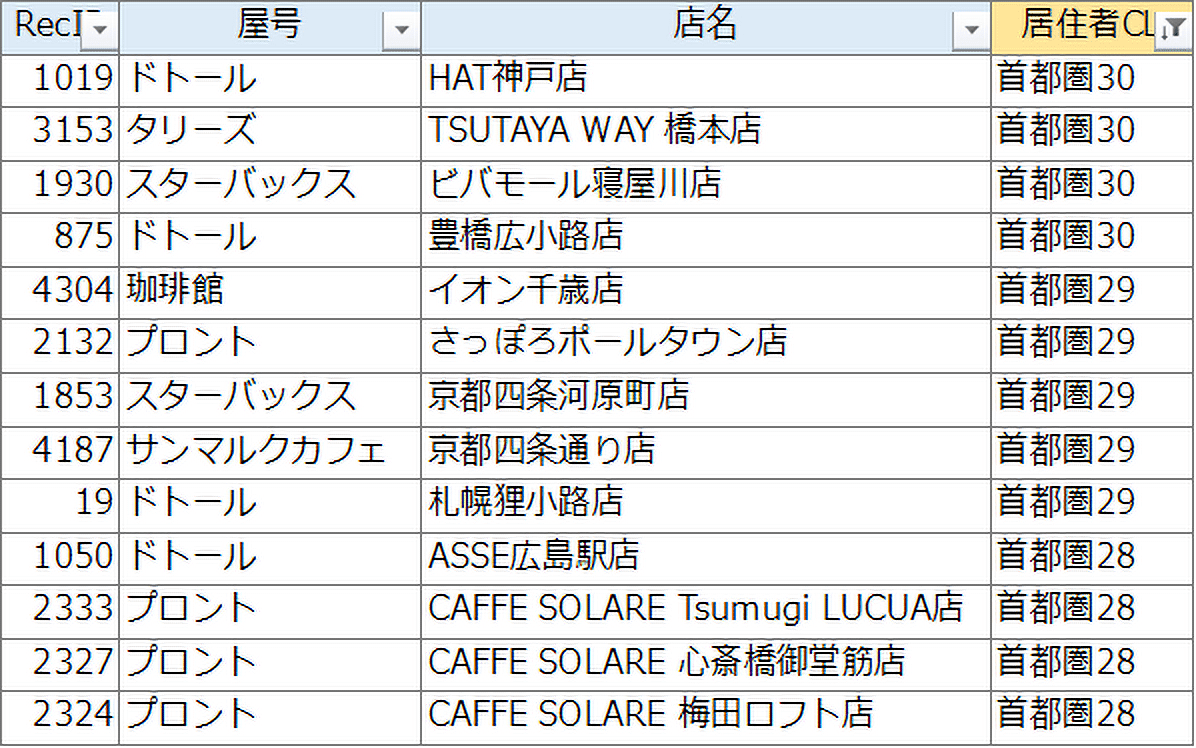
【図5:店舗ごとにクラスター番号を付与 】
クラスター番号単位で集計したものが図6のグラフです。横軸は1~30のクラスター番号、縦軸はカフェチェーン全体の店舗数を表します。一番出店が多い居住特性は15番の「都会のセレブ」、一番少ないのは山奥のブルーカラーということがわかります。
各クラスターの詳細は、居住者プロファイリングデータハンドブックでご確認いただけます。
年齢構成、世帯構成、年収、貯蓄、住宅という軸でクラスターを説明しています(図7)。
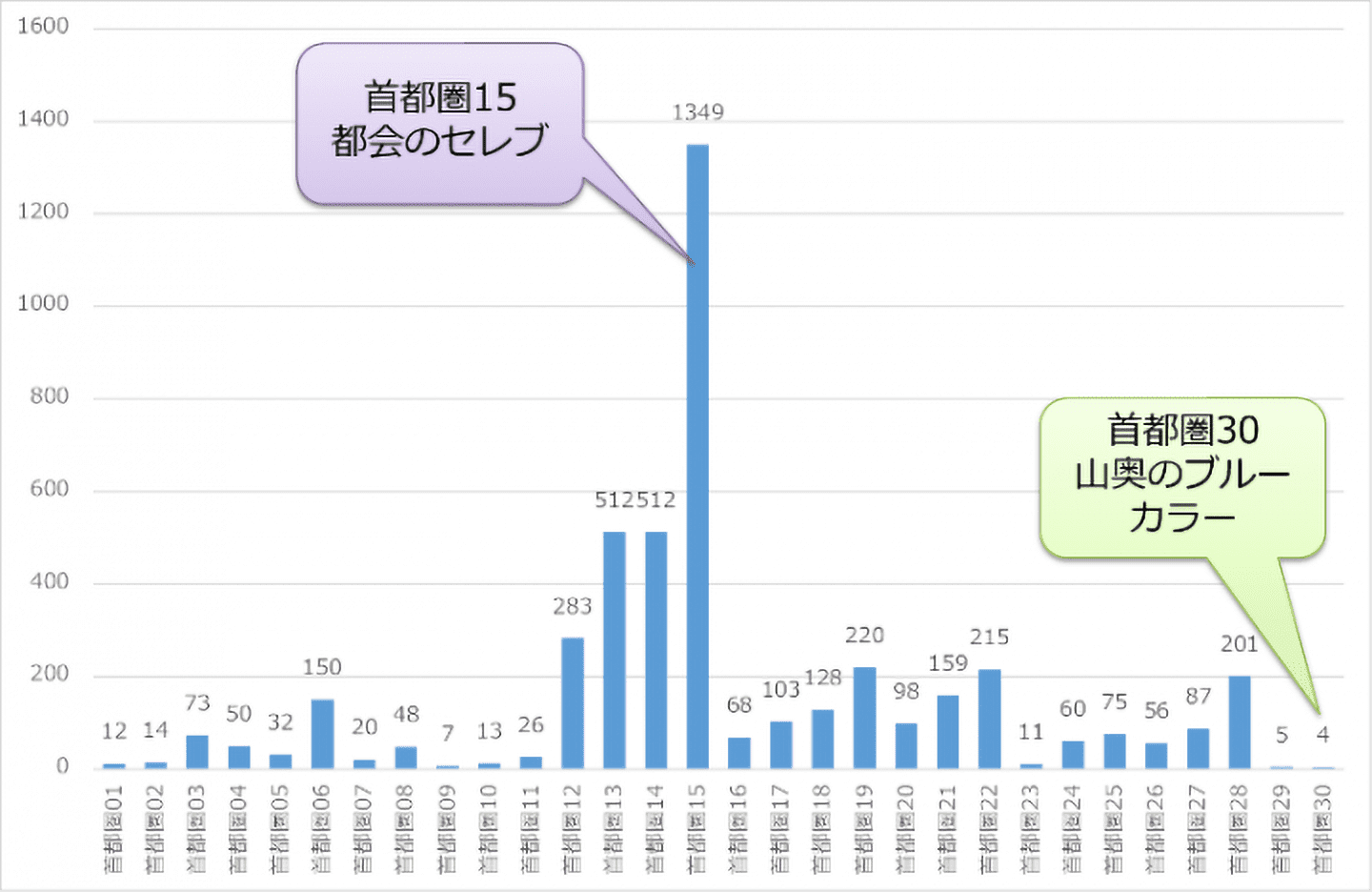
【図6:クラスター毎の出店数 】
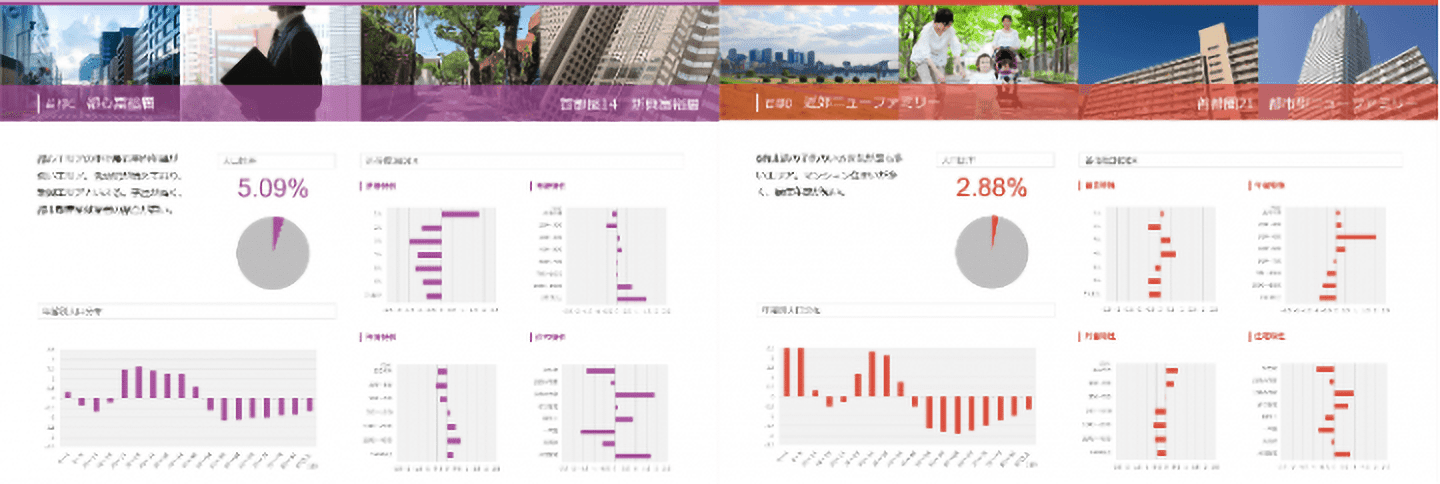
【図7:居住者プロファイリングハンドブック(一部) 】
「都会のセレブ」は人口総数の3.99%を占め、年齢は20代~30代前半に集中しています。子どもと高齢者の比率が低く、若者単身世帯が世帯構成の多くを占めます。富裕度が高く、マンション住まいが多い特徴のあるエリアです。一方、「山奥のブルーカラー」は人口総数の1.04%を占め、圧倒的に高齢者の比率が高く、2人世帯数が突出しています。富裕度は高くなく持家一戸建ての多いエリアです。
■チェーン毎の出店傾向を比較
全体傾向の次は、各チェーン毎に出店傾向を見ていきましょう。図8はコメダ珈琲とスターバックスを居住特性毎の店舗数で比較したものです。
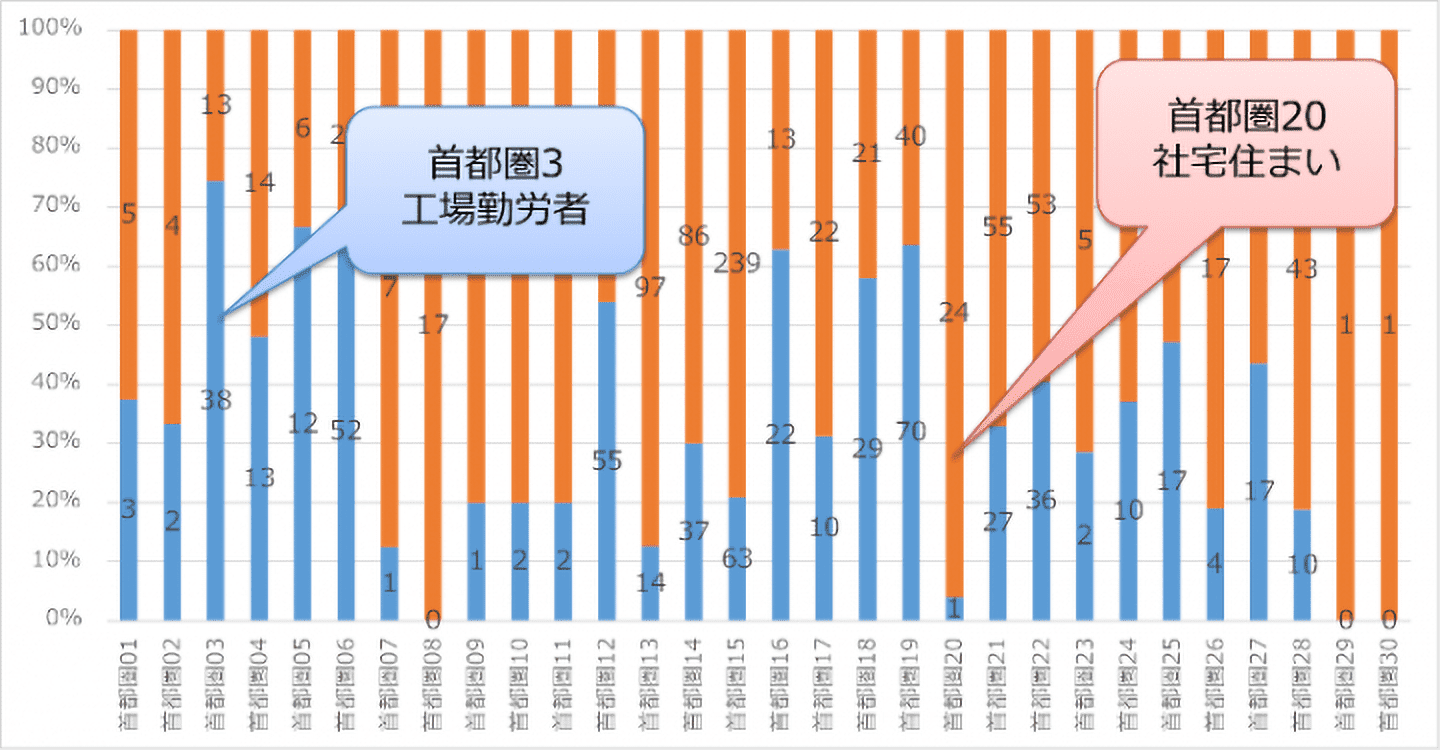
【図8:コメダ珈琲(オレンジ)とスターバックス(青) 】
縦軸は店舗数ではなく、両社の店舗数を100とした場合の構成比を示します。大きく違うところが幾つかありますが、「工場勤労者」と「社宅住まい」が目立ちます。「工場労働者」は人口総数の2.72%を占め、第2次産業に従事する人の割合が高く、子どもと20代~40代のニューファミリー世代が多く、年収は400万~500万の世帯が多いエリアです。
「社宅住まい」は、人口総数の0.69%を占め、文字通り社宅住まいが多く、若者単身世帯とニューファミリー世帯が混在しています。年収レベルはそれほど高くないですが、貯蓄レベルは高いという特徴があります。
■出店余地の検討
例として「社宅住まい」のエリアはどこにあるかを地図で表示しました。図9の赤い地域が該当します。この地図に既存店を重ねあわせ、未開拓エリアを見つけ出し、物件を探していくという方法もあるかと思います。
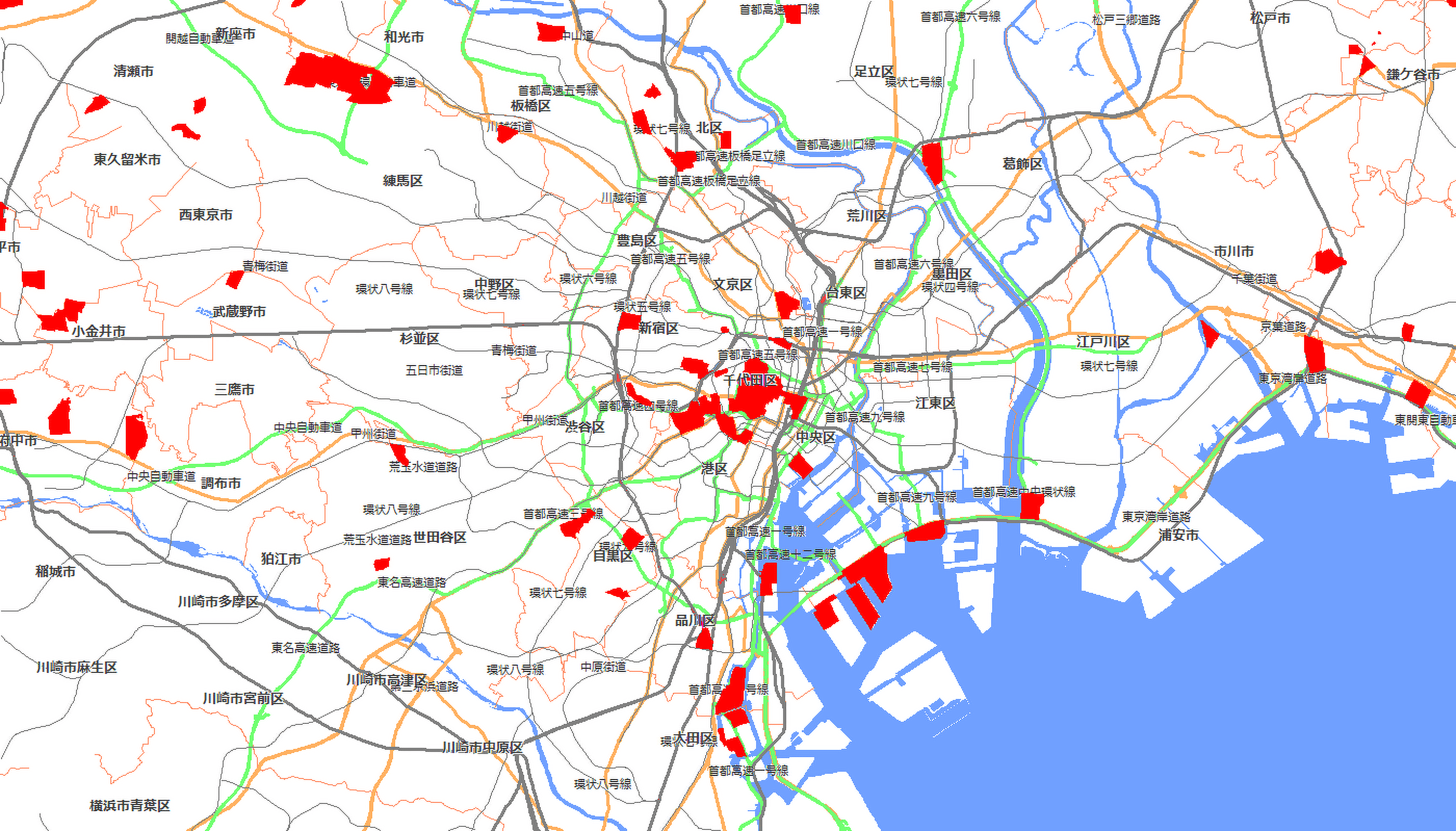
【図9:「社宅住まい」エリア 】
5.最後に
チェーン店舗における商圏分析は、自社の店舗データに商圏データを付与するところから始まります。そこから今回ご紹介した既存店や競合店の分析をはじめ、売上と商圏データの相関分析、売上予測モデルの構築、店舗の棚割り最適化など様々な分析を展開することができ、多数の分析事例がございます。
弊社にはデータ分析やGISの運用に関して様々な経験とノウハウがあり、統計の知識だけではなく、実践的なビジネスマインドを持つスタッフが、高度・高速なツールを用いてお客様がご自身でマーケティングナレッジを蓄積する支援をしています。これから商圏分析を始める方、現状の分析に行き詰まっている方、お気軽にご相談ください。
